 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRINO: Accurate, Robust Radar-Inertial Odometry with Non-Iterative Estimation
Nov 12, 2024



Precise localization and mapping are critical for achieving autonomous navigation in self-driving vehicles. However, ego-motion estimation still faces significant challenges, particularly when GNSS failures occur or under extreme weather conditions (e.g., fog, rain, and snow). In recent years, scanning radar has emerged as an effective solution due to its strong penetration capabilities. Nevertheless, scanning radar data inherently contains high levels of noise, necessitating hundreds to thousands of iterations of optimization to estimate a reliable transformation from the noisy data. Such iterative solving is time-consuming, unstable, and prone to failure. To address these challenges, we propose an accurate and robust Radar-Inertial Odometry system, RINO, which employs a non-iterative solving approach. Our method decouples rotation and translation estimation and applies an adaptive voting scheme for 2D rotation estimation, enhancing efficiency while ensuring consistent solving time. Additionally, the approach implements a loosely coupled system between the scanning radar and an inertial measurement unit (IMU), leveraging Error-State Kalman Filtering (ESKF). Notably, we successfully estimated the uncertainty of the pose estimation from the scanning radar, incorporating this into the filter's Maximum A Posteriori estimation, a consideration that has been previously overlooked. Validation on publicly available datasets demonstrates that RINO outperforms state-of-the-art methods and baselines in both accuracy and robustness. Our code is available at https://github.com/yangsc4063/rino.
Flow-based Recurrent Belief State Learning for POMDPs
May 23, 2022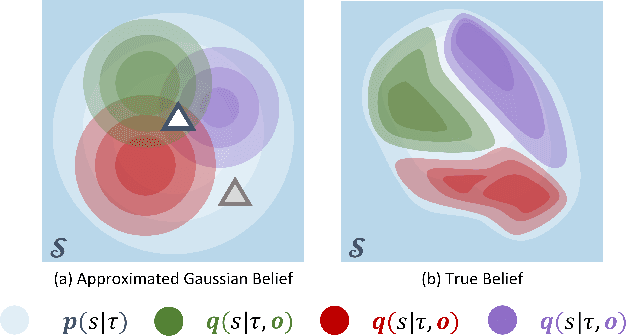
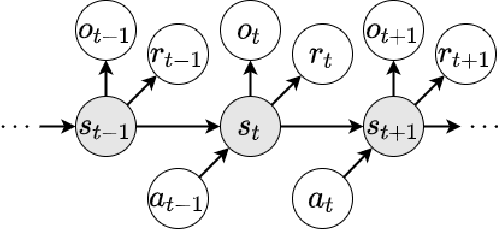
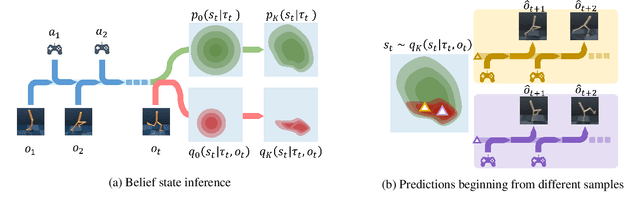

Partially Observable Markov Decision Process (POMDP) provides a principled and generic framework to model real world sequential decision making processes but yet remains unsolved, especially for high dimensional continuous space and unknown models. The main challenge lies in how to accurately obtain the belief state, which is the probability distribution over the unobservable environment states given historical information. Accurately calculating this belief state is a precondition for obtaining an optimal policy of POMDPs. Recent advances in deep learning techniques show great potential to learn good belief states. However, existing methods can only learn approximated distribution with limited flexibility. In this paper, we introduce the \textbf{F}l\textbf{O}w-based \textbf{R}ecurrent \textbf{BE}lief \textbf{S}tate model (FORBES), which incorporates normalizing flows into the variational inference to learn general continuous belief states for POMDPs. Furthermore, we show that the learned belief states can be plugged into downstream RL algorithms to improve performance. In experiments, we show that our methods successfully capture the complex belief states that enable multi-modal predictions as well as high quality reconstructions, and results on challenging visual-motor control tasks show that our method achieves superior performance and sample efficiency.