 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon TF-IDF variants arise as key components in the test statistic of a penalized likelihood-ratio test for word burstiness
Apr 01, 2026TF-IDF is a classical formula that is widely used for identifying important terms within documents. We show that TF-IDF-like scores arise naturally from the test statistic of a penalized likelihood-ratio test setup capturing word burstiness (also known as word over-dispersion). In our framework, the alternative hypothesis captures word burstiness by modeling a collection of documents according to a family of beta-binomial distributions with a gamma penalty term on the precision parameter. In contrast, the null hypothesis assumes that words are binomially distributed in collection documents, a modeling approach that fails to account for word burstiness. We find that a term-weighting scheme given rise to by this test statistic performs comparably to TF-IDF on document classification tasks. This paper provides insights into TF-IDF from a statistical perspective and underscores the potential of hypothesis testing frameworks for advancing term-weighting scheme development.
Greedy-Gnorm: A Gradient Matrix Norm-Based Alternative to Attention Entropy for Head Pruning
Feb 04, 2026Attention head pruning has emerged as an effective technique for transformer model compression, an increasingly important goal in the era of Green AI. However, existing pruning methods often rely on static importance scores, which fail to capture the evolving role of attention heads during iterative removal. We propose Greedy-Gradient norm (Greedy-Gnorm), a novel head pruning algorithm that dynamically recalculates head importance after each pruning step. Specifically, each head is scored by the elementwise product of the l2-norms of its Q/K/V gradient blocks, as estimated from a hold-out validation set and updated at every greedy iteration. This dynamic approach to scoring mitigates against stale rankings and better reflects gradient-informed importance as pruning progresses. Extensive experiments on BERT, ALBERT, RoBERTa, and XLM-RoBERTa demonstrate that Greedy-Gnorm consistently preserves accuracy under substantial head removal, outperforming attention entropy. By effectively reducing model size while maintaining task performance, Greedy-Gnorm offers a promising step toward more energy-efficient transformer model deployment.
Heaps' Law in GPT-Neo Large Language Model Emulated Corpora
Nov 10, 2023Heaps' law is an empirical relation in text analysis that predicts vocabulary growth as a function of corpus size. While this law has been validated in diverse human-authored text corpora, its applicability to large language model generated text remains unexplored. This study addresses this gap, focusing on the emulation of corpora using the suite of GPT-Neo large language models. To conduct our investigation, we emulated corpora of PubMed abstracts using three different parameter sizes of the GPT-Neo model. Our emulation strategy involved using the initial five words of each PubMed abstract as a prompt and instructing the model to expand the content up to the original abstract's length. Our findings indicate that the generated corpora adhere to Heaps' law. Interestingly, as the GPT-Neo model size grows, its generated vocabulary increasingly adheres to Heaps' law as as observed in human-authored text. To further improve the richness and authenticity of GPT-Neo outputs, future iterations could emphasize enhancing model size or refining the model architecture to curtail vocabulary repetition.
A statistical significance testing approach for measuring term burstiness with applications to domain-specific terminology extraction
Oct 24, 2023Domain-specific terminology extraction is an important task in text analysis. A term in a corpus is said to be "bursty" when its occurrences are concentrated in few out of many documents. Being content rich, bursty terms are highly suited for subject matter characterization, and serve as natural candidates for identifying with technical terminology. Multiple measures of term burstiness have been proposed in the literature. However, the statistical significance testing paradigm has remained underexplored in text analysis, including in relation to term burstiness. To test these waters, we propose as our main contribution a multinomial language model-based exact test of statistical significance for term burstiness. Due to its prohibitive computational cost, we advance a heuristic formula designed to serve as a proxy for test P-values. As a complementary theoretical contribution, we derive a previously unreported relationship connecting the inverse document frequency and inverse collection frequency (two foundational quantities in text analysis) under the multinomial language model. The relation is used in the evaluation of our heuristic. Using the GENIA Term corpus benchmark, we compare our approach against established methods, demonstrating our heuristic's potential in identifying domain-specific technical terms. We hope this demonstration of statistical significance testing in text analysis serves as a springboard for future research.
A Knowledge-based Filtering Story Recommender System for Theme Lovers with an Application to the Star Trek Television Franchise
Jul 31, 2018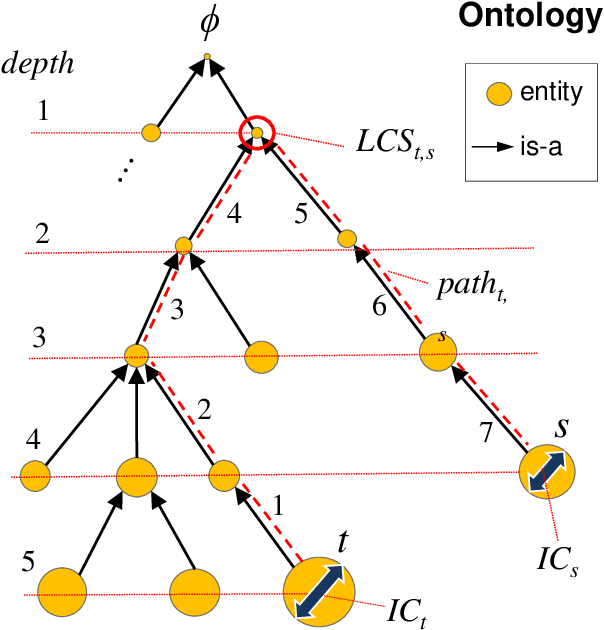



In this paper, we propose a recommender system that takes a user-selected story as input and returns a ranked list of similar stories on the basis of shared literary themes. The user of our system first selects a story of interest from a list of background stories, and then sets, as desired, a handful of knowledge-based filtering options, including the similarity measure used to quantify the similarity between story pairs. As a proof of concept, we validate experimentally our system on a dataset comprising 452 manually themed Star Trek television franchise episodes by using a benchmark of curated sets of related stories. We show that our manual approach to theme assignment significantly outperforms an automated approach to theme identification based on the application of topic models to episode transcripts. Additionally, we compare different approaches based on sets and on a hierarchical-semantic organization of themes to construct similarity functions between stories. The recommender system is implemented in the R package stoRy. A related R Shiny web application is available publicly along with the Stark Trek dataset including the theme ontology, episode annotations, storyset benchmarks, transcripts, and evaluation setup.