 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multitask learning framework for leveraging subjectivity of annotators to identify misogyny
Jun 22, 2024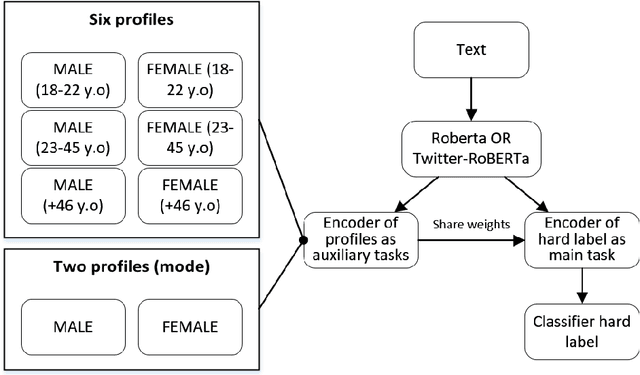
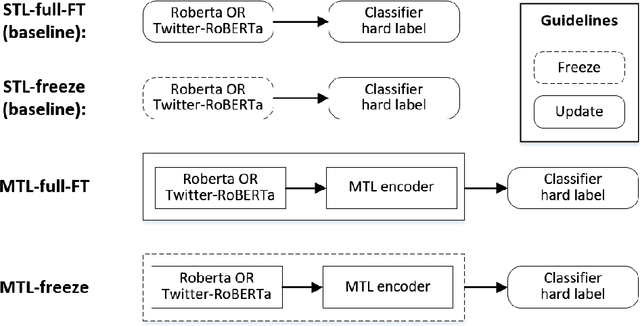
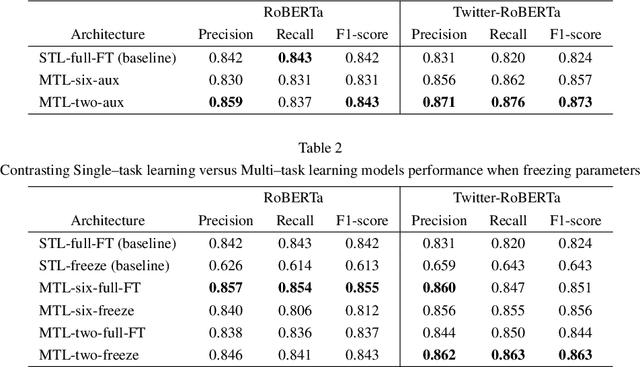

Identifying misogyny using artificial intelligence is a form of combating online toxicity against women. However, the subjective nature of interpreting misogyny poses a significant challenge to model the phenomenon. In this paper, we propose a multitask learning approach that leverages the subjectivity of this task to enhance the performance of the misogyny identification systems. We incorporated diverse perspectives from annotators in our model design, considering gender and age across six profile groups, and conducted extensive experiments and error analysis using two language models to validate our four alternative designs of the multitask learning technique to identify misogynistic content in English tweets. The results demonstrate that incorporating various viewpoints enhances the language models' ability to interpret different forms of misogyny. This research advances content moderation and highlights the importance of embracing diverse perspectives to build effective online moderation systems.
Utilizing deep learning models for the identification of enhancers and super-enhancers based on genomic and epigenomic features
Jan 15, 2024This paper provides an extensive examination of a sizable dataset of English tweets focusing on nine widely recognized cryptocurrencies, specifically Cardano, Binance, Bitcoin, Dogecoin, Ethereum, Fantom, Matic, Shiba, and Ripple. Our primary objective was to conduct a psycholinguistic and emotion analysis of social media content associated with these cryptocurrencies. To enable investigators to make more informed decisions. The study involved comparing linguistic characteristics across the diverse digital coins, shedding light on the distinctive linguistic patterns that emerge within each coin's community. To achieve this, we utilized advanced text analysis techniques. Additionally, our work unveiled an intriguing Understanding of the interplay between these digital assets within the cryptocurrency community. By examining which coin pairs are mentioned together most frequently in the dataset, we established correlations between different cryptocurrencies. To ensure the reliability of our findings, we initially gathered a total of 832,559 tweets from Twitter. These tweets underwent a rigorous preprocessing stage, resulting in a refined dataset of 115,899 tweets that were used for our analysis. Overall, our research offers valuable Perception into the linguistic nuances of various digital coins' online communities and provides a deeper understanding of their interactions in the cryptocurrency space.
Leveraging the power of transformers for guilt detection in text
Jan 15, 2024In recent years, language models and deep learning techniques have revolutionized natural language processing tasks, including emotion detection. However, the specific emotion of guilt has received limited attention in this field. In this research, we explore the applicability of three transformer-based language models for detecting guilt in text and compare their performance for general emotion detection and guilt detection. Our proposed model outformed BERT and RoBERTa models by two and one points respectively. Additionally, we analyze the challenges in developing accurate guilt-detection models and evaluate our model's effectiveness in detecting related emotions like "shame" through qualitative analysis of results.
NLP-CIC @ PRELEARN: Mastering prerequisites relations, from handcrafted features to embeddings
Nov 07, 2020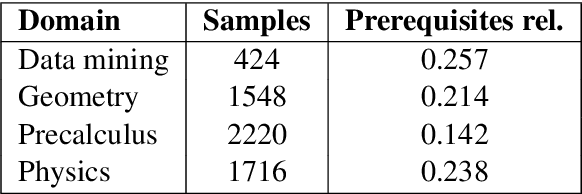
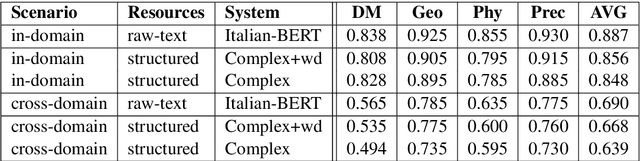

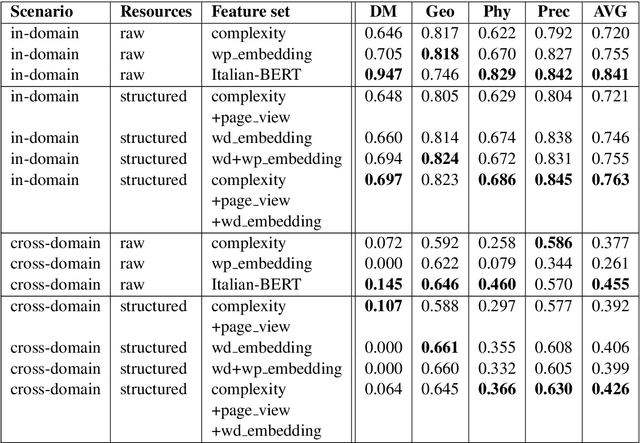
We present our systems and findings for the prerequisite relation learning task (PRELEARN) at EVALITA 2020. The task aims to classify whether a pair of concepts hold a prerequisite relation or not. We model the problem using handcrafted features and embedding representations for in-domain and cross-domain scenarios. Our submissions ranked first place in both scenarios with average F1 score of 0.887 and 0.690 respectively across domains on the test sets. We made our code is freely available.
NLP-CIC @ DIACR-Ita: POS and Neighbor Based Distributional Models for Lexical Semantic Change in Diachronic Italian Corpora
Nov 07, 2020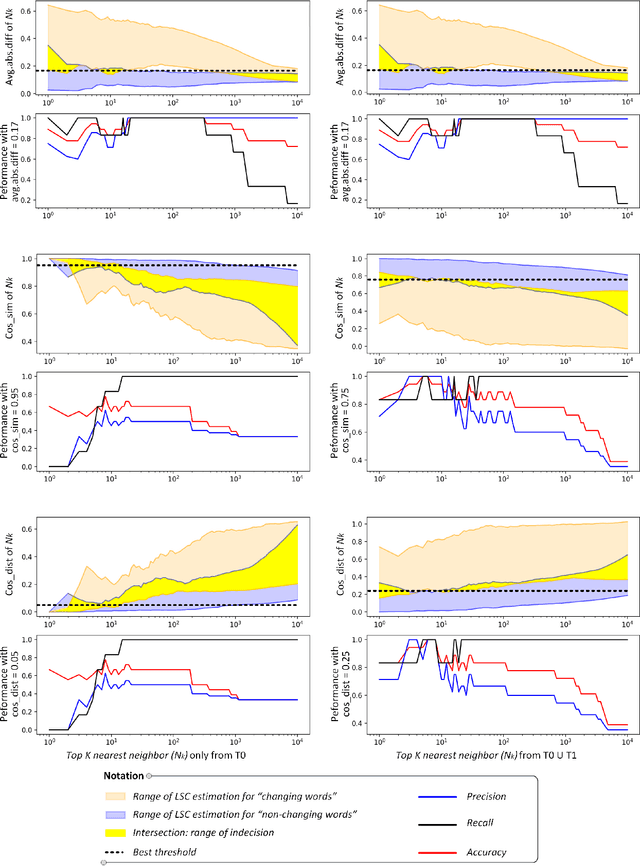


We present our systems and findings on unsupervised lexical semantic change for the Italian language in the DIACR-Ita shared-task at EVALITA 2020. The task is to determine whether a target word has evolved its meaning with time, only relying on raw-text from two time-specific datasets. We propose two models representing the target words across the periods to predict the changing words using threshold and voting schemes. Our first model solely relies on part-of-speech usage and an ensemble of distance measures. The second model uses word embedding representation to extract the neighbor's relative distances across spaces and propose "the average of absolute differences" to estimate lexical semantic change. Our models achieved competent results, ranking third in the DIACR-Ita competition. Furthermore, we experiment with the k_neighbor parameter of our second model to compare the impact of using "the average of absolute differences" versus the cosine distance used in Hamilton et al. (2016).
NLP-CIC at SemEval-2020 Task 9: Analysing sentiment in code-switching language using a simple deep-learning classifier
Sep 07, 2020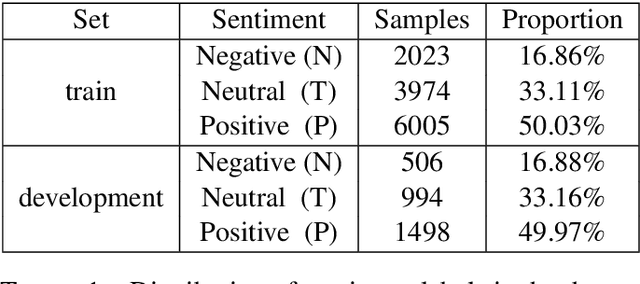
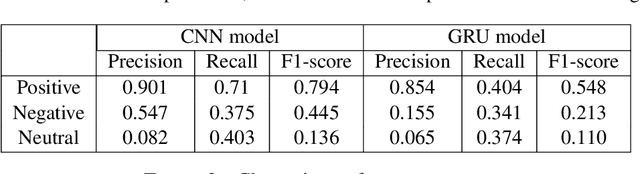
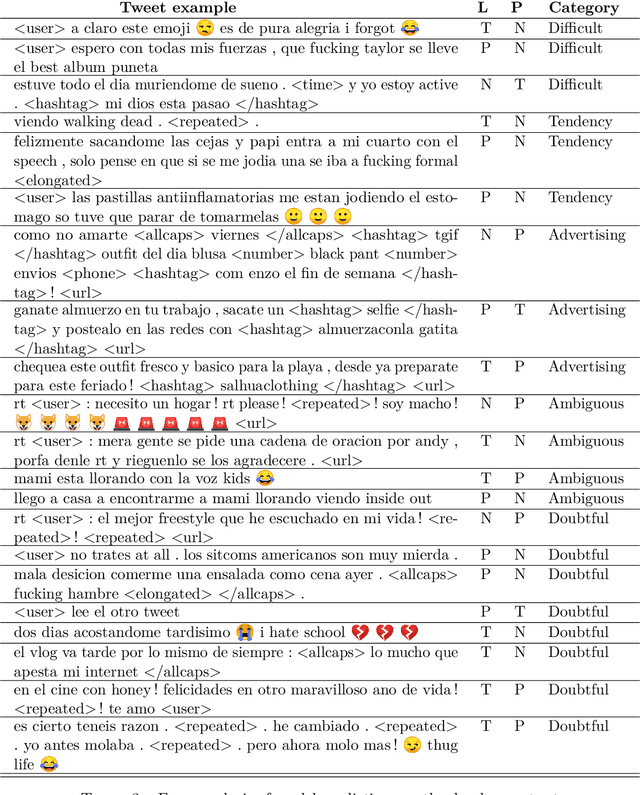
Code-switching is a phenomenon in which two or more languages are used in the same message. Nowadays, it is quite common to find messages with languages mixed in social media. This phenomenon presents a challenge for sentiment analysis. In this paper, we use a standard convolutional neural network model to predict the sentiment of tweets in a blend of Spanish and English languages. Our simple approach achieved a F1-score of 0.71 on test set on the competition. We analyze our best model capabilities and perform error analysis to expose important difficulties for classifying sentiment in a code-switching setting.