 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling 3D Ocean Biogeochemical Provinces: A Machine Learning Approach for Systematic Clustering and Validation
Apr 25, 2025Defining ocean regions and water masses helps to understand marine processes and can serve downstream-tasks such as defining marine protected areas. However, such definitions are often a result of subjective decisions potentially producing misleading, unreproducible results. Here, the aim was to objectively define regions of the North Atlantic. For this, a data-driven, systematic machine learning approach was applied to generate and validate ocean clusters employing external, internal and relative validation techniques. About 300 million measured salinity, temperature, and oxygen, nitrate, phosphate and silicate concentration values served as input for various clustering methods (KMeans, agglomerative Ward, and Density-Based Spatial Clustering of Applications with Noise (DBSCAN)). Uniform Manifold Approximation and Projection (UMAP) emphasised (dis-)similarities in the data while reducing dimensionality. Based on a systematic validation of the considered clustering methods and their hyperparameters, the results showed that UMAP-DBSCAN best represented the data. To address stochastic variability, 100 UMAP-DBSCAN clustering runs were conducted and aggregated using Native Emergent Manifold Interrogation (NEMI), producing a final set of 321 clusters. Reproducibility was evaluated by calculating the ensemble overlap (88.81 +- 1.8%) and the mean grid cell-wise uncertainty estimated by NEMI (15.49 +- 20%). The presented clustering results agreed very well with common water mass definitions. This study revealed a more detailed regionalization compared to previous concepts such as the Longhurst provinces. The applied method is objective, efficient and reproducible and will support future research focusing on biogeochemical differences and changes in oceanic regions.
User Identification via Free Roaming Eye Tracking Data
Mar 14, 2024We present a new dataset of "free roaming" (FR) and "targeted roaming" (TR): a pool of 41 participants is asked to walk around a university campus (FR) or is asked to find a particular room within a library (TR). Eye movements are recorded using a commodity wearable eye tracker (Pupil Labs Neon at 200Hz). On this dataset we investigate the accuracy of user identification using a previously known machine learning pipeline where a Radial Basis Function Network (RBFN) is used as classifier. Our highest accuracies are 87.3% for FR and 89.4% for TR. This should be compared to 95.3% which is the (corresponding) highest accuracy we are aware of (achieved in a laboratory setting using the "RAN" stimulus of the BioEye 2015 competition dataset). To the best of our knowledge, our results are the first that study user identification in a non laboratory setting; such settings are often more feasible than laboratory settings and may include further advantages. The minimum duration of each recording is 263s for FR and 154s for TR. Our best accuracies are obtained when restricting to 120s and 140s for FR and TR respectively, always cut from the end of the trajectories (both for the training and testing sessions). If we cut the same length from the beginning, then accuracies are 12.2% lower for FR and around 6.4% lower for TR. On the full trajectories accuracies are lower by 5% and 52% for FR and TR. We also investigate the impact of including higher order velocity derivatives (such as acceleration, jerk, or jounce).
Predicting Gender via Eye Movements
Jun 15, 2022
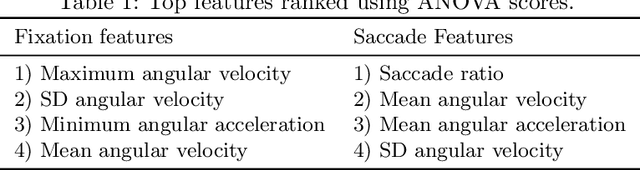

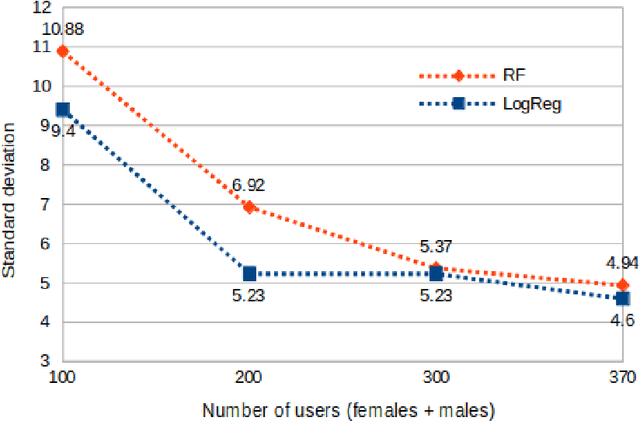
In this paper, we report the first stable results on gender prediction via eye movements. We use a dataset with images of faces as stimuli and with a large number of 370 participants. Stability has two meanings for us: first that we are able to estimate the standard deviation (SD) of a single prediction experiment (it is around 4.1 %); this is achieved by varying the number of participants. And second, we are able to provide a mean accuracy with a very low standard error (SEM): our accuracy is 65.2 %, and the SEM is 0.80 %; this is achieved through many runs of randomly selecting training and test sets for the prediction. Our study shows that two particular classifiers achieve the best accuracies: Random Forests and Logistic Regression. Our results reconfirm previous findings that females are more biased towards the left eyes of the stimuli.
An Extensive Study of User Identification via Eye Movements across Multiple Datasets
Nov 10, 2021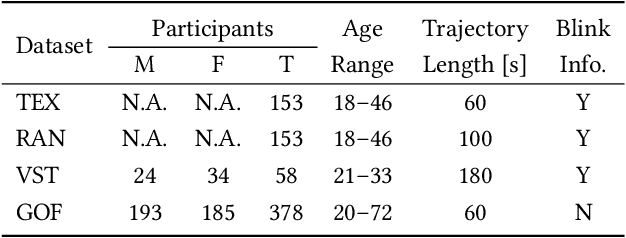

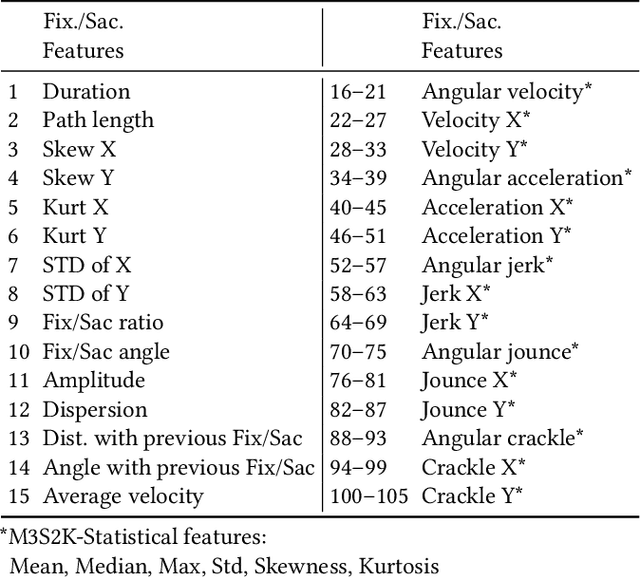

Several studies have reported that biometric identification based on eye movement characteristics can be used for authentication. This paper provides an extensive study of user identification via eye movements across multiple datasets based on an improved version of method originally proposed by George and Routray. We analyzed our method with respect to several factors that affect the identification accuracy, such as the type of stimulus, the IVT parameters (used for segmenting the trajectories into fixation and saccades), adding new features such as higher-order derivatives of eye movements, the inclusion of blink information, template aging, age and gender.We find that three methods namely selecting optimal IVT parameters, adding higher-order derivatives features and including an additional blink classifier have a positive impact on the identification accuracy. The improvements range from a few percentage points, up to an impressive 9 % increase on one of the datasets.
Multiple Context-Free Tree Grammars: Lexicalization and Characterization
Jul 11, 2017
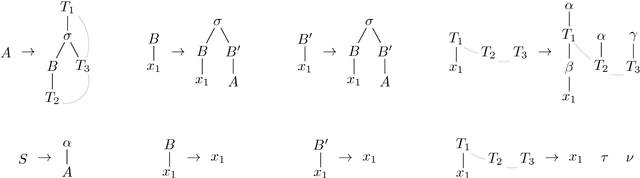
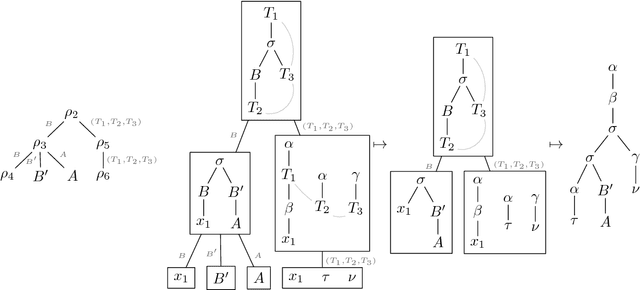
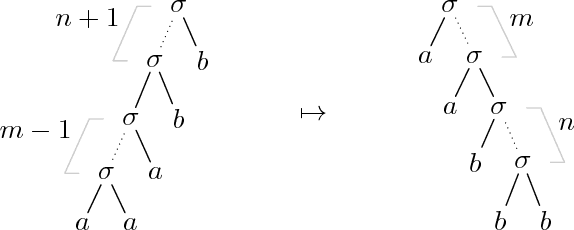
Multiple (simple) context-free tree grammars are investigated, where "simple" means "linear and nondeleting". Every multiple context-free tree grammar that is finitely ambiguous can be lexicalized; i.e., it can be transformed into an equivalent one (generating the same tree language) in which each rule of the grammar contains a lexical symbol. Due to this transformation, the rank of the nonterminals increases at most by 1, and the multiplicity (or fan-out) of the grammar increases at most by the maximal rank of the lexical symbols; in particular, the multiplicity does not increase when all lexical symbols have rank 0. Multiple context-free tree grammars have the same tree generating power as multi-component tree adjoining grammars (provided the latter can use a root-marker). Moreover, every multi-component tree adjoining grammar that is finitely ambiguous can be lexicalized. Multiple context-free tree grammars have the same string generating power as multiple context-free (string) grammars and polynomial time parsing algorithms. A tree language can be generated by a multiple context-free tree grammar if and only if it is the image of a regular tree language under a deterministic finite-copying macro tree transducer. Multiple context-free tree grammars can be used as a synchronous translation device.
Restricted Global Grammar Constraints
Jun 29, 2009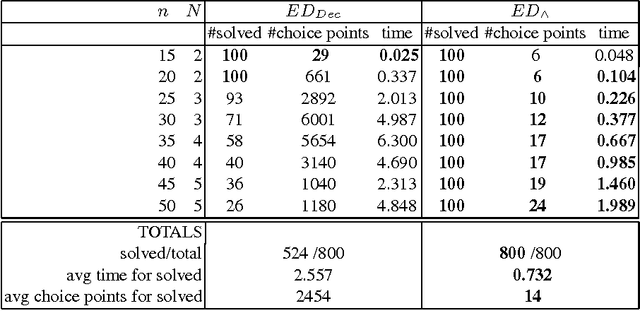
We investigate the global GRAMMAR constraint over restricted classes of context free grammars like deterministic and unambiguous context-free grammars. We show that detecting disentailment for the GRAMMAR constraint in these cases is as hard as parsing an unrestricted context free grammar.We also consider the class of linear grammars and give a propagator that runs in quadratic time. Finally, to demonstrate the use of linear grammars, we show that a weighted linear GRAMMAR constraint can efficiently encode the EDITDISTANCE constraint, and a conjunction of the EDITDISTANCE constraint and the REGULAR constraint