 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Compressed Repetitive Gapped Sequential Patterns Efficiently
Jun 04, 2009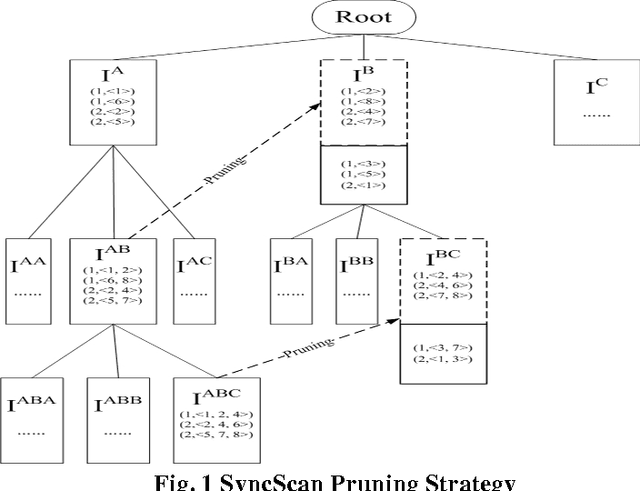

Mining frequent sequential patterns from sequence databases has been a central research topic in data mining and various efficient mining sequential patterns algorithms have been proposed and studied. Recently, in many problem domains (e.g, program execution traces), a novel sequential pattern mining research, called mining repetitive gapped sequential patterns, has attracted the attention of many researchers, considering not only the repetition of sequential pattern in different sequences but also the repetition within a sequence is more meaningful than the general sequential pattern mining which only captures occurrences in different sequences. However, the number of repetitive gapped sequential patterns generated by even these closed mining algorithms may be too large to understand for users, especially when support threshold is low. In this paper, we propose and study the problem of compressing repetitive gapped sequential patterns. Inspired by the ideas of summarizing frequent itemsets, RPglobal, we develop an algorithm, CRGSgrow (Compressing Repetitive Gapped Sequential pattern grow), including an efficient pruning strategy, SyncScan, and an efficient representative pattern checking scheme, -dominate sequential pattern checking. The CRGSgrow is a two-step approach: in the first step, we obtain all closed repetitive sequential patterns as the candidate set of representative repetitive sequential patterns, and at the same time get the most of representative repetitive sequential patterns; in the second step, we only spend a little time in finding the remaining the representative patterns from the candidate set. An empirical study with both real and synthetic data sets clearly shows that the CRGSgrow has good performance.
* 19 pages, 7 figures
When to Update the sequential patterns of stream data?
Jan 26, 2003
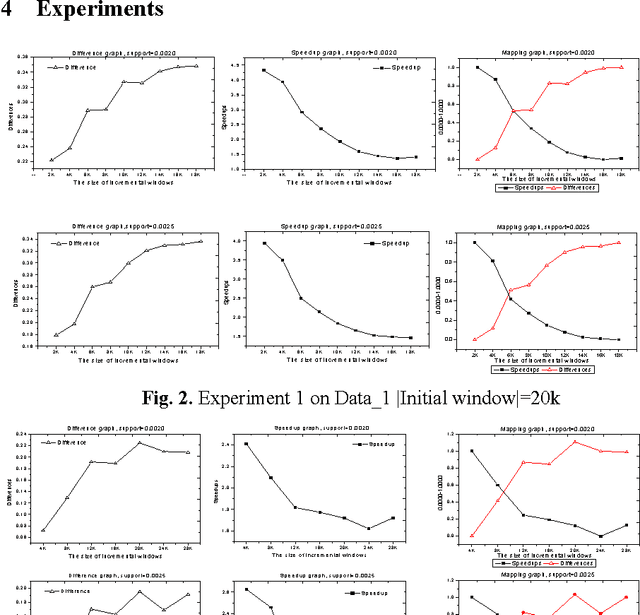
In this paper, we first define a difference measure between the old and new sequential patterns of stream data, which is proved to be a distance. Then we propose an experimental method, called TPD (Tradeoff between Performance and Difference), to decide when to update the sequential patterns of stream data by making a tradeoff between the performance of increasingly updating algorithms and the difference of sequential patterns. The experiments for the incremental updating algorithm IUS on two data sets show that generally, as the size of incremental windows grows, the values of the speedup and the values of the difference will decrease and increase respectively. It is also shown experimentally that the incremental ratio determined by the TPD method does not monotonically increase or decrease but changes in a range between 20 and 30 percentage for the IUS algorithm.
The Prioritized Inductive Logic Programs
Jun 10, 2002The limit behavior of inductive logic programs has not been explored, but when considering incremental or online inductive learning algorithms which usually run ongoingly, such behavior of the programs should be taken into account. An example is given to show that some inductive learning algorithm may not be correct in the long run if the limit behavior is not considered. An inductive logic program is convergent if given an increasing sequence of example sets, the program produces a corresponding sequence of the Horn logic programs which has the set-theoretic limit, and is limit-correct if the limit of the produced sequence of the Horn logic programs is correct with respect to the limit of the sequence of the example sets. It is shown that the GOLEM system is not limit-correct. Finally, a limit-correct inductive logic system, called the prioritized GOLEM system, is proposed as a solution.
Intelligent Search of Correlated Alarms for GSM Networks with Model-based Constraints
Apr 29, 2002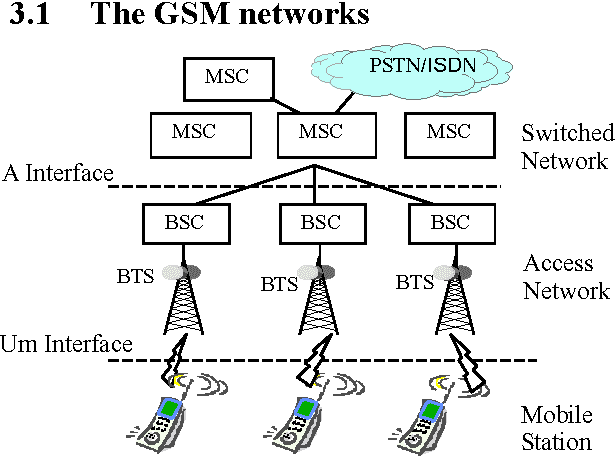

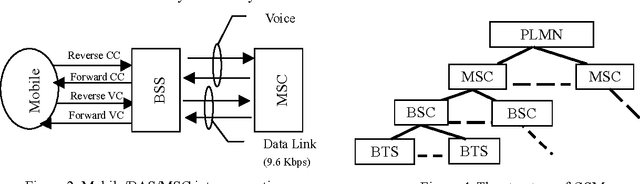
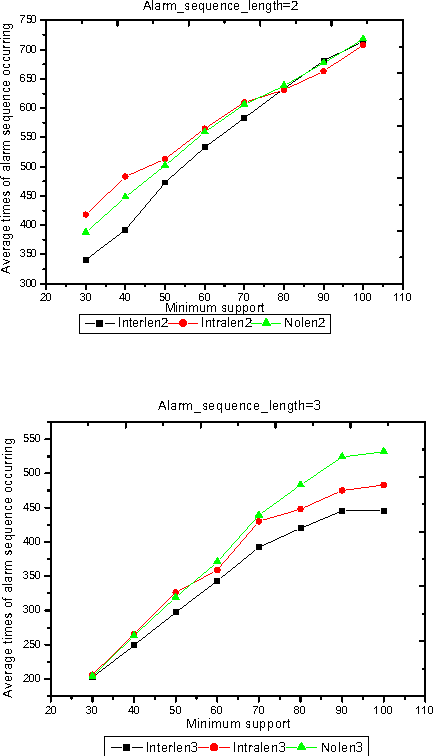
In order to control the process of data mining and focus on the things of interest to us, many kinds of constraints have been added into the algorithms of data mining. However, discovering the correlated alarms in the alarm database needs deep domain constraints. Because the correlated alarms greatly depend on the logical and physical architecture of networks. Thus we use the network model as the constraints of algorithms, including Scope constraint, Inter-correlated constraint and Intra-correlated constraint, in our proposed algorithm called SMC (Search with Model-based Constraints). The experiments show that the SMC algorithm with Inter-correlated or Intra-correlated constraint is about two times faster than the algorithm with no constraints.
* 8 pages, 7 figures
The Algorithms of Updating Sequential Patterns
Mar 27, 2002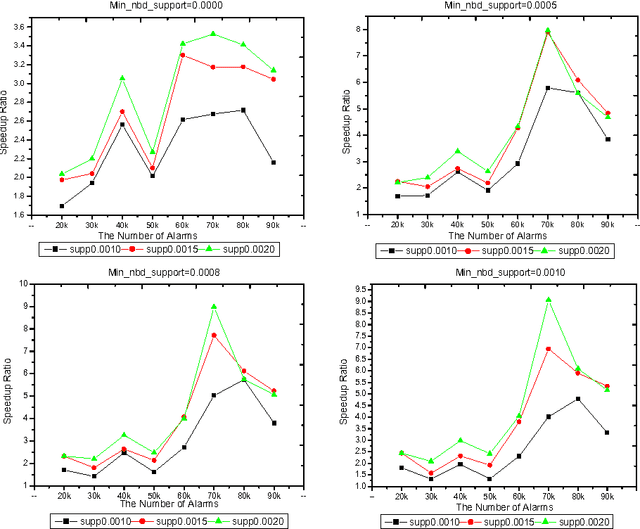
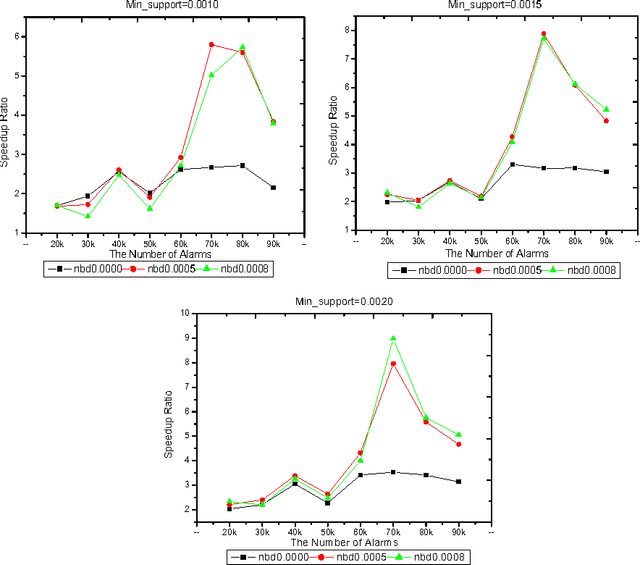
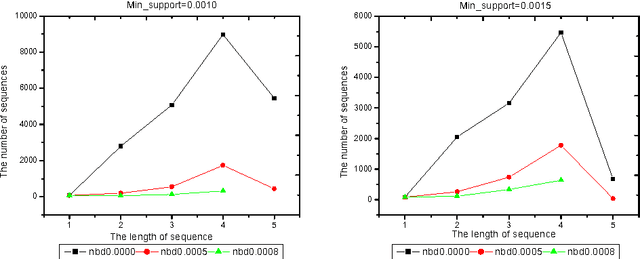
Because the data being mined in the temporal database will evolve with time, many researchers have focused on the incremental mining of frequent sequences in temporal database. In this paper, we propose an algorithm called IUS, using the frequent and negative border sequences in the original database for incremental sequence mining. To deal with the case where some data need to be updated from the original database, we present an algorithm called DUS to maintain sequential patterns in the updated database. We also define the negative border sequence threshold: Min_nbd_supp to control the number of sequences in the negative border.
* 12 pages, 4 figures
Intelligent Search of Correlated Alarms from Database containing Noise Data
Dec 26, 2001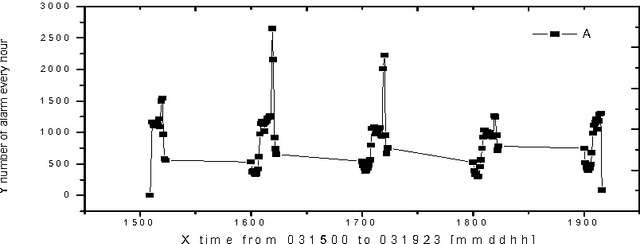
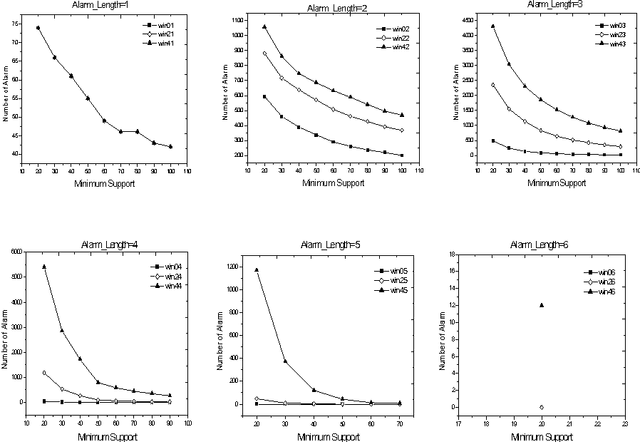
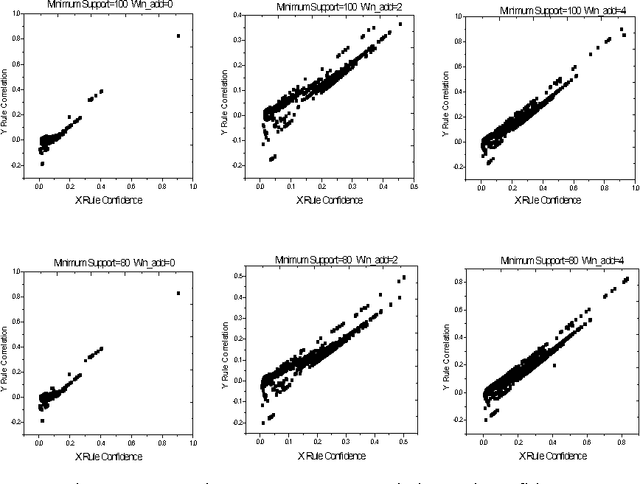
Alarm correlation plays an important role in improving the service and reliability in modern telecommunications networks. Most previous research of alarm correlation didn't consider the effect of noise data in Database. This paper focuses on the method of discovering alarm correlation rules from database containing noise data. We firstly define two parameters Win_freq and Win_add as the measure of noise data and then present the Robust_search algorithm to solve the problem. At different size of Win_freq and Win_add, experiments with alarm data containing noise data show that the Robust_search Algorithm can discover the more rules with the bigger size of Win_add. We also experimentally compare two different interestingness measures of confidence and correlation.