 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward the Evaluation of Written Proficiency on a Collaborative Social Network for Learning Languages: Yask
Mar 23, 2019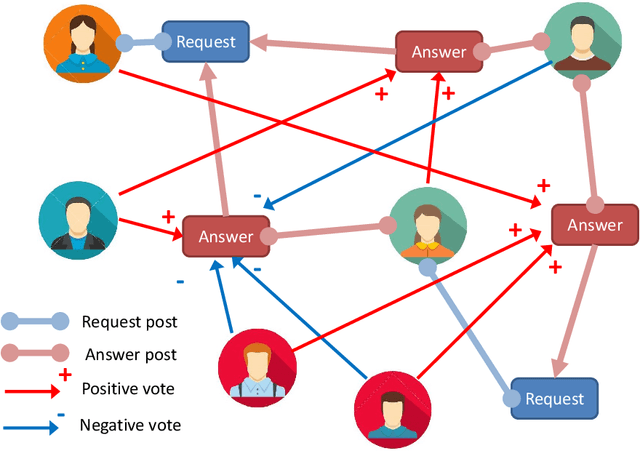

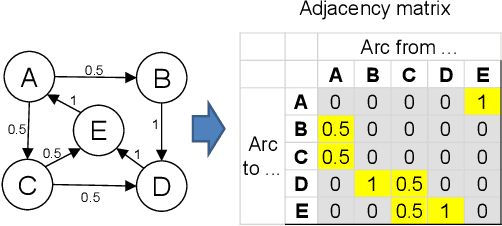
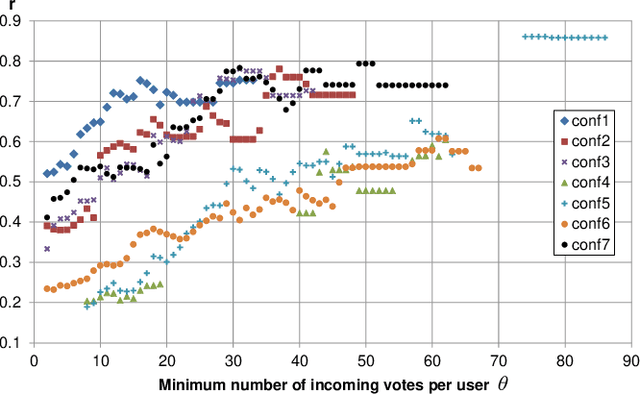
Yask is an online social collaborative network for practicing languages in a framework that includes requests, answers, and votes. Since measuring linguistic competence using current approaches is difficult, expensive and in many cases imprecise, we present a new alternative approach based on social networks. Our method, called Proficiency Rank, extends the well-known Page Rank algorithm to measure the reputation of users in a collaborative social graph. First, we extended Page Rank so that it not only considers positive links (votes) but also negative links. Second, in addition to using explicit links, we also incorporate other 4 types of signals implicit in the social graph. These extensions allow Proficiency Rank to produce proficiency rankings for almost all users in the data set used, where only a minority contributes by answering, while the majority contributes only by voting. This overcomes the intrinsic limitation of Page Rank of only being able to rank the nodes that have incoming links. Our experimental validation showed that the reputation/importance of the users in Yask is significantly correlated with their language proficiency. In contrast, their written production was poorly correlated with the vocabulary profiles of the Common European Framework of Reference. In addition, we found that negative signals (votes) are considerably more informative than positive ones. We concluded that the use of this technology is a promising tool for measuring second language proficiency, even for relatively small groups of people.
A Knowledge-based Filtering Story Recommender System for Theme Lovers with an Application to the Star Trek Television Franchise
Jul 31, 2018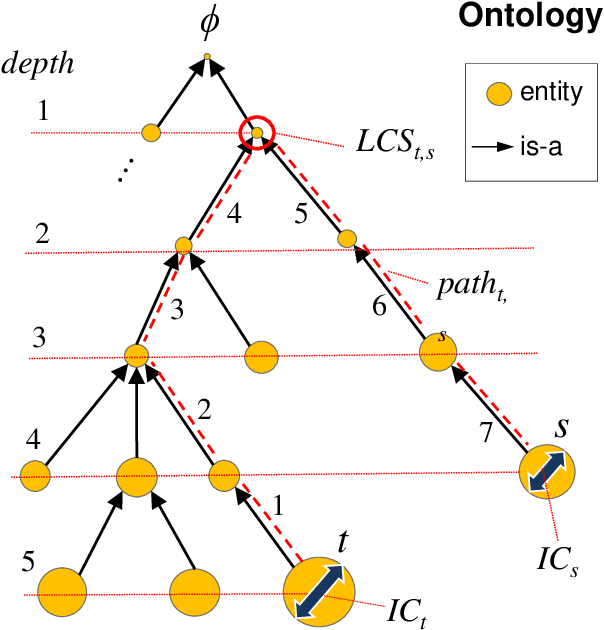



In this paper, we propose a recommender system that takes a user-selected story as input and returns a ranked list of similar stories on the basis of shared literary themes. The user of our system first selects a story of interest from a list of background stories, and then sets, as desired, a handful of knowledge-based filtering options, including the similarity measure used to quantify the similarity between story pairs. As a proof of concept, we validate experimentally our system on a dataset comprising 452 manually themed Star Trek television franchise episodes by using a benchmark of curated sets of related stories. We show that our manual approach to theme assignment significantly outperforms an automated approach to theme identification based on the application of topic models to episode transcripts. Additionally, we compare different approaches based on sets and on a hierarchical-semantic organization of themes to construct similarity functions between stories. The recommender system is implemented in the R package stoRy. A related R Shiny web application is available publicly along with the Stark Trek dataset including the theme ontology, episode annotations, storyset benchmarks, transcripts, and evaluation setup.