 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-CIC @ DIACR-Ita: POS and Neighbor Based Distributional Models for Lexical Semantic Change in Diachronic Italian Corpora
Nov 07, 2020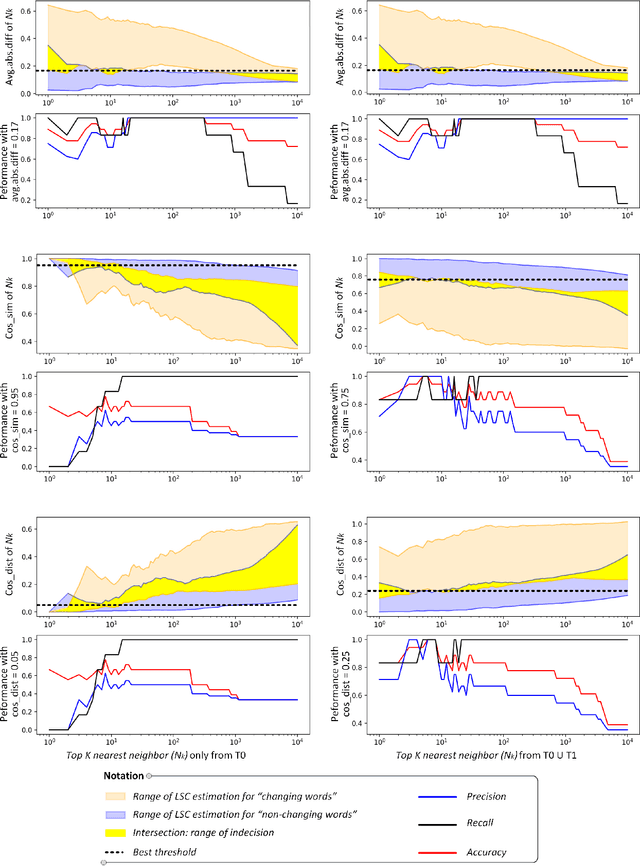


We present our systems and findings on unsupervised lexical semantic change for the Italian language in the DIACR-Ita shared-task at EVALITA 2020. The task is to determine whether a target word has evolved its meaning with time, only relying on raw-text from two time-specific datasets. We propose two models representing the target words across the periods to predict the changing words using threshold and voting schemes. Our first model solely relies on part-of-speech usage and an ensemble of distance measures. The second model uses word embedding representation to extract the neighbor's relative distances across spaces and propose "the average of absolute differences" to estimate lexical semantic change. Our models achieved competent results, ranking third in the DIACR-Ita competition. Furthermore, we experiment with the k_neighbor parameter of our second model to compare the impact of using "the average of absolute differences" versus the cosine distance used in Hamilton et al. (2016).
Toward the Evaluation of Written Proficiency on a Collaborative Social Network for Learning Languages: Yask
Mar 23, 2019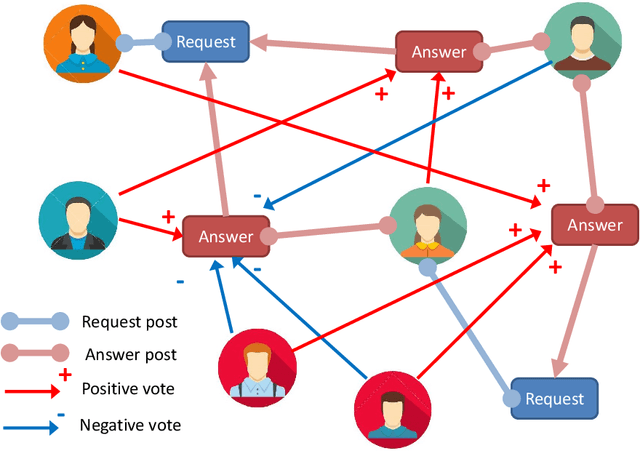

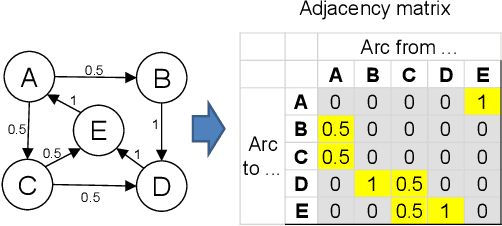
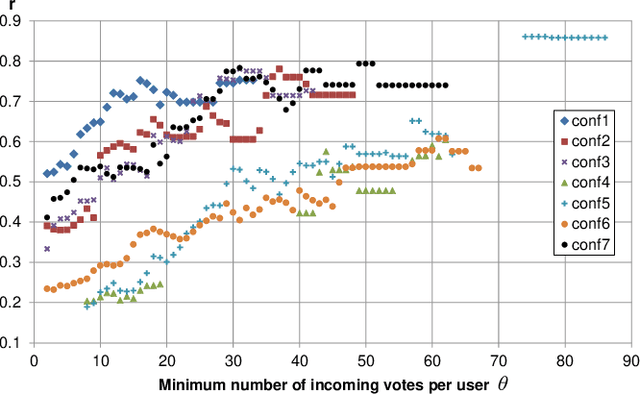
Yask is an online social collaborative network for practicing languages in a framework that includes requests, answers, and votes. Since measuring linguistic competence using current approaches is difficult, expensive and in many cases imprecise, we present a new alternative approach based on social networks. Our method, called Proficiency Rank, extends the well-known Page Rank algorithm to measure the reputation of users in a collaborative social graph. First, we extended Page Rank so that it not only considers positive links (votes) but also negative links. Second, in addition to using explicit links, we also incorporate other 4 types of signals implicit in the social graph. These extensions allow Proficiency Rank to produce proficiency rankings for almost all users in the data set used, where only a minority contributes by answering, while the majority contributes only by voting. This overcomes the intrinsic limitation of Page Rank of only being able to rank the nodes that have incoming links. Our experimental validation showed that the reputation/importance of the users in Yask is significantly correlated with their language proficiency. In contrast, their written production was poorly correlated with the vocabulary profiles of the Common European Framework of Reference. In addition, we found that negative signals (votes) are considerably more informative than positive ones. We concluded that the use of this technology is a promising tool for measuring second language proficiency, even for relatively small groups of people.
A Knowledge-based Filtering Story Recommender System for Theme Lovers with an Application to the Star Trek Television Franchise
Jul 31, 2018



In this paper, we propose a recommender system that takes a user-selected story as input and returns a ranked list of similar stories on the basis of shared literary themes. The user of our system first selects a story of interest from a list of background stories, and then sets, as desired, a handful of knowledge-based filtering options, including the similarity measure used to quantify the similarity between story pairs. As a proof of concept, we validate experimentally our system on a dataset comprising 452 manually themed Star Trek television franchise episodes by using a benchmark of curated sets of related stories. We show that our manual approach to theme assignment significantly outperforms an automated approach to theme identification based on the application of topic models to episode transcripts. Additionally, we compare different approaches based on sets and on a hierarchical-semantic organization of themes to construct similarity functions between stories. The recommender system is implemented in the R package stoRy. A related R Shiny web application is available publicly along with the Stark Trek dataset including the theme ontology, episode annotations, storyset benchmarks, transcripts, and evaluation setup.
Scaling up Heuristic Planning with Relational Decision Trees
Jan 16, 2014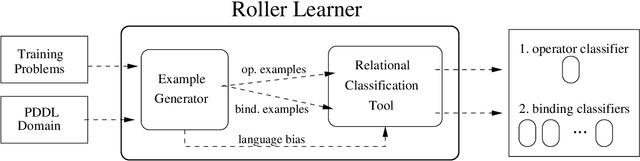
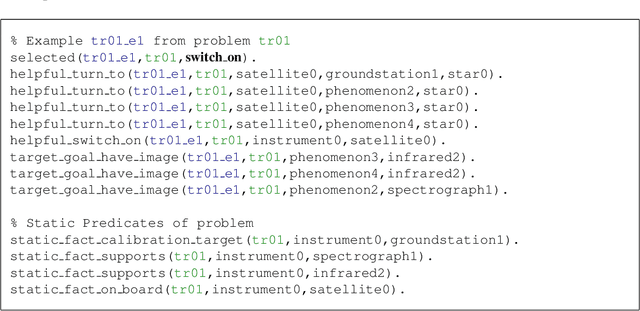

Current evaluation functions for heuristic planning are expensive to compute. In numerous planning problems these functions provide good guidance to the solution, so they are worth the expense. However, when evaluation functions are misguiding or when planning problems are large enough, lots of node evaluations must be computed, which severely limits the scalability of heuristic planners. In this paper, we present a novel solution for reducing node evaluations in heuristic planning based on machine learning. Particularly, we define the task of learning search control for heuristic planning as a relational classification task, and we use an off-the-shelf relational classification tool to address this learning task. Our relational classification task captures the preferred action to select in the different planning contexts of a specific planning domain. These planning contexts are defined by the set of helpful actions of the current state, the goals remaining to be achieved, and the static predicates of the planning task. This paper shows two methods for guiding the search of a heuristic planner with the learned classifiers. The first one consists of using the resulting classifier as an action policy. The second one consists of applying the classifier to generate lookahead states within a Best First Search algorithm. Experiments over a variety of domains reveal that our heuristic planner using the learned classifiers solves larger problems than state-of-the-art planners.