 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistence Homology of TEDtalk: Do Sentence Embeddings Have a Topological Shape?
Mar 25, 2021
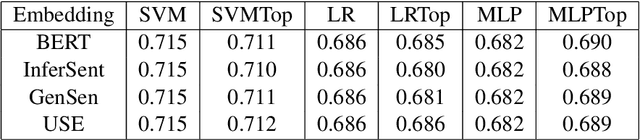
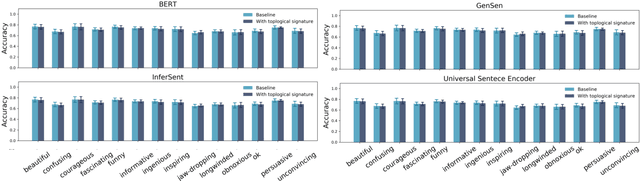
\emph{Topological data analysis} (TDA) has recently emerged as a new technique to extract meaningful discriminitve features from high dimensional data. In this paper, we investigate the possibility of applying TDA to improve the classification accuracy of public speaking rating. We calculated \emph{persistence image vectors} for the sentence embeddings of TEDtalk data and feed this vectors as additional inputs to our machine learning models. We have found a negative result that this topological information does not improve the model accuracy significantly. In some cases, it makes the accuracy slightly worse than the original one. From our results, we could not conclude that the topological shapes of the sentence embeddings can help us train a better model for public speaking rating.