 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistence Homology of TEDtalk: Do Sentence Embeddings Have a Topological Shape?
Mar 25, 2021
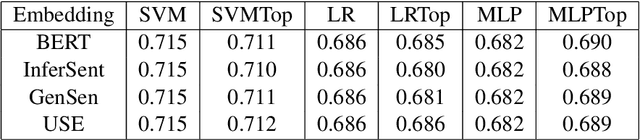
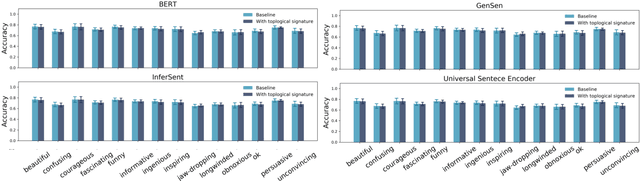
\emph{Topological data analysis} (TDA) has recently emerged as a new technique to extract meaningful discriminitve features from high dimensional data. In this paper, we investigate the possibility of applying TDA to improve the classification accuracy of public speaking rating. We calculated \emph{persistence image vectors} for the sentence embeddings of TEDtalk data and feed this vectors as additional inputs to our machine learning models. We have found a negative result that this topological information does not improve the model accuracy significantly. In some cases, it makes the accuracy slightly worse than the original one. From our results, we could not conclude that the topological shapes of the sentence embeddings can help us train a better model for public speaking rating.
Fairness in Rating Prediction by Awareness of Verbal and Gesture Quality of Public Speeches
Dec 16, 2020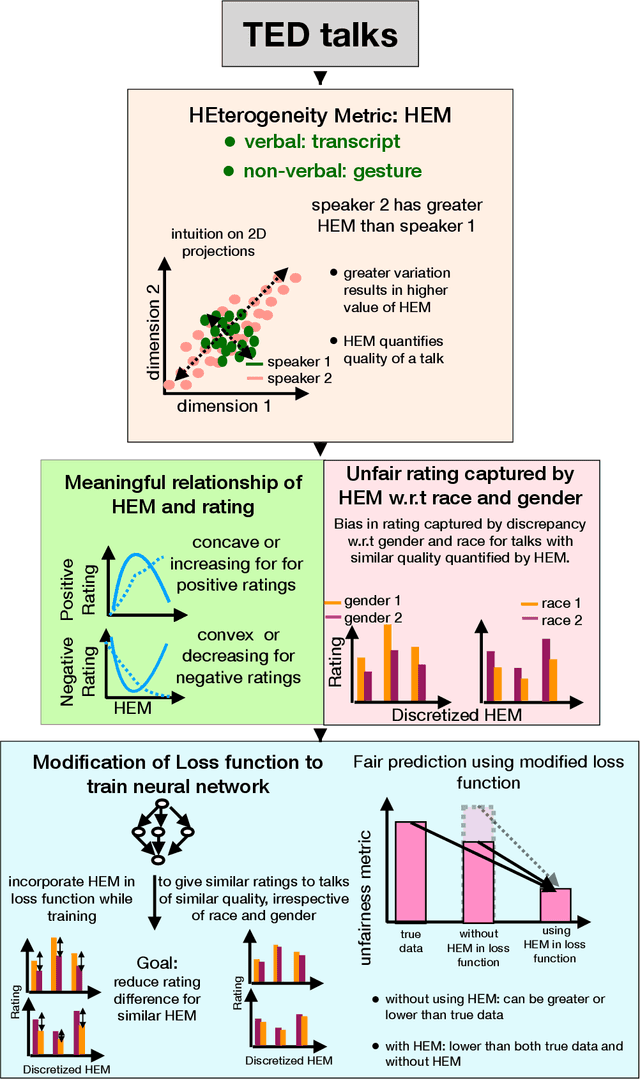


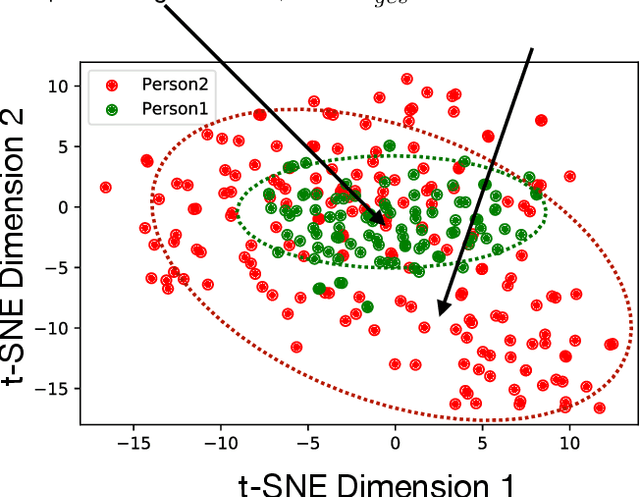
The role of verbal and non-verbal cues towards great public speaking has been a topic of exploration for many decades. We identify a commonality across present theories, the element of "variety or heterogeneity" in channels or modes of communication (e.g. resorting to stories, scientific facts, emotional connections, facial expressions etc.) which is essential for effectively communicating information. We use this observation to formalize a novel HEterogeneity Metric, HEM, that quantifies the quality of a talk both in the verbal and non-verbal domain (transcript and facial gestures). We use TED talks as an input repository of public speeches because it consists of speakers from a diverse community besides having a wide outreach. We show that there is an interesting relationship between HEM and the ratings of TED talks given to speakers by viewers. It emphasizes that HEM inherently and successfully represents the quality of a talk based on "variety or heterogeneity". Further, we also discover that HEM successfully captures the prevalent bias in ratings with respect to race and gender, that we call sensitive attributes (because prediction based on these might result in unfair outcome). We incorporate the HEM metric into the loss function of a neural network with the goal to reduce unfairness in rating predictions with respect to race and gender. Our results show that the modified loss function improves fairness in prediction without considerably affecting prediction accuracy of the neural network. Our work ties together a novel metric for public speeches in both verbal and non-verbal domain with the computational power of a neural network to design a fair prediction system for speakers.
Understanding Diversity based Pruning of Neural Networks -- Statistical Mechanical Analysis
Jun 30, 2020
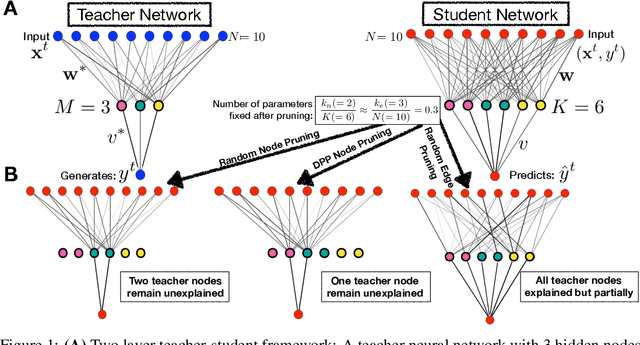
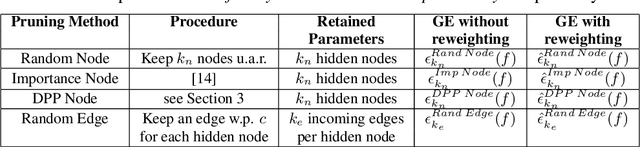

Deep learning architectures with a huge number of parameters are often compressed using pruning techniques to ensure computational efficiency of inference during deployment. Despite multitude of empirical advances, there is no theoretical understanding of the effectiveness of different pruning methods. We address this issue by setting up the problem in the statistical mechanics formulation of a teacher-student framework and deriving generalization error (GE) bounds of specific pruning methods. This theoretical premise allows comparison between pruning methods and we use it to investigate compression of neural networks via diversity-based pruning methods. A recent work showed that Determinantal Point Process (DPP) based node pruning method is notably superior to competing approaches when tested on real datasets. Using GE bounds in the aforementioned setup we provide theoretical guarantees for their empirical observations. Another consistent finding in literature is that sparse neural networks (edge pruned) generalize better than dense neural networks (node pruned) for a fixed number of parameters. We use our theoretical setup to prove that baseline random edge pruning method performs better than DPP node pruning method. Finally, we draw motivation from our theoretical results to propose a DPP edge pruning technique for neural networks which empirically outperforms other competing pruning methods on real datasets.
Detection and Mitigation of Bias in Ted Talk Ratings
Mar 02, 2020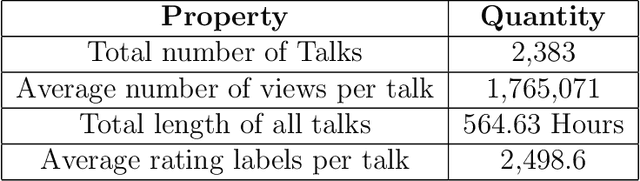
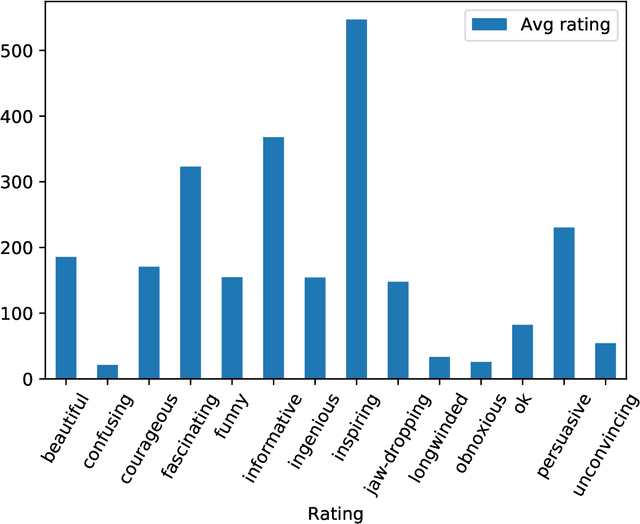

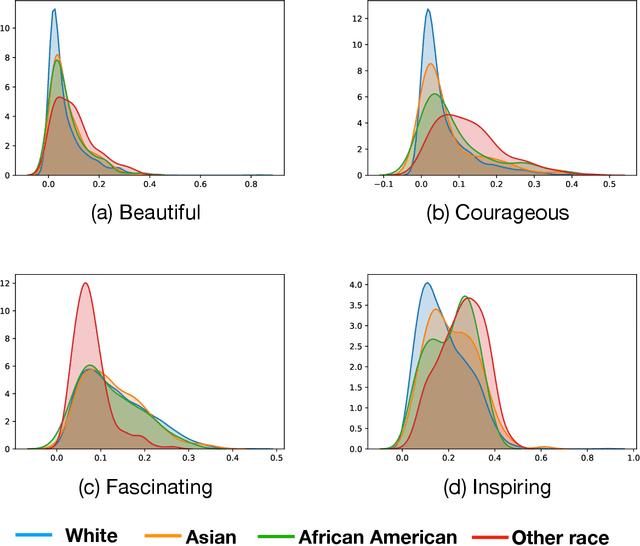
Unbiased data collection is essential to guaranteeing fairness in artificial intelligence models. Implicit bias, a form of behavioral conditioning that leads us to attribute predetermined characteristics to members of certain groups and informs the data collection process. This paper quantifies implicit bias in viewer ratings of TEDTalks, a diverse social platform assessing social and professional performance, in order to present the correlations of different kinds of bias across sensitive attributes. Although the viewer ratings of these videos should purely reflect the speaker's competence and skill, our analysis of the ratings demonstrates the presence of overwhelming and predominant implicit bias with respect to race and gender. In our paper, we present strategies to detect and mitigate bias that are critical to removing unfairness in AI.
FairyTED: A Fair Rating Predictor for TED Talk Data
Nov 25, 2019



With the recent trend of applying machine learning in every aspect of human life, it is important to incorporate fairness into the core of the predictive algorithms. We address the problem of predicting the quality of public speeches while being fair with respect to sensitive attributes of the speakers, e.g. gender and race. We use the TED talks as an input repository of public speeches because it consists of speakers from a diverse community and has a wide outreach. Utilizing the theories of Causal Models, Counterfactual Fairness and state-of-the-art neural language models, we propose a mathematical framework for fair prediction of the public speaking quality. We employ grounded assumptions to construct a causal model capturing how different attributes affect public speaking quality. This causal model contributes in generating counterfactual data to train a fair predictive model. Our framework is general enough to utilize any assumption within the causal model. Experimental results show that while prediction accuracy is comparable to recent work on this dataset, our predictions are counterfactually fair with respect to a novel metric when compared to true data labels. The FairyTED setup not only allows organizers to make informed and diverse selection of speakers from the unobserved counterfactual possibilities but it also ensures that viewers and new users are not influenced by unfair and unbalanced ratings from arbitrary visitors to the www.ted.com website when deciding to view a talk.