 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Imitation-Reinforcement Learning Framework for Reduced Baseline Regret
Sep 20, 2022
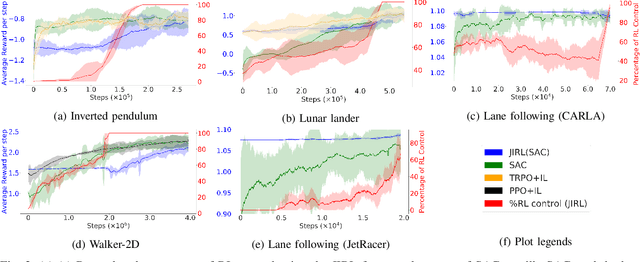

In various control task domains, existing controllers provide a baseline level of performance that -- though possibly suboptimal -- should be maintained. Reinforcement learning (RL) algorithms that rely on extensive exploration of the state and action space can be used to optimize a control policy. However, fully exploratory RL algorithms may decrease performance below a baseline level during training. In this paper, we address the issue of online optimization of a control policy while minimizing regret w.r.t a baseline policy performance. We present a joint imitation-reinforcement learning framework, denoted JIRL. The learning process in JIRL assumes the availability of a baseline policy and is designed with two objectives in mind \textbf{(a)} leveraging the baseline's online demonstrations to minimize the regret w.r.t the baseline policy during training, and \textbf{(b)} eventually surpassing the baseline performance. JIRL addresses these objectives by initially learning to imitate the baseline policy and gradually shifting control from the baseline to an RL agent. Experimental results show that JIRL effectively accomplishes the aforementioned objectives in several, continuous action-space domains. The results demonstrate that JIRL is comparable to a state-of-the-art algorithm in its final performance while incurring significantly lower baseline regret during training in all of the presented domains. Moreover, the results show a reduction factor of up to $21$ in baseline regret over a state-of-the-art baseline regret minimization approach.
A Distributed Hybrid Hardware-In-the-Loop Simulation framework for Infrastructure Enabled Autonomy
Feb 06, 2018
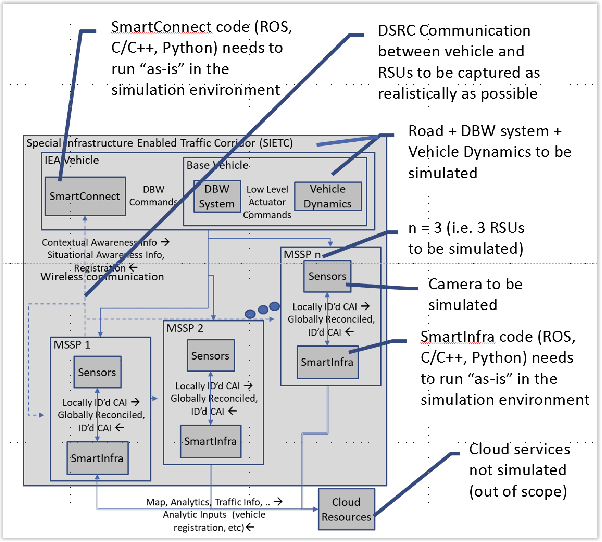
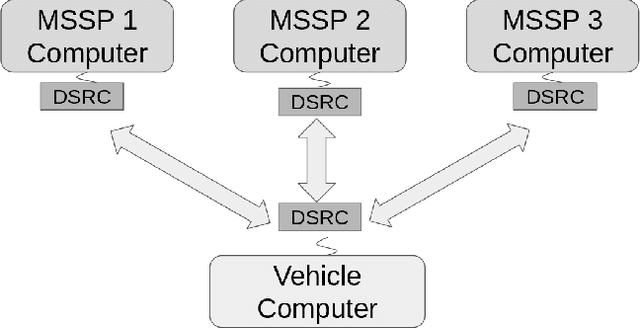
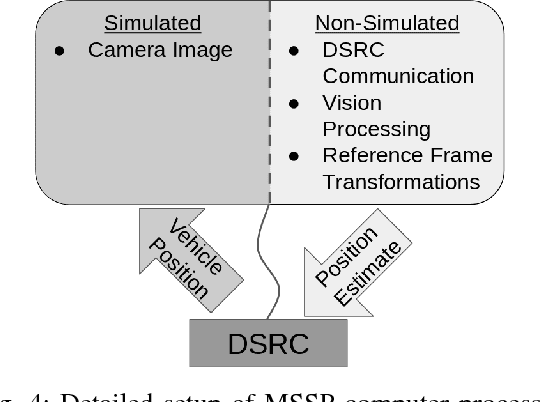
Infrastructure Enabled Autonomy (IEA) is a new paradigm that employs a distributed intelligence architecture for connected autonomous vehicles by offloading core functionalities to the infrastructure. In this paper, we develop a simulation framework that can be used to study the concept. A key challenge for such a simulation is the rapid increase in the scale of the computations with the size of the infrastructure to be considered. Our simulation framework is designed to be distributed and scales proportionally with the infrastructure. By integrally using both the hardware controllers and communication devices as part of the simulation framework, we achieve an optimal balance between modeling of the dynamics and sensors, and reusing real hardware for simulation of proprietary or complex communication methods. Multiple cameras on the infrastructure are simulated. The simulation of the camera image processing is done in distributed hardware and the resultant position information is transmitted wirelessly to the computer simulating the autonomous vehicle. We demonstrate closed loop control of a single vehicle following given waypoints using information from multiple cameras located on Road-Side-Units.