 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfy: Interpretable Visualization of Expertise-Dependent Motor Skills Toward Supporting Piano Practice
Jun 09, 2026The quality of piano performance depends on nuanced timing, articulation, and dynamic control, but practice feedback is often summary-based and hard to act on. We introduce Profy, a weakly supervised system that learns from take-level labels derived from aggregated listener ratings (expert-labeled vs. amateur-labeled) to produce time-aligned highlights for review during piano practice. We collected synchronized 1 kHz key-motion and audio from 73 pianists and used 1,083 valid takes for modeling and evaluation. The model outputs clip-level predictions together with evidence scores on a shared resampled model time base for visualization. On 20 amateur clips from short technique studies annotated by 21 expert pianists, the displayed highlight score aligns with passages that expert pianists marked for review despite training without localized labels (Pearson r=0.61, ROC-AUC 0.75). Rather than summarizing a take with a single global score, Profy helps learners decide where to inspect next by supporting scrubbing, looping, and focused replay of time-localized passages associated with expert-amateur differences.
Inferring trust in recommendation systems from brain, behavioural, and physiological data
Oct 31, 2025As people nowadays increasingly rely on artificial intelligence (AI) to curate information and make decisions, assigning the appropriate amount of trust in automated intelligent systems has become ever more important. However, current measurements of trust in automation still largely rely on self-reports that are subjective and disruptive to the user. Here, we take music recommendation as a model to investigate the neural and cognitive processes underlying trust in automation. We observed that system accuracy was directly related to users' trust and modulated the influence of recommendation cues on music preference. Modelling users' reward encoding process with a reinforcement learning model further revealed that system accuracy, expected reward, and prediction error were related to oscillatory neural activity recorded via EEG and changes in pupil diameter. Our results provide a neurally grounded account of calibrating trust in automation and highlight the promises of a multimodal approach towards developing trustable AI systems.
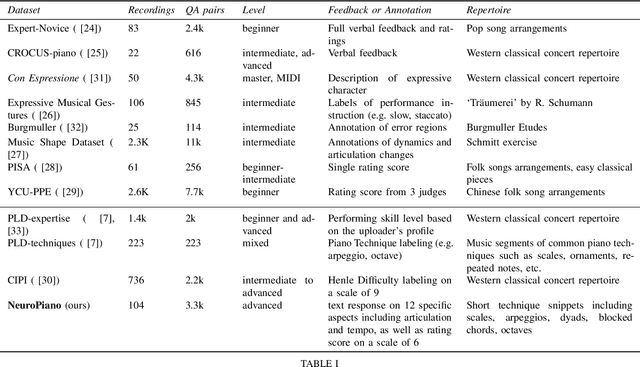
How does the teacher rate? Observations from the NeuroPiano dataset
Oct 04, 2024This paper provides a detailed analysis of the NeuroPiano dataset, which comprise 104 audio recordings of student piano performances accompanied with 2255 textual feedback and ratings given by professional pianists. We offer a statistical overview of the dataset, focusing on the standardization of annotations and inter-annotator agreement across 12 evaluative questions concerning performance quality. We also explore the predictive relationship between audio features and teacher ratings via machine learning, as well as annotations provided for text analysis of the responses.
LLaQo: Towards a Query-Based Coach in Expressive Music Performance Assessment
Sep 16, 2024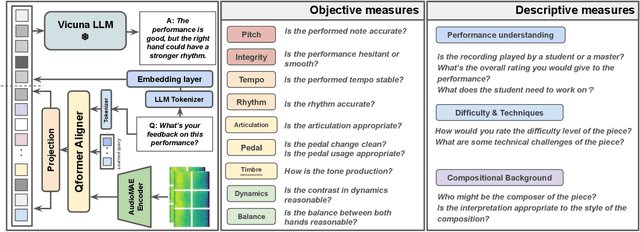
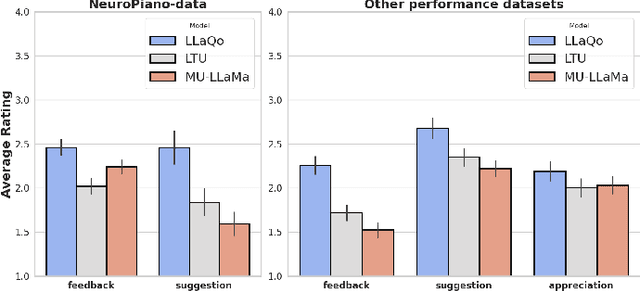

Research in music understanding has extensively explored composition-level attributes such as key, genre, and instrumentation through advanced representations, leading to cross-modal applications using large language models. However, aspects of musical performance such as stylistic expression and technique remain underexplored, along with the potential of using large language models to enhance educational outcomes with customized feedback. To bridge this gap, we introduce LLaQo, a Large Language Query-based music coach that leverages audio language modeling to provide detailed and formative assessments of music performances. We also introduce instruction-tuned query-response datasets that cover a variety of performance dimensions from pitch accuracy to articulation, as well as contextual performance understanding (such as difficulty and performance techniques). Utilizing AudioMAE encoder and Vicuna-7b LLM backend, our model achieved state-of-the-art (SOTA) results in predicting teachers' performance ratings, as well as in identifying piece difficulty and playing techniques. Textual responses from LLaQo was moreover rated significantly higher compared to other baseline models in a user study using audio-text matching. Our proposed model can thus provide informative answers to open-ended questions related to musical performance from audio data.