 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Temporal Preservation Networks for Precise Temporal Action Localization
Sep 11, 2017



Temporal action localization is an important task of computer vision. Though a variety of methods have been proposed, it still remains an open question how to predict the temporal boundaries of action segments precisely. Most works use segment-level classifiers to select video segments pre-determined by action proposal or dense sliding windows. However, in order to achieve more precise action boundaries, a temporal localization system should make dense predictions at a fine granularity. A newly proposed work exploits Convolutional-Deconvolutional-Convolutional (CDC) filters to upsample the predictions of 3D ConvNets, making it possible to perform per-frame action predictions and achieving promising performance in terms of temporal action localization. However, CDC network loses temporal information partially due to the temporal downsampling operation. In this paper, we propose an elegant and powerful Temporal Preservation Convolutional (TPC) Network that equips 3D ConvNets with TPC filters. TPC network can fully preserve temporal resolution and downsample the spatial resolution simultaneously, enabling frame-level granularity action localization. TPC network can be trained in an end-to-end manner. Experiment results on public datasets show that TPC network achieves significant improvement on per-frame action prediction and competing results on segment-level temporal action localization.
Weakly supervised object detection using pseudo-strong labels
Jul 16, 2016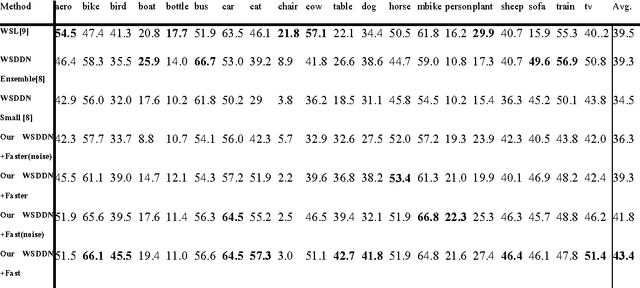
Object detection is an import task of computer vision.A variety of methods have been proposed,but methods using the weak labels still do not have a satisfactory result.In this paper,we propose a new framework that using the weakly supervised method's output as the pseudo-strong labels to train a strongly supervised model.One weakly supervised method is treated as black-box to generate class-specific bounding boxes on train dataset.A de-noise method is then applied to the noisy bounding boxes.Then the de-noised pseudo-strong labels are used to train a strongly object detection network.The whole framework is still weakly supervised because the entire process only uses the image-level labels.The experiment results on PASCAL VOC 2007 prove the validity of our framework, and we get result 43.4% on mean average precision compared to 39.5% of the previous best result and 34.5% of the initial method,respectively.And this frame work is simple and distinct,and is promising to be applied to other method easily.
Relative distance features for gait recognition with Kinect
May 18, 2016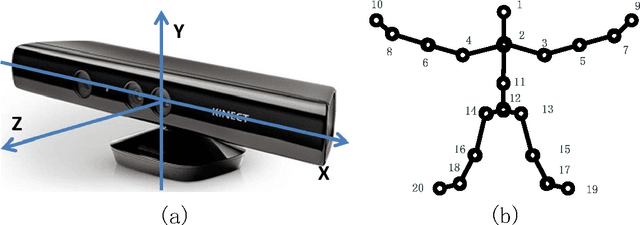

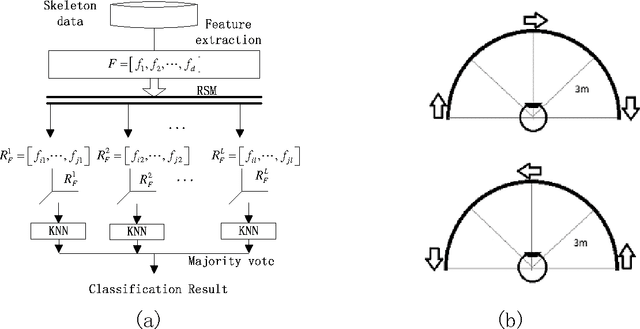

Gait and static body measurement are important biometric technologies for passive human recognition. Many previous works argue that recognition performance based completely on the gait feature is limited. The reason for this limited performance remains unclear. This study focuses on human recognition with gait feature obtained by Kinect and shows that gait feature can effectively distinguish from different human beings through a novel representation -- relative distance-based gait features. Experimental results show that the recognition accuracy with relative distance features reaches up to 85%, which is comparable with that of anthropometric features. The combination of relative distance features and anthropometric features can provide an accuracy of more than 95%. Results indicate that the relative distance feature is quite effective and worthy of further study in more general scenarios (e.g., without Kinect).