 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitch-Synchronous Single Frequency Filtering Spectrogram for Speech Emotion Recognition
Paper and Code
Aug 07, 2019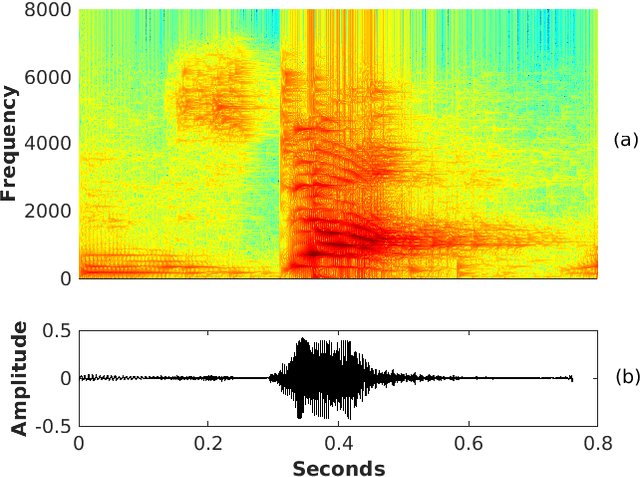
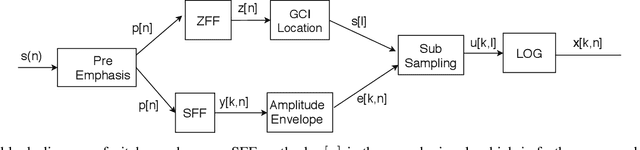
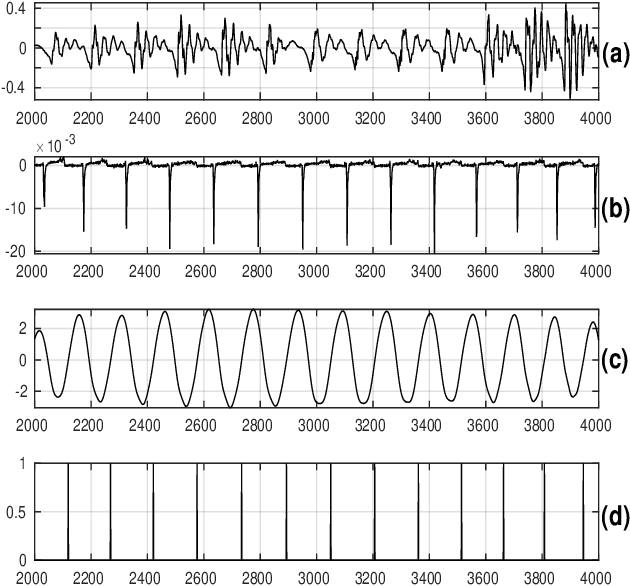
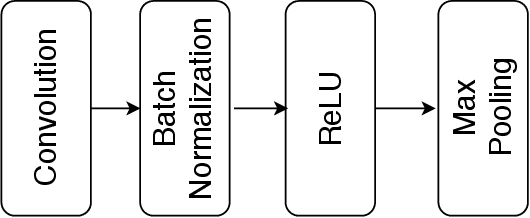
Convolutional neural networks (CNN) are widely used for speech emotion recognition (SER). In such cases, the short time fourier transform (STFT) spectrogram is the most popular choice for representing speech, which is fed as input to the CNN. However, the uncertainty principles of the short-time Fourier transform prevent it from capturing time and frequency resolutions simultaneously. On the other hand, the recently proposed single frequency filtering (SFF) spectrogram promises to be a better alternative because it captures both time and frequency resolutions simultaneously. In this work, we explore the SFF spectrogram as an alternative representation of speech for SER. We have modified the SFF spectrogram by taking the average of the amplitudes of all the samples between two successive glottal closure instants (GCI) locations. The duration between two successive GCI locations gives the pitch, motivating us to name the modified SFF spectrogram as pitch-synchronous SFF spectrogram. The GCI locations were detected using zero frequency filtering approach. The proposed pitch-synchronous SFF spectrogram produced accuracy values of 63.95% (unweighted) and 70.4% (weighted) on the IEMOCAP dataset. These correspond to an improvement of +7.35% (unweighted) and +4.3% (weighted) over state-of-the-art result on the STFT sepctrogram using CNN. Specially, the proposed method recognized 22.7% of the happy emotion samples correctly, whereas this number was 0% for state-of-the-art results. These results also promise a much wider use of the proposed pitch-synchronous SFF spectrogram for other speech-based applications.