 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement-Adapted Eigentask Representations for Photon-Limited Optical Readout
May 11, 2026Optical readout in low-light imaging is fundamentally limited by measurement noise, including photon shot noise, detector noise, and quantization error. In this regime, downstream inference depends not only on the optical front end, but also on how noisy high-dimensional sensor measurements are represented before classification or decision-making. Here we show that eigentasks provide a measurement-adapted representation for optical sensor outputs by ordering readout features according to their resolvability under noise. Using experimental data from a lens-based optical imaging system and a reanalysis of published data from a single-photon-detection neural network, we find that eigentask representations frequently outperform standard baselines including principal component analysis and filtering-based compression. The advantage is most pronounced in photon-limited, few-shot, and higher-difficulty classification regimes. In few-shot MPEG-7 classification, for example, the advantage over other methods reaches about 10 percentage points as the number of classes increases. In these settings, eigentasks yield more informative low-dimensional features and improve sample-efficient downstream learning. These results identify measurement-adapted representation as a promising strategy for optical inference when photon budget, acquisition time, and task complexity are constrained.
Ultra-low-light computer vision using trained photon correlations
Apr 13, 2026Illumination using correlated photon sources has been established as an approach to allowing high-fidelity images to be reconstructed from noisy camera frames by taking advantage of the knowledge that signal photons are spatially correlated whereas detector clicks due to noise are uncorrelated. However, in computer-vision tasks, the goal is often not ultimately to reconstruct an image, but to make inferences about a scene -- such as what object is present. Here we show how correlated-photon illumination can be used to gain an advantage in a hybrid optical-electronic computer-vision pipeline for object recognition. We demonstrate correlation-aware training (CAT): end-to-end optimization of a trainable correlated-photon illumination source and a Transformer backend in a way that the Transformer can learn to benefit from the correlations, using a small number (<= 100) of shots. We show a classification accuracy enhancement of up to 15 percentage points over conventional, uncorrelated-illumination-based computer vision in ultra-low-light and noisy imaging conditions, as well as an improvement over using untrained correlated-photon illumination. Our work illustrates how specializing to a computer-vision task -- object recognition -- and training the pattern of photon correlations in conjunction with a digital backend allows us to push the limits of accuracy in highly photon-budget-constrained scenarios beyond existing methods focused on image reconstruction.
Machine vision with small numbers of detected photons per inference
Mar 25, 2026Machine vision, including object recognition and image reconstruction, is a central technology in many consumer devices and scientific instruments. The design of machine-vision systems has been revolutionized by the adoption of end-to-end optimization, in which the optical front end and the post-processing back end are jointly optimized. However, while machine vision currently works extremely well in moderate-light or bright-light situations -- where a camera may detect thousands of photons per pixel and billions of photons per frame -- it is far more challenging in very low-light situations. We introduce photon-aware neuromorphic sensing (PANS), an approach for end-to-end optimization in highly photon-starved scenarios. The training incorporates knowledge of the low photon budget and the stochastic nature of light detection when the average number of photons per pixel is near or less than 1. We report a proof-of-principle experimental demonstration in which we performed low-light image classification using PANS, achieving 73% (82%) accuracy on FashionMNIST with an average of only 4.9 (17) detected photons in total per inference, and 86% (97%) on MNIST with 8.6 (29) detected photons -- orders of magnitude more photon-efficient than conventional approaches. We also report simulation studies showing how PANS could be applied to other classification, event-detection, and image-reconstruction tasks. By taking into account the statistics of measurement results for non-classical states or alternative sensing hardware, PANS could in principle be adapted to enable high-accuracy results in quantum and other photon-starved setups.
Micro-Ring Perceptron Sensor for High-Speed, Low-Power Radio-Frequency Signal
Apr 19, 2025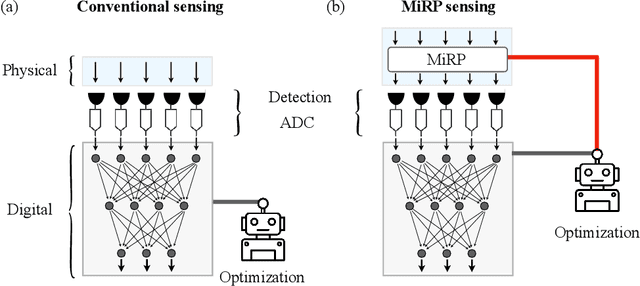
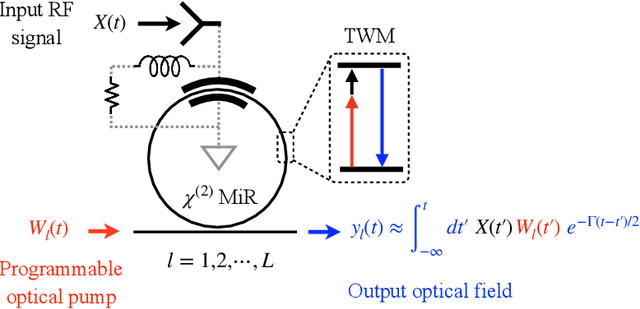
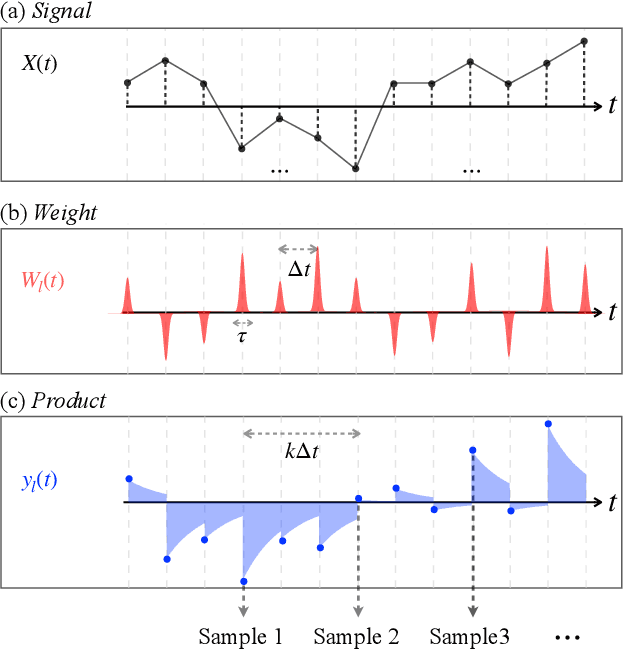
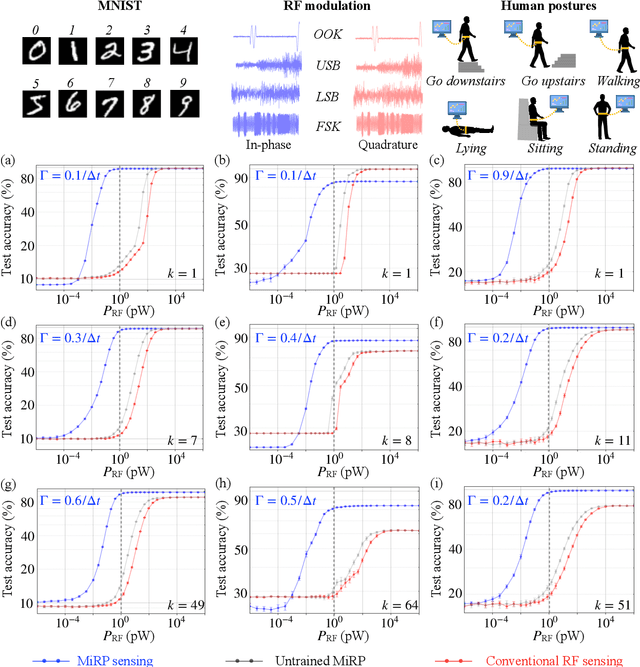
Radio-frequency (RF) sensing enables long-range, high-resolution detection for applications such as radar and wireless communication. RF photonic sensing mitigates the bandwidth limitations and high transmission losses of electronic systems by transducing the detected RF signals into broadband optical carriers. However, these sensing systems remain limited by detector noise and Nyquist rate sampling with analog-to-digital converters, particularly under low-power and high-data rate conditions. To overcome these limitations, we introduce the micro-ring perceptron (MiRP) sensor, a physics-inspired AI framework that integrates the micro-ring (MiR) dynamics-based analog processor with a machine-learning-driven digital backend. By embedding the nonlinear optical dynamics of MiRs into an end-to-end architecture, MiRP sensing maps the input signal into a learned feature space for the subsequent digital neural network. The trick is to encode the entire temporal structure of the incoming signal into each output sample in order to enable effectively sub-Nyquist sampling without loss of task-relevant information. Evaluations of three target classification datasets demonstrate the performance advantages of MiRP sensing. For example, on MNIST, MiRP detection achieves $94\pm0.1$\% accuracy at $1/49$ the Nyquist rate at the input RF signal of $1$~ pW, compared to $11\pm0.4$\% for the conventional RF detection method. Thus, our sensor framework provides a robust and efficient solution for the detection of low-power and high-speed signals in real-world sensing applications.
Quantum-noise-limited optical neural networks operating at a few quanta per activation
Jul 28, 2023



Analog physical neural networks, which hold promise for improved energy efficiency and speed compared to digital electronic neural networks, are nevertheless typically operated in a relatively high-power regime so that the signal-to-noise ratio (SNR) is large (>10). What happens if an analog system is instead operated in an ultra-low-power regime, in which the behavior of the system becomes highly stochastic and the noise is no longer a small perturbation on the signal? In this paper, we study this question in the setting of optical neural networks operated in the limit where some layers use only a single photon to cause a neuron activation. Neuron activations in this limit are dominated by quantum noise from the fundamentally probabilistic nature of single-photon detection of weak optical signals. We show that it is possible to train stochastic optical neural networks to perform deterministic image-classification tasks with high accuracy in spite of the extremely high noise (SNR ~ 1) by using a training procedure that directly models the stochastic behavior of photodetection. We experimentally demonstrated MNIST classification with a test accuracy of 98% using an optical neural network with a hidden layer operating in the single-photon regime; the optical energy used to perform the classification corresponds to 0.008 photons per multiply-accumulate (MAC) operation, which is equivalent to 0.003 attojoules of optical energy per MAC. Our experiment used >40x fewer photons per inference than previous state-of-the-art low-optical-energy demonstrations, to achieve the same accuracy of >90%. Our work shows that some extremely stochastic analog systems, including those operating in the limit where quantum noise dominates, can nevertheless be used as layers in neural networks that deterministically perform classification tasks with high accuracy if they are appropriately trained.
Optical Transformers
Feb 20, 2023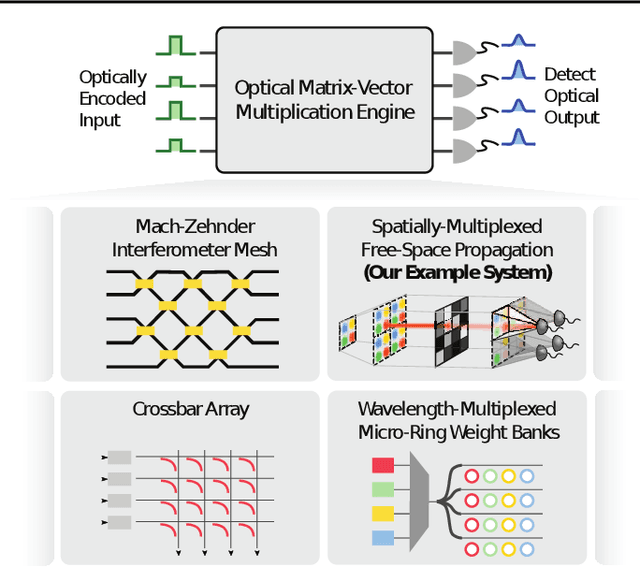
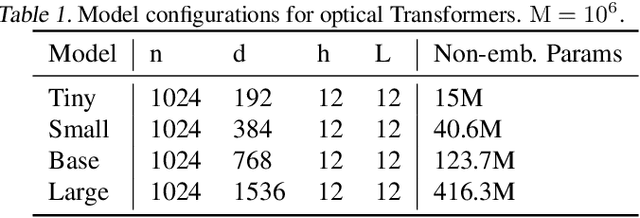
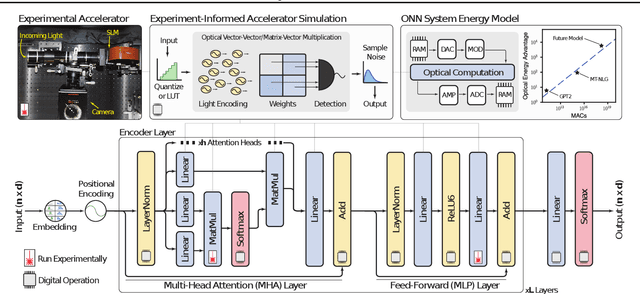

The rapidly increasing size of deep-learning models has caused renewed and growing interest in alternatives to digital computers to dramatically reduce the energy cost of running state-of-the-art neural networks. Optical matrix-vector multipliers are best suited to performing computations with very large operands, which suggests that large Transformer models could be a good target for optical computing. To test this idea, we performed small-scale optical experiments with a prototype accelerator to demonstrate that Transformer operations can run on optical hardware despite noise and errors. Using simulations, validated by our experiments, we then explored the energy efficiency of optical implementations of Transformers and identified scaling laws for model performance with respect to optical energy usage. We found that the optical energy per multiply-accumulate (MAC) scales as $\frac{1}{d}$ where $d$ is the Transformer width, an asymptotic advantage over digital systems. We conclude that with well-engineered, large-scale optical hardware, it may be possible to achieve a $100 \times$ energy-efficiency advantage for running some of the largest current Transformer models, and that if both the models and the optical hardware are scaled to the quadrillion-parameter regime, optical computers could have a $>8,000\times$ energy-efficiency advantage over state-of-the-art digital-electronic processors that achieve 300 fJ/MAC. We analyzed how these results motivate and inform the construction of future optical accelerators along with optics-amenable deep-learning approaches. With assumptions about future improvements to electronics and Transformer quantization techniques (5$\times$ cheaper memory access, double the digital--analog conversion efficiency, and 4-bit precision), we estimated that optical computers' advantage against current 300-fJ/MAC digital processors could grow to $>100,000\times$.
Image sensing with multilayer, nonlinear optical neural networks
Jul 27, 2022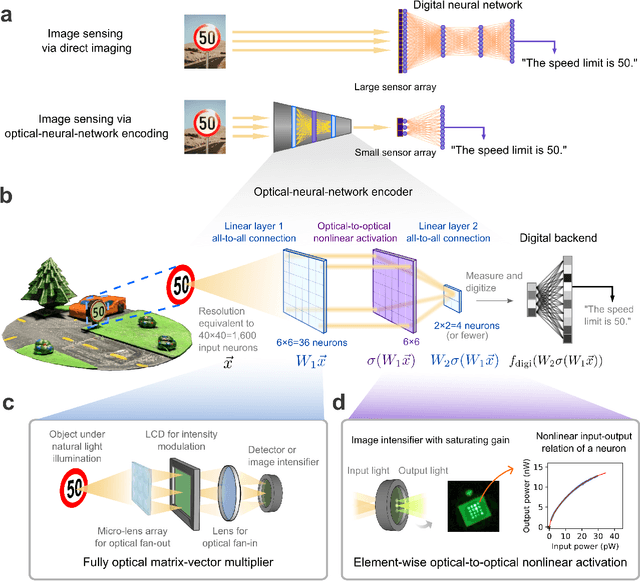
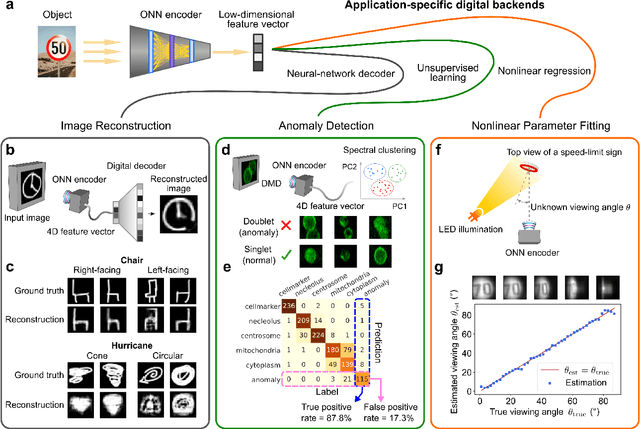
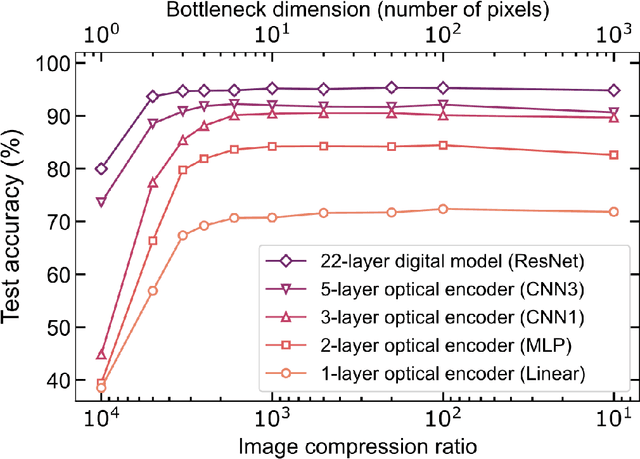

Optical imaging is commonly used for both scientific and technological applications across industry and academia. In image sensing, a measurement, such as of an object's position, is performed by computational analysis of a digitized image. An emerging image-sensing paradigm breaks this delineation between data collection and analysis by designing optical components to perform not imaging, but encoding. By optically encoding images into a compressed, low-dimensional latent space suitable for efficient post-analysis, these image sensors can operate with fewer pixels and fewer photons, allowing higher-throughput, lower-latency operation. Optical neural networks (ONNs) offer a platform for processing data in the analog, optical domain. ONN-based sensors have however been limited to linear processing, but nonlinearity is a prerequisite for depth, and multilayer NNs significantly outperform shallow NNs on many tasks. Here, we realize a multilayer ONN pre-processor for image sensing, using a commercial image intensifier as a parallel optoelectronic, optical-to-optical nonlinear activation function. We demonstrate that the nonlinear ONN pre-processor can achieve compression ratios of up to 800:1 while still enabling high accuracy across several representative computer-vision tasks, including machine-vision benchmarks, flow-cytometry image classification, and identification of objects in real scenes. In all cases we find that the ONN's nonlinearity and depth allowed it to outperform a purely linear ONN encoder. Although our experiments are specialized to ONN sensors for incoherent-light images, alternative ONN platforms should facilitate a range of ONN sensors. These ONN sensors may surpass conventional sensors by pre-processing optical information in spatial, temporal, and/or spectral dimensions, potentially with coherent and quantum qualities, all natively in the optical domain.
An optical neural network using less than 1 photon per multiplication
Apr 27, 2021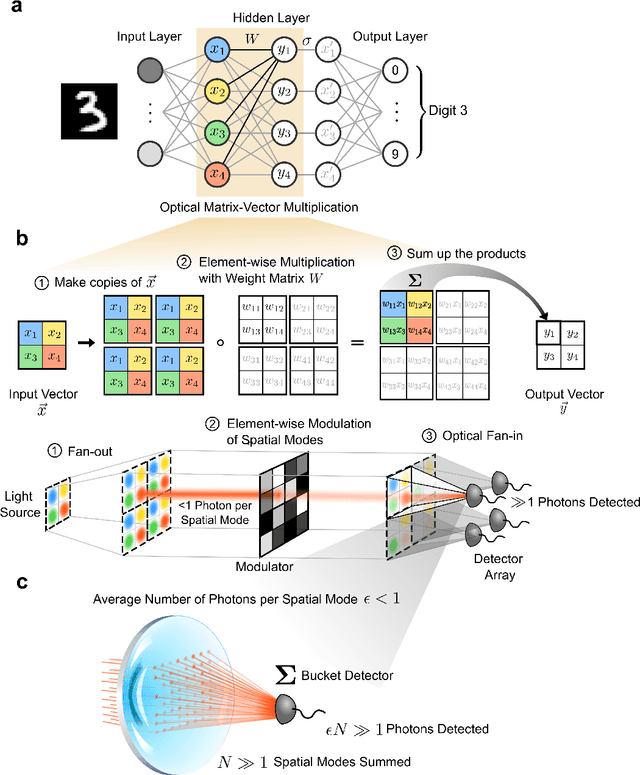
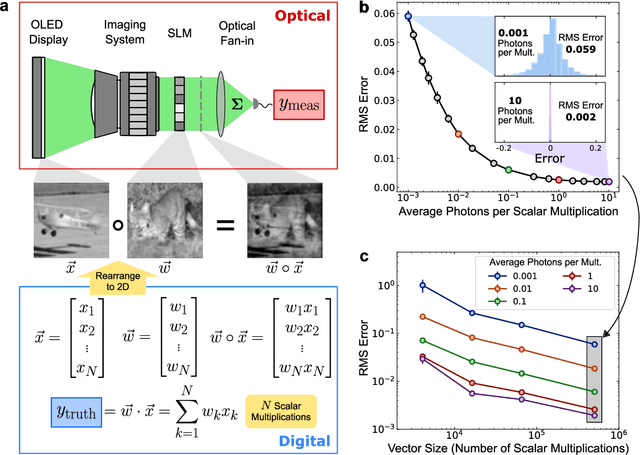
Deep learning has rapidly become a widespread tool in both scientific and commercial endeavors. Milestones of deep learning exceeding human performance have been achieved for a growing number of tasks over the past several years, across areas as diverse as game-playing, natural-language translation, and medical-image analysis. However, continued progress is increasingly hampered by the high energy costs associated with training and running deep neural networks on electronic processors. Optical neural networks have attracted attention as an alternative physical platform for deep learning, as it has been theoretically predicted that they can fundamentally achieve higher energy efficiency than neural networks deployed on conventional digital computers. Here, we experimentally demonstrate an optical neural network achieving 99% accuracy on handwritten-digit classification using ~3.2 detected photons per weight multiplication and ~90% accuracy using ~0.64 photons (~$2.4 \times 10^{-19}$ J of optical energy) per weight multiplication. This performance was achieved using a custom free-space optical processor that executes matrix-vector multiplications in a massively parallel fashion, with up to ~0.5 million scalar (weight) multiplications performed at the same time. Using commercially available optical components and standard neural-network training methods, we demonstrated that optical neural networks can operate near the standard quantum limit with extremely low optical powers and still achieve high accuracy. Our results provide a proof-of-principle for low-optical-power operation, and with careful system design including the surrounding electronics used for data storage and control, open up a path to realizing optical processors that require only $10^{-16}$ J total energy per scalar multiplication -- which is orders of magnitude more efficient than current digital processors.