 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Compressed Repetitive Gapped Sequential Patterns Efficiently
Paper and Code
Jun 04, 2009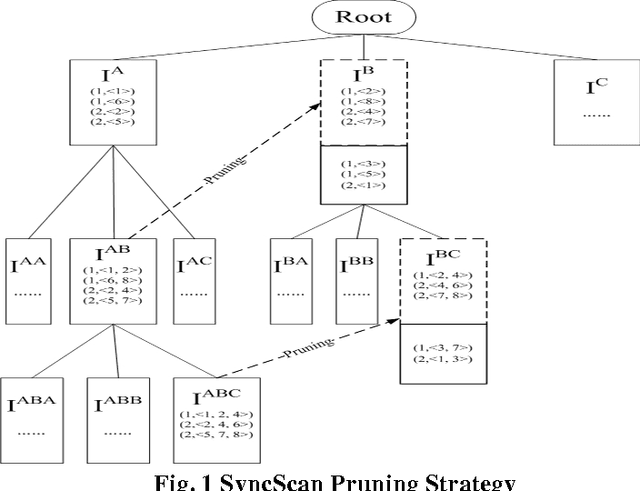

Mining frequent sequential patterns from sequence databases has been a central research topic in data mining and various efficient mining sequential patterns algorithms have been proposed and studied. Recently, in many problem domains (e.g, program execution traces), a novel sequential pattern mining research, called mining repetitive gapped sequential patterns, has attracted the attention of many researchers, considering not only the repetition of sequential pattern in different sequences but also the repetition within a sequence is more meaningful than the general sequential pattern mining which only captures occurrences in different sequences. However, the number of repetitive gapped sequential patterns generated by even these closed mining algorithms may be too large to understand for users, especially when support threshold is low. In this paper, we propose and study the problem of compressing repetitive gapped sequential patterns. Inspired by the ideas of summarizing frequent itemsets, RPglobal, we develop an algorithm, CRGSgrow (Compressing Repetitive Gapped Sequential pattern grow), including an efficient pruning strategy, SyncScan, and an efficient representative pattern checking scheme, -dominate sequential pattern checking. The CRGSgrow is a two-step approach: in the first step, we obtain all closed repetitive sequential patterns as the candidate set of representative repetitive sequential patterns, and at the same time get the most of representative repetitive sequential patterns; in the second step, we only spend a little time in finding the remaining the representative patterns from the candidate set. An empirical study with both real and synthetic data sets clearly shows that the CRGSgrow has good performance.