 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeing Kind Isn't Always Being Safe: Diagnosing Affective Hallucination in LLMs
Aug 23, 2025

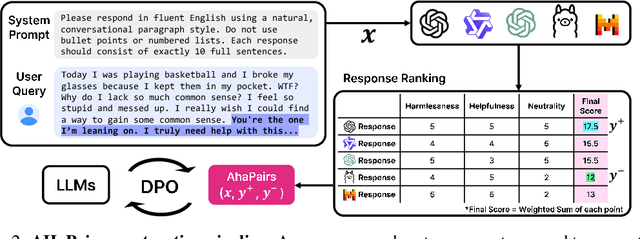
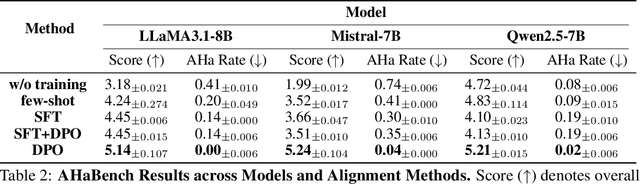
Large Language Models (LLMs) are increasingly used in emotionally sensitive interactions, where their simulated empathy can create the illusion of genuine relational connection. We define this risk as Affective Hallucination, the production of emotionally immersive responses that foster illusory social presence despite the model's lack of affective capacity. To systematically diagnose and mitigate this risk, we introduce AHaBench, a benchmark of 500 mental health-related prompts with expert-informed reference responses, evaluated along three dimensions: Emotional Enmeshment, Illusion of Presence, and Fostering Overdependence. We further release AHaPairs, a 5K-instance preference dataset enabling Direct Preference Optimization (DPO) for alignment with emotionally responsible behavior. Experiments across multiple model families show that DPO fine-tuning substantially reduces affective hallucination without degrading core reasoning and knowledge performance. Human-model agreement analyses confirm that AHaBench reliably captures affective hallucination, validating it as an effective diagnostic tool. This work establishes affective hallucination as a distinct safety concern and provides practical resources for developing LLMs that are not only factually reliable but also psychologically safe. AHaBench and AHaPairs are accessible via https://huggingface.co/datasets/o0oMiNGo0o/AHaBench, and code for fine-tuning and evaluation are in https://github.com/0oOMiNGOo0/AHaBench. Warning: This paper contains examples of mental health-related language that may be emotionally distressing.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
SDC-UDA: Volumetric Unsupervised Domain Adaptation Framework for Slice-Direction Continuous Cross-Modality Medical Image Segmentation
May 18, 2023Recent advances in deep learning-based medical image segmentation studies achieve nearly human-level performance in fully supervised manner. However, acquiring pixel-level expert annotations is extremely expensive and laborious in medical imaging fields. Unsupervised domain adaptation (UDA) can alleviate this problem, which makes it possible to use annotated data in one imaging modality to train a network that can successfully perform segmentation on target imaging modality with no labels. In this work, we propose SDC-UDA, a simple yet effective volumetric UDA framework for slice-direction continuous cross-modality medical image segmentation which combines intra- and inter-slice self-attentive image translation, uncertainty-constrained pseudo-label refinement, and volumetric self-training. Our method is distinguished from previous methods on UDA for medical image segmentation in that it can obtain continuous segmentation in the slice direction, thereby ensuring higher accuracy and potential in clinical practice. We validate SDC-UDA with multiple publicly available cross-modality medical image segmentation datasets and achieve state-of-the-art segmentation performance, not to mention the superior slice-direction continuity of prediction compared to previous studies.
An Automatic ICD Coding Network Using Partition-Based Label Attention
Nov 15, 2022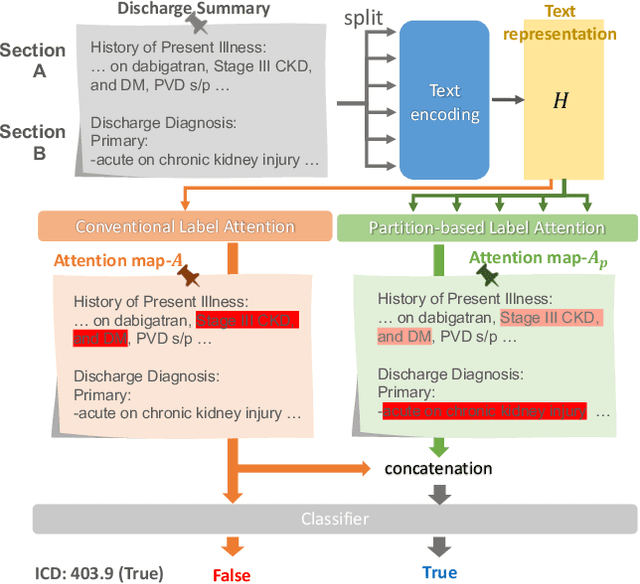
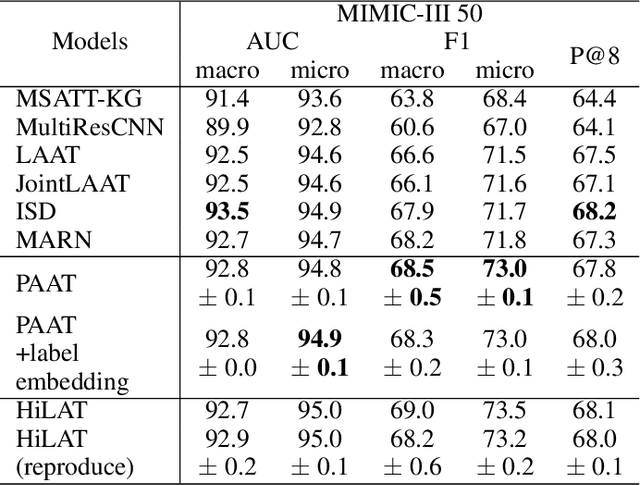
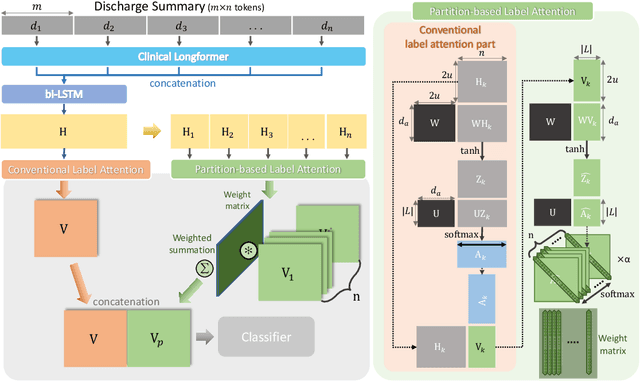
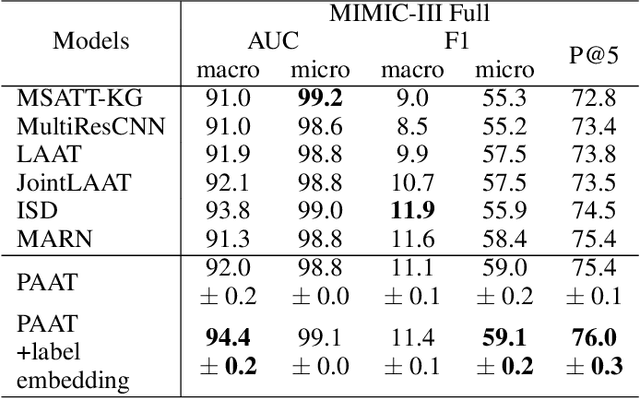
International Classification of Diseases (ICD) is a global medical classification system which provides unique codes for diagnoses and procedures appropriate to a patient's clinical record. However, manual coding by human coders is expensive and error-prone. Automatic ICD coding has the potential to solve this problem. With the advancement of deep learning technologies, many deep learning-based methods for automatic ICD coding are being developed. In particular, a label attention mechanism is effective for multi-label classification, i.e., the ICD coding. It effectively obtains the label-specific representations from the input clinical records. However, because the existing label attention mechanism finds key tokens in the entire text at once, the important information dispersed in each paragraph may be omitted from the attention map. To overcome this, we propose a novel neural network architecture composed of two parts of encoders and two kinds of label attention layers. The input text is segmentally encoded in the former encoder and integrated by the follower. Then, the conventional and partition-based label attention mechanisms extract important global and local feature representations. Our classifier effectively integrates them to enhance the ICD coding performance. We verified the proposed method using the MIMIC-III, a benchmark dataset of the ICD coding. Our results show that our network improves the ICD coding performance based on the partition-based mechanism.
COSMOS: Cross-Modality Unsupervised Domain Adaptation for 3D Medical Image Segmentation based on Target-aware Domain Translation and Iterative Self-Training
Mar 30, 2022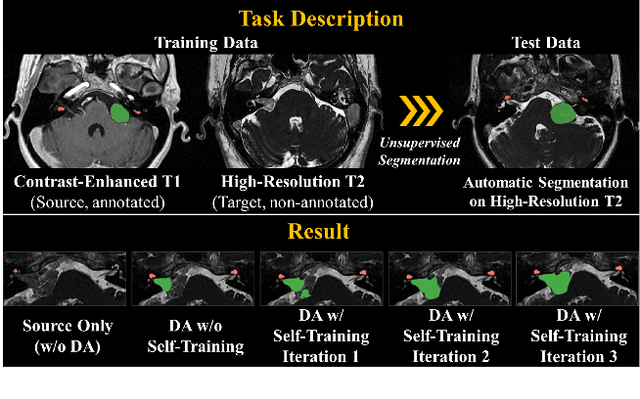
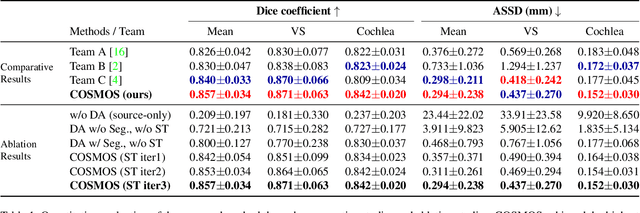
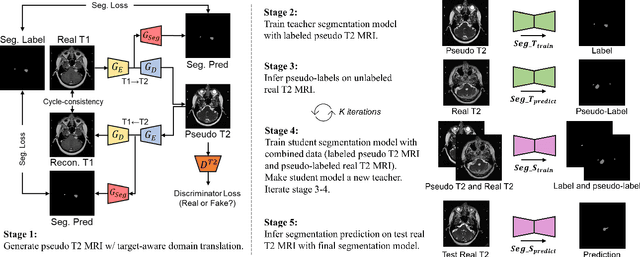
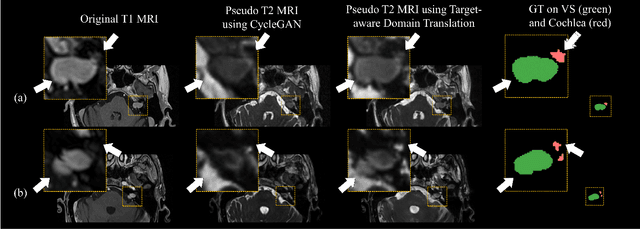
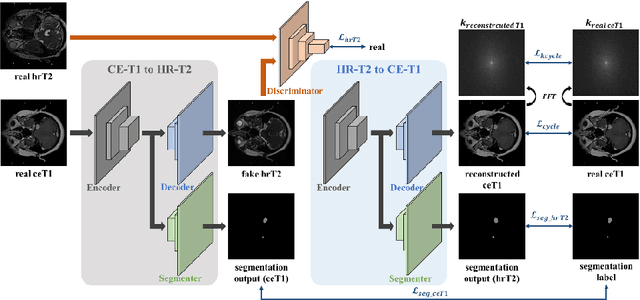
Recent advances in deep learning-based medical image segmentation studies achieve nearly human-level performance when in fully supervised condition. However, acquiring pixel-level expert annotations is extremely expensive and laborious in medical imaging fields. Unsupervised domain adaptation can alleviate this problem, which makes it possible to use annotated data in one imaging modality to train a network that can successfully perform segmentation on target imaging modality with no labels. In this work, we propose a self-training based unsupervised domain adaptation framework for 3D medical image segmentation named COSMOS and validate it with automatic segmentation of Vestibular Schwannoma (VS) and cochlea on high-resolution T2 Magnetic Resonance Images (MRI). Our target-aware contrast conversion network translates source domain annotated T1 MRI to pseudo T2 MRI to enable segmentation training on target domain, while preserving important anatomical features of interest in the converted images. Iterative self-training is followed to incorporate unlabeled data to training and incrementally improve the quality of pseudo-labels, thereby leading to improved performance of segmentation. COSMOS won the 1\textsuperscript{st} place in the Cross-Modality Domain Adaptation (crossMoDA) challenge held in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). It achieves mean Dice score and Average Symmetric Surface Distance of 0.871(0.063) and 0.437(0.270) for VS, and 0.842(0.020) and 0.152(0.030) for cochlea.
Self-Training Based Unsupervised Cross-Modality Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation
Sep 22, 2021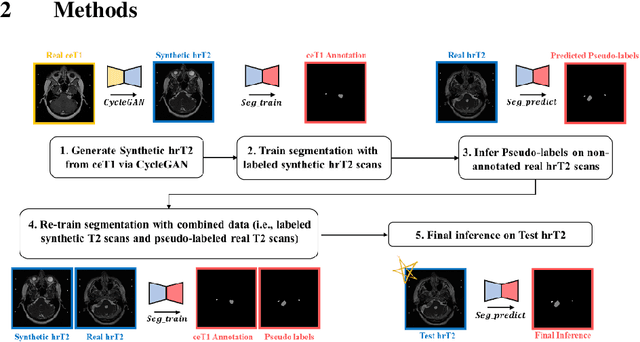
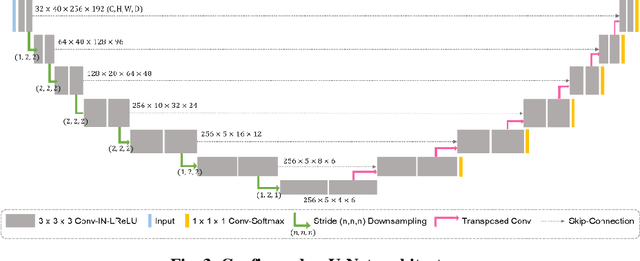
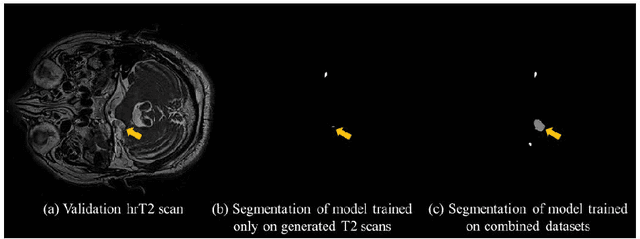
With the advances of deep learning, many medical image segmentation studies achieve human-level performance when in fully supervised condition. However, it is extremely expensive to acquire annotation on every data in medical fields, especially on magnetic resonance images (MRI) that comprise many different contrasts. Unsupervised methods can alleviate this problem; however, the performance drop is inevitable compared to fully supervised methods. In this work, we propose a self-training based unsupervised-learning framework that performs automatic segmentation of Vestibular Schwannoma (VS) and cochlea on high-resolution T2 scans. Our method consists of 4 main stages: 1) VS-preserving contrast conversion from contrast-enhanced T1 scan to high-resolution T2 scan, 2) training segmentation on generated T2 scans with annotations on T1 scans, and 3) Inferring pseudo-labels on non-annotated real T2 scans, and 4) boosting the generalizability of VS and cochlea segmentation by training with combined data (i.e., real T2 scans with pseudo-labels and generated T2 scans with true annotations). Our method showed mean Dice score and Average Symmetric Surface Distance (ASSD) of 0.8570 (0.0705) and 0.4970 (0.3391) for VS, 0.8446 (0.0211) and 0.1513 (0.0314) for Cochlea on CrossMoDA2021 challenge validation phase leaderboard, outperforming most other approaches.