 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Transformers
Paper and Code
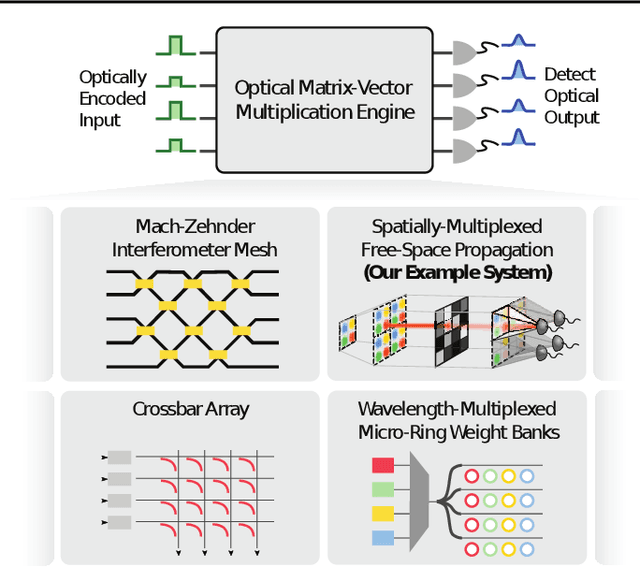
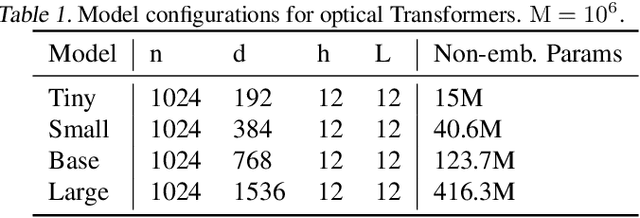
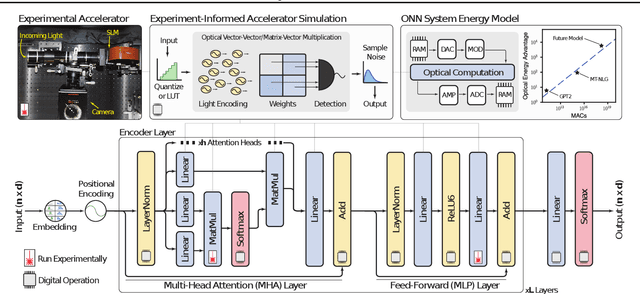

The rapidly increasing size of deep-learning models has caused renewed and growing interest in alternatives to digital computers to dramatically reduce the energy cost of running state-of-the-art neural networks. Optical matrix-vector multipliers are best suited to performing computations with very large operands, which suggests that large Transformer models could be a good target for optical computing. To test this idea, we performed small-scale optical experiments with a prototype accelerator to demonstrate that Transformer operations can run on optical hardware despite noise and errors. Using simulations, validated by our experiments, we then explored the energy efficiency of optical implementations of Transformers and identified scaling laws for model performance with respect to optical energy usage. We found that the optical energy per multiply-accumulate (MAC) scales as $\frac{1}{d}$ where $d$ is the Transformer width, an asymptotic advantage over digital systems. We conclude that with well-engineered, large-scale optical hardware, it may be possible to achieve a $100 \times$ energy-efficiency advantage for running some of the largest current Transformer models, and that if both the models and the optical hardware are scaled to the quadrillion-parameter regime, optical computers could have a $>8,000\times$ energy-efficiency advantage over state-of-the-art digital-electronic processors that achieve 300 fJ/MAC. We analyzed how these results motivate and inform the construction of future optical accelerators along with optics-amenable deep-learning approaches. With assumptions about future improvements to electronics and Transformer quantization techniques (5$\times$ cheaper memory access, double the digital--analog conversion efficiency, and 4-bit precision), we estimated that optical computers' advantage against current 300-fJ/MAC digital processors could grow to $>100,000\times$.