 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-MSTNet: sim2real based Multi-task SpatioTemporal Network Traffic Forecasting
Jan 29, 2026Network traffic forecasting plays a crucial role in intelligent network operations, but existing techniques often perform poorly when faced with limited data. Additionally, multi-task learning methods struggle with task imbalance and negative transfer, especially when modeling various service types. To overcome these challenges, we propose Sim-MSTNet, a multi-task spatiotemporal network traffic forecasting model based on the sim2real approach. Our method leverages a simulator to generate synthetic data, effectively addressing the issue of poor generalization caused by data scarcity. By employing a domain randomization technique, we reduce the distributional gap between synthetic and real data through bi-level optimization of both sample weighting and model training. Moreover, Sim-MSTNet incorporates attention-based mechanisms to selectively share knowledge between tasks and applies dynamic loss weighting to balance task objectives. Extensive experiments on two open-source datasets show that Sim-MSTNet consistently outperforms state-of-the-art baselines, achieving enhanced accuracy and generalization.
Fog Intelligence for Network Anomaly Detection
May 27, 2025Anomalies are common in network system monitoring. When manifested as network threats to be mitigated, service outages to be prevented, and security risks to be ameliorated, detecting such anomalous network behaviors becomes of great importance. However, the growing scale and complexity of the mobile communication networks, as well as the ever-increasing amount and dimensionality of the network surveillance data, make it extremely difficult to monitor a mobile network and discover abnormal network behaviors. Recent advances in machine learning allow for obtaining near-optimal solutions to complicated decision-making problems with many sources of uncertainty that cannot be accurately characterized by traditional mathematical models. However, most machine learning algorithms are centralized, which renders them inapplicable to a large-scale distributed wireless networks with tens of millions of mobile devices. In this article, we present fog intelligence, a distributed machine learning architecture that enables intelligent wireless network management. It preserves the advantage of both edge processing and centralized cloud computing. In addition, the proposed architecture is scalable, privacy-preserving, and well suited for intelligent management of a distributed wireless network.
Multi-Level Association Rule Mining for Wireless Network Time Series Data
Dec 15, 2022Key performance indicators(KPIs) are of great significance in the monitoring of wireless network service quality. The network service quality can be improved by adjusting relevant configuration parameters(CPs) of the base station. However, there are numerous CPs and different cells may affect each other, which bring great challenges to the association analysis of wireless network data. In this paper, we propose an adjustable multi-level association rule mining framework, which can quantitatively mine association rules at each level with environmental information, including engineering parameters and performance management(PMs), and it has interpretability at each level. Specifically, We first cluster similar cells, then quantify KPIs and CPs, and integrate expert knowledge into the association rule mining model, which improve the robustness of the model. The experimental results in real world dataset prove the effectiveness of our method.
CPMLHO:Hyperparameter Tuning via Cutting Plane and Mixed-Level Optimization
Dec 11, 2022The hyperparameter optimization of neural network can be expressed as a bilevel optimization problem. The bilevel optimization is used to automatically update the hyperparameter, and the gradient of the hyperparameter is the approximate gradient based on the best response function. Finding the best response function is very time consuming. In this paper we propose CPMLHO, a new hyperparameter optimization method using cutting plane method and mixed-level objective function.The cutting plane is added to the inner layer to constrain the space of the response function. To obtain more accurate hypergradient,the mixed-level can flexibly adjust the loss function by using the loss of the training set and the verification set. Compared to existing methods, the experimental results show that our method can automatically update the hyperparameters in the training process, and can find more superior hyperparameters with higher accuracy and faster convergence.
Task-aware Similarity Learning for Event-triggered Time Series
Jul 17, 2022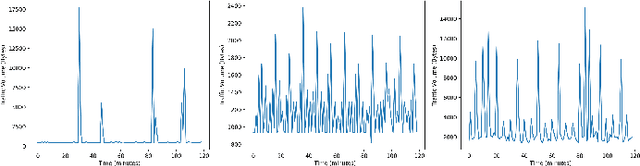


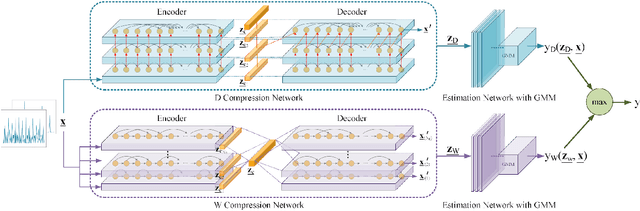
Time series analysis has achieved great success in diverse applications such as network security, environmental monitoring, and medical informatics. Learning similarities among different time series is a crucial problem since it serves as the foundation for downstream analysis such as clustering and anomaly detection. It often remains unclear what kind of distance metric is suitable for similarity learning due to the complex temporal dynamics of the time series generated from event-triggered sensing, which is common in diverse applications, including automated driving, interactive healthcare, and smart home automation. The overarching goal of this paper is to develop an unsupervised learning framework that is capable of learning task-aware similarities among unlabeled event-triggered time series. From the machine learning vantage point, the proposed framework harnesses the power of both hierarchical multi-scale sequence autoencoders and Gaussian Mixture Model (GMM) to effectively learn the low-dimensional representations from the time series. Finally, the obtained similarity measure can be easily visualized for explaining. The proposed framework aspires to offer a stepping stone that gives rise to a systematic approach to model and learn similarities among a multitude of event-triggered time series. Through extensive qualitative and quantitative experiments, it is revealed that the proposed method outperforms state-of-the-art methods considerably.
TimeAutoML: Autonomous Representation Learning for Multivariate Irregularly Sampled Time Series
Oct 04, 2020
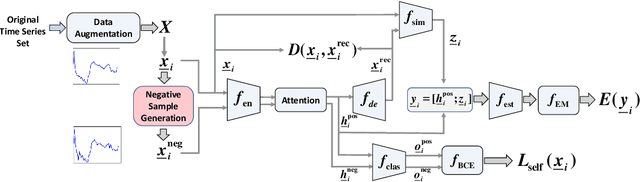

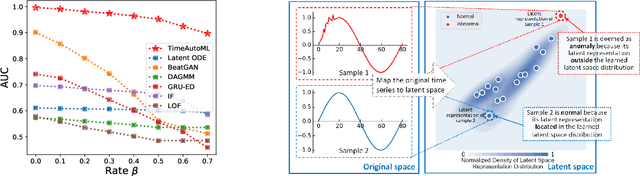
Multivariate time series (MTS) data are becoming increasingly ubiquitous in diverse domains, e.g., IoT systems, health informatics, and 5G networks. To obtain an effective representation of MTS data, it is not only essential to consider unpredictable dynamics and highly variable lengths of these data but also important to address the irregularities in the sampling rates of MTS. Existing parametric approaches rely on manual hyperparameter tuning and may cost a huge amount of labor effort. Therefore, it is desirable to learn the representation automatically and efficiently. To this end, we propose an autonomous representation learning approach for multivariate time series (TimeAutoML) with irregular sampling rates and variable lengths. As opposed to previous works, we first present a representation learning pipeline in which the configuration and hyperparameter optimization are fully automatic and can be tailored for various tasks, e.g., anomaly detection, clustering, etc. Next, a negative sample generation approach and an auxiliary classification task are developed and integrated within TimeAutoML to enhance its representation capability. Extensive empirical studies on real-world datasets demonstrate that the proposed TimeAutoML outperforms competing approaches on various tasks by a large margin. In fact, it achieves the best anomaly detection performance among all comparison algorithms on 78 out of all 85 UCR datasets, acquiring up to 20% performance improvement in terms of AUC score.