 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does the teacher rate? Observations from the NeuroPiano dataset
Oct 04, 2024This paper provides a detailed analysis of the NeuroPiano dataset, which comprise 104 audio recordings of student piano performances accompanied with 2255 textual feedback and ratings given by professional pianists. We offer a statistical overview of the dataset, focusing on the standardization of annotations and inter-annotator agreement across 12 evaluative questions concerning performance quality. We also explore the predictive relationship between audio features and teacher ratings via machine learning, as well as annotations provided for text analysis of the responses.
LLaQo: Towards a Query-Based Coach in Expressive Music Performance Assessment
Sep 16, 2024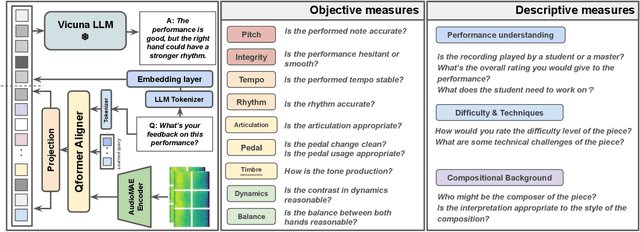
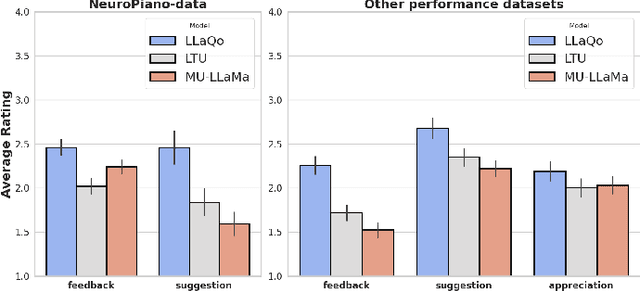

Research in music understanding has extensively explored composition-level attributes such as key, genre, and instrumentation through advanced representations, leading to cross-modal applications using large language models. However, aspects of musical performance such as stylistic expression and technique remain underexplored, along with the potential of using large language models to enhance educational outcomes with customized feedback. To bridge this gap, we introduce LLaQo, a Large Language Query-based music coach that leverages audio language modeling to provide detailed and formative assessments of music performances. We also introduce instruction-tuned query-response datasets that cover a variety of performance dimensions from pitch accuracy to articulation, as well as contextual performance understanding (such as difficulty and performance techniques). Utilizing AudioMAE encoder and Vicuna-7b LLM backend, our model achieved state-of-the-art (SOTA) results in predicting teachers' performance ratings, as well as in identifying piece difficulty and playing techniques. Textual responses from LLaQo was moreover rated significantly higher compared to other baseline models in a user study using audio-text matching. Our proposed model can thus provide informative answers to open-ended questions related to musical performance from audio data.
Matrix Tile Analysis
Jun 27, 2012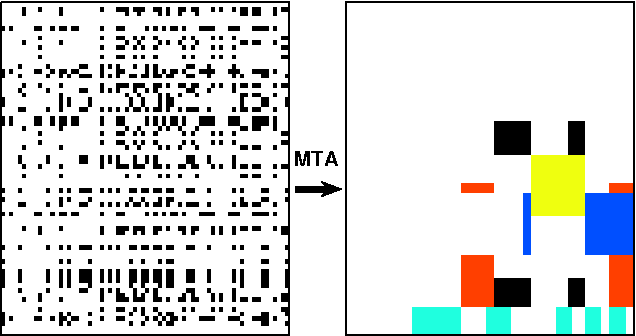
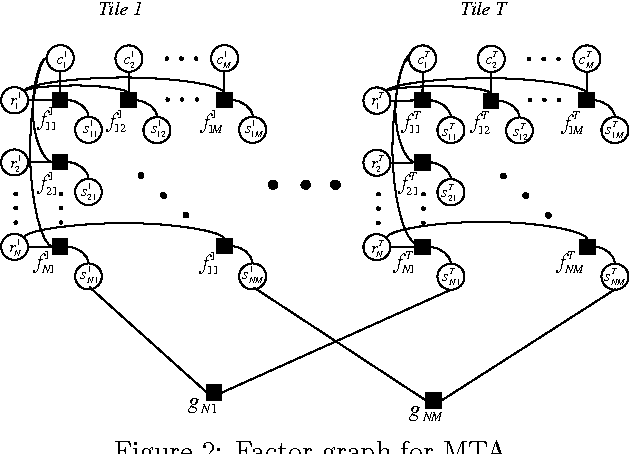
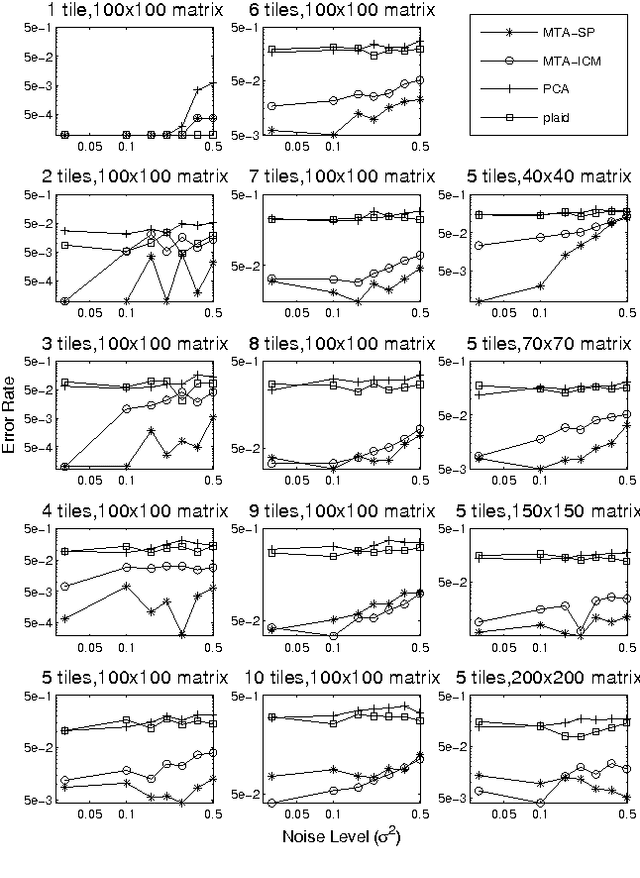

Many tasks require finding groups of elements in a matrix of numbers, symbols or class likelihoods. One approach is to use efficient bi- or tri-linear factorization techniques including PCA, ICA, sparse matrix factorization and plaid analysis. These techniques are not appropriate when addition and multiplication of matrix elements are not sensibly defined. More directly, methods like bi-clustering can be used to classify matrix elements, but these methods make the overly-restrictive assumption that the class of each element is a function of a row class and a column class. We introduce a general computational problem, `matrix tile analysis' (MTA), which consists of decomposing a matrix into a set of non-overlapping tiles, each of which is defined by a subset of usually nonadjacent rows and columns. MTA does not require an algebra for combining tiles, but must search over discrete combinations of tile assignments. Exact MTA is a computationally intractable integer programming problem, but we describe an approximate iterative technique and a computationally efficient sum-product relaxation of the integer program. We compare the effectiveness of these methods to PCA and plaid on hundreds of randomly generated tasks. Using double-gene-knockout data, we show that MTA finds groups of interacting yeast genes that have biologically-related functions.