 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Rating Prediction by Awareness of Verbal and Gesture Quality of Public Speeches
Paper and Code
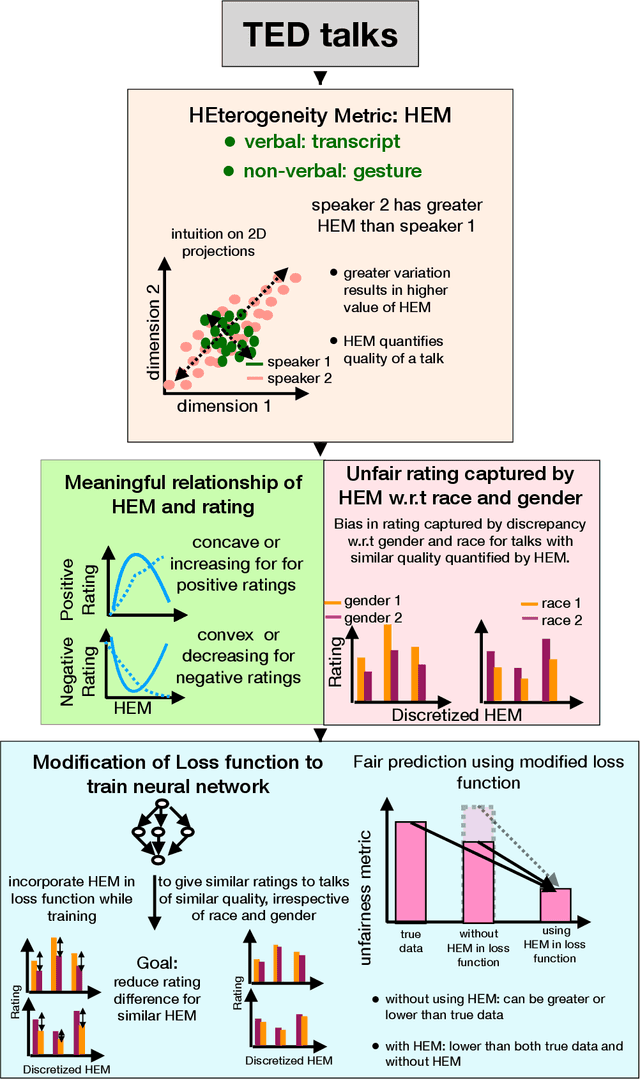


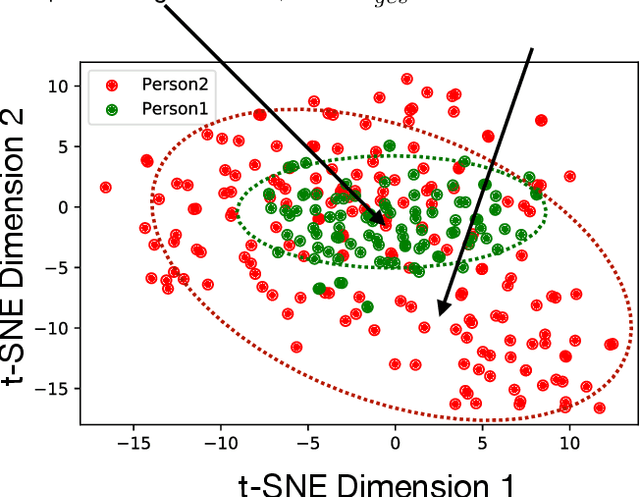
The role of verbal and non-verbal cues towards great public speaking has been a topic of exploration for many decades. We identify a commonality across present theories, the element of "variety or heterogeneity" in channels or modes of communication (e.g. resorting to stories, scientific facts, emotional connections, facial expressions etc.) which is essential for effectively communicating information. We use this observation to formalize a novel HEterogeneity Metric, HEM, that quantifies the quality of a talk both in the verbal and non-verbal domain (transcript and facial gestures). We use TED talks as an input repository of public speeches because it consists of speakers from a diverse community besides having a wide outreach. We show that there is an interesting relationship between HEM and the ratings of TED talks given to speakers by viewers. It emphasizes that HEM inherently and successfully represents the quality of a talk based on "variety or heterogeneity". Further, we also discover that HEM successfully captures the prevalent bias in ratings with respect to race and gender, that we call sensitive attributes (because prediction based on these might result in unfair outcome). We incorporate the HEM metric into the loss function of a neural network with the goal to reduce unfairness in rating predictions with respect to race and gender. Our results show that the modified loss function improves fairness in prediction without considerably affecting prediction accuracy of the neural network. Our work ties together a novel metric for public speeches in both verbal and non-verbal domain with the computational power of a neural network to design a fair prediction system for speakers.