 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptical Transformers
Feb 20, 2023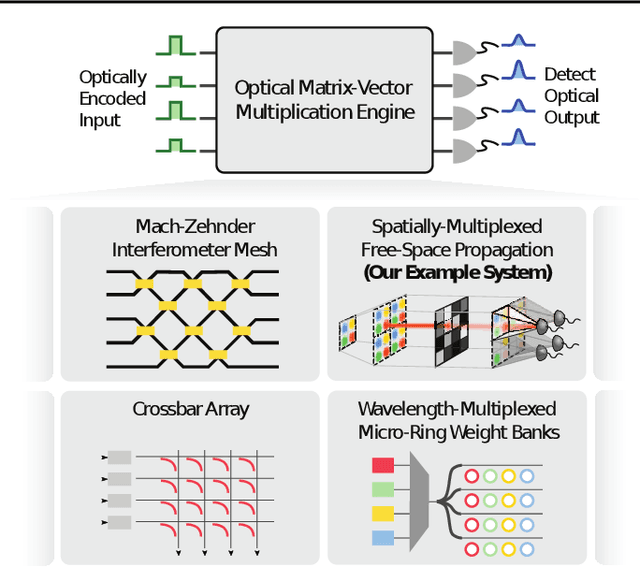
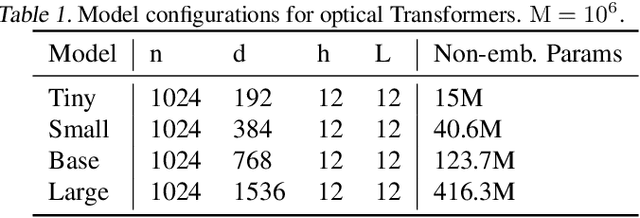
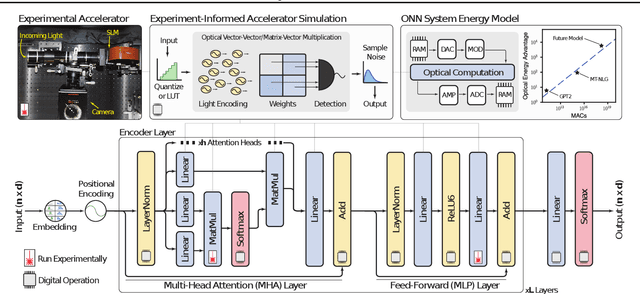

The rapidly increasing size of deep-learning models has caused renewed and growing interest in alternatives to digital computers to dramatically reduce the energy cost of running state-of-the-art neural networks. Optical matrix-vector multipliers are best suited to performing computations with very large operands, which suggests that large Transformer models could be a good target for optical computing. To test this idea, we performed small-scale optical experiments with a prototype accelerator to demonstrate that Transformer operations can run on optical hardware despite noise and errors. Using simulations, validated by our experiments, we then explored the energy efficiency of optical implementations of Transformers and identified scaling laws for model performance with respect to optical energy usage. We found that the optical energy per multiply-accumulate (MAC) scales as $\frac{1}{d}$ where $d$ is the Transformer width, an asymptotic advantage over digital systems. We conclude that with well-engineered, large-scale optical hardware, it may be possible to achieve a $100 \times$ energy-efficiency advantage for running some of the largest current Transformer models, and that if both the models and the optical hardware are scaled to the quadrillion-parameter regime, optical computers could have a $>8,000\times$ energy-efficiency advantage over state-of-the-art digital-electronic processors that achieve 300 fJ/MAC. We analyzed how these results motivate and inform the construction of future optical accelerators along with optics-amenable deep-learning approaches. With assumptions about future improvements to electronics and Transformer quantization techniques (5$\times$ cheaper memory access, double the digital--analog conversion efficiency, and 4-bit precision), we estimated that optical computers' advantage against current 300-fJ/MAC digital processors could grow to $>100,000\times$.
Image sensing with multilayer, nonlinear optical neural networks
Jul 27, 2022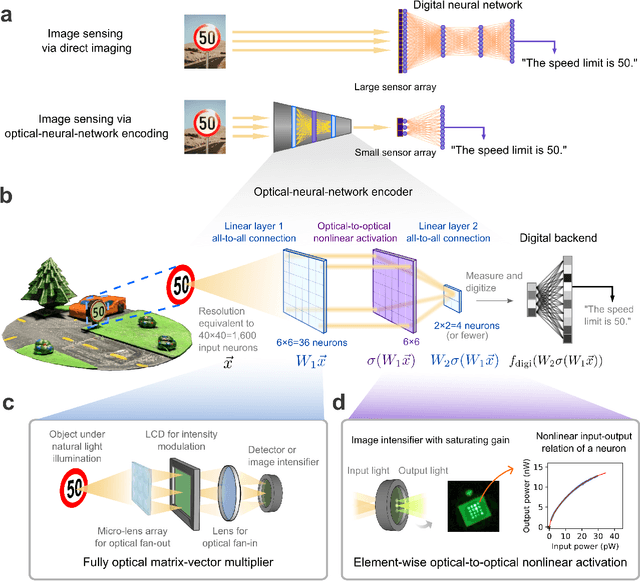
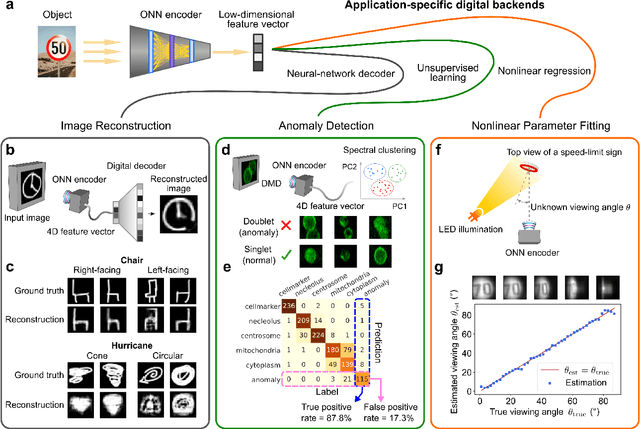
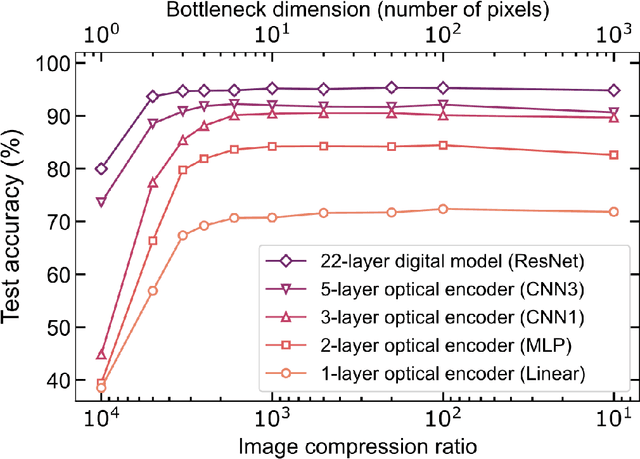

Optical imaging is commonly used for both scientific and technological applications across industry and academia. In image sensing, a measurement, such as of an object's position, is performed by computational analysis of a digitized image. An emerging image-sensing paradigm breaks this delineation between data collection and analysis by designing optical components to perform not imaging, but encoding. By optically encoding images into a compressed, low-dimensional latent space suitable for efficient post-analysis, these image sensors can operate with fewer pixels and fewer photons, allowing higher-throughput, lower-latency operation. Optical neural networks (ONNs) offer a platform for processing data in the analog, optical domain. ONN-based sensors have however been limited to linear processing, but nonlinearity is a prerequisite for depth, and multilayer NNs significantly outperform shallow NNs on many tasks. Here, we realize a multilayer ONN pre-processor for image sensing, using a commercial image intensifier as a parallel optoelectronic, optical-to-optical nonlinear activation function. We demonstrate that the nonlinear ONN pre-processor can achieve compression ratios of up to 800:1 while still enabling high accuracy across several representative computer-vision tasks, including machine-vision benchmarks, flow-cytometry image classification, and identification of objects in real scenes. In all cases we find that the ONN's nonlinearity and depth allowed it to outperform a purely linear ONN encoder. Although our experiments are specialized to ONN sensors for incoherent-light images, alternative ONN platforms should facilitate a range of ONN sensors. These ONN sensors may surpass conventional sensors by pre-processing optical information in spatial, temporal, and/or spectral dimensions, potentially with coherent and quantum qualities, all natively in the optical domain.