 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradutor: Building a Variety Specific Translation Model
Feb 20, 2025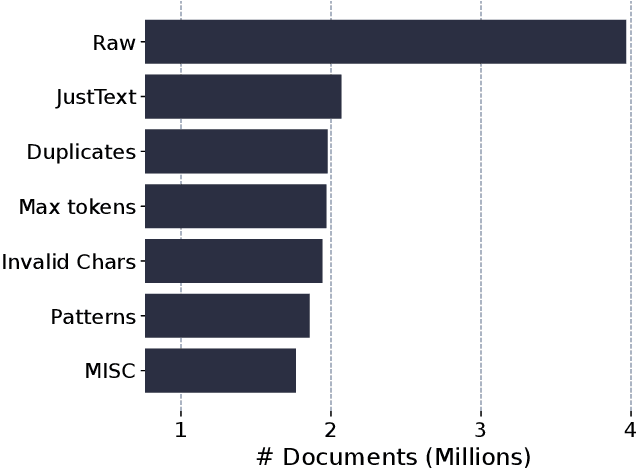
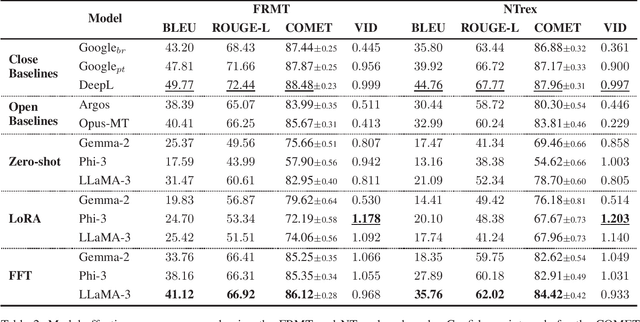
Language models have become foundational to many widely used systems. However, these seemingly advantageous models are double-edged swords. While they excel in tasks related to resource-rich languages like English, they often lose the fine nuances of language forms, dialects, and varieties that are inherent to languages spoken in multiple regions of the world. Languages like European Portuguese are neglected in favor of their more popular counterpart, Brazilian Portuguese, leading to suboptimal performance in various linguistic tasks. To address this gap, we introduce the first open-source translation model specifically tailored for European Portuguese, along with a novel dataset specifically designed for this task. Results from automatic evaluations on two benchmark datasets demonstrate that our best model surpasses existing open-source translation systems for Portuguese and approaches the performance of industry-leading closed-source systems for European Portuguese. By making our dataset, models, and code publicly available, we aim to support and encourage further research, fostering advancements in the representation of underrepresented language varieties.
Numbers Matter! Bringing Quantity-awareness to Retrieval Systems
Jul 14, 2024Quantitative information plays a crucial role in understanding and interpreting the content of documents. Many user queries contain quantities and cannot be resolved without understanding their semantics, e.g., ``car that costs less than $10k''. Yet, modern search engines apply the same ranking mechanisms for both words and quantities, overlooking magnitude and unit information. In this paper, we introduce two quantity-aware ranking techniques designed to rank both the quantity and textual content either jointly or independently. These techniques incorporate quantity information in available retrieval systems and can address queries with numerical conditions equal, greater than, and less than. To evaluate the effectiveness of our proposed models, we introduce two novel quantity-aware benchmark datasets in the domains of finance and medicine and compare our method against various lexical and neural models. The code and data are available under https://github.com/satya77/QuantityAwareRankers.
CQE: A Comprehensive Quantity Extractor
May 15, 2023



Quantities are essential in documents to describe factual information. They are ubiquitous in application domains such as finance, business, medicine, and science in general. Compared to other information extraction approaches, interestingly only a few works exist that describe methods for a proper extraction and representation of quantities in text. In this paper, we present such a comprehensive quantity extraction framework from text data. It efficiently detects combinations of values and units, the behavior of a quantity (e.g., rising or falling), and the concept a quantity is associated with. Our framework makes use of dependency parsing and a dictionary of units, and it provides for a proper normalization and standardization of detected quantities. Using a novel dataset for evaluation, we show that our open source framework outperforms other systems and -- to the best of our knowledge -- is the first to detect concepts associated with identified quantities. The code and data underlying our framework are available at https://github.com/vivkaz/CQE.
BERT got a Date: Introducing Transformers to Temporal Tagging
Oct 04, 2021
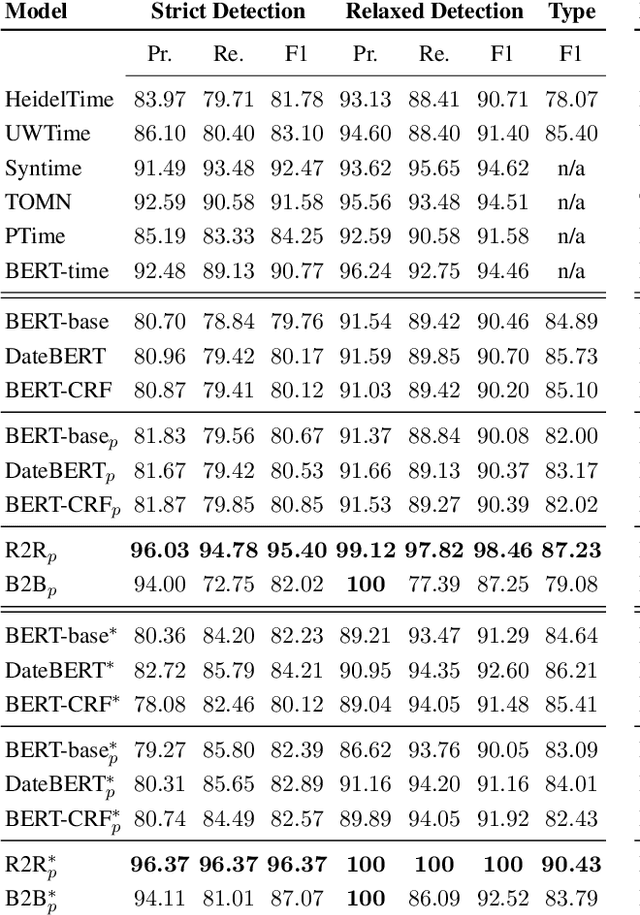
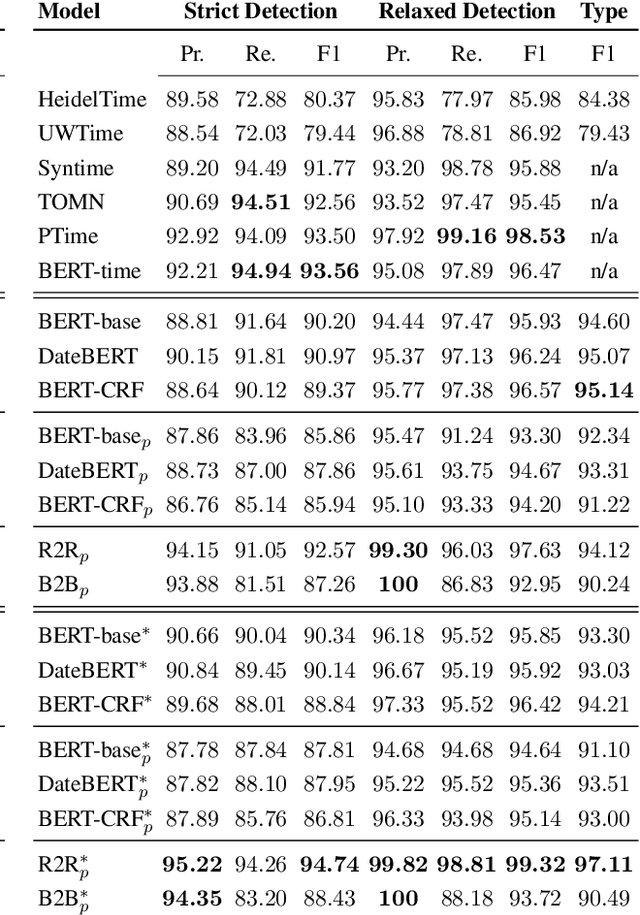
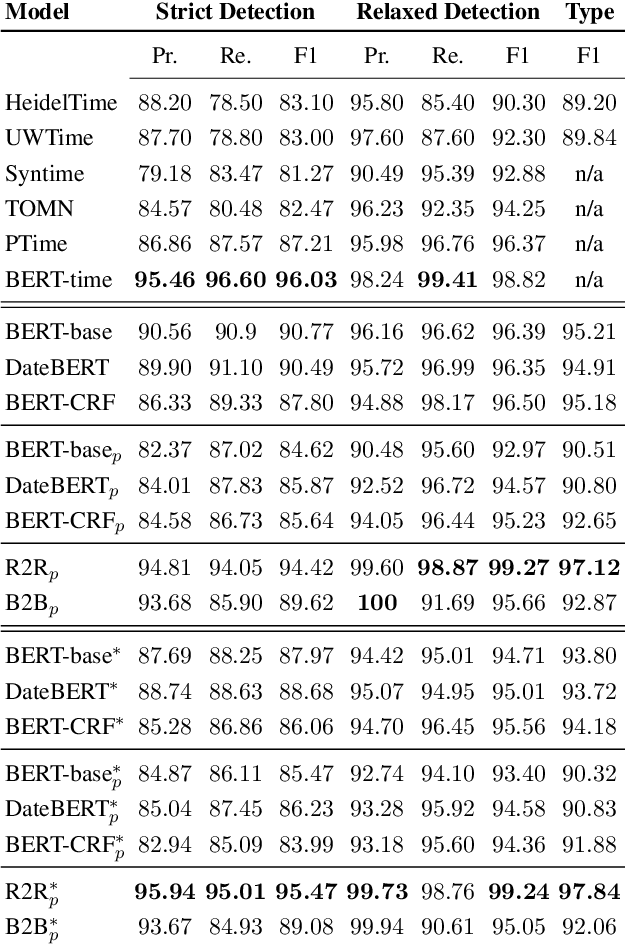
Temporal expressions in text play a significant role in language understanding and correctly identifying them is fundamental to various retrieval and natural language processing systems. Previous works have slowly shifted from rule-based to neural architectures, capable of tagging expressions with higher accuracy. However, neural models can not yet distinguish between different expression types at the same level as their rule-based counterparts. In this work, we aim to identify the most suitable transformer architecture for joint temporal tagging and type classification, as well as, investigating the effect of semi-supervised training on the performance of these systems. Based on our study of token classification variants and encoder-decoder architectures, we present a transformer encoder-decoder model using the RoBERTa language model as our best performing system. By supplementing training resources with weakly labeled data from rule-based systems, our model surpasses previous works in temporal tagging and type classification, especially on rare classes. Our code and pre-trained experiments are available at: https://github.com/satya77/Transformer_Temporal_Tagger
Topical Change Detection in Documents via Embeddings of Long Sequences
Dec 07, 2020
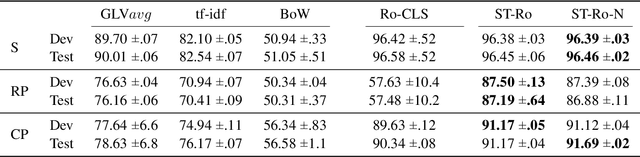
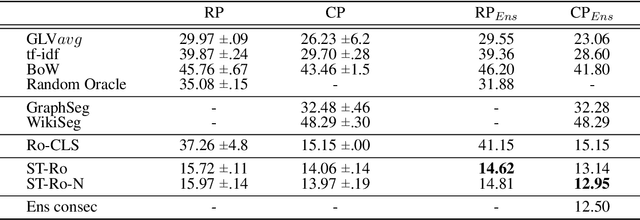

In a longer document, the topic often slightly shifts from one passage to the next, where topic boundaries are usually indicated by semantically coherent segments. Discovering this latent structure in a document improves the readability and is essential for passage retrieval and summarization tasks. We formulate the task of text segmentation as an independent supervised prediction task, making it suitable to train on Transformer-based language models. By fine-tuning on paragraphs of similar sections, we are able to show that learned features encode topic information, which can be used to find the section boundaries and divide the text into coherent segments. Unlike previous approaches, which mostly operate on sentence-level, we consistently use a broader context of an entire paragraph and assume topical independence of preceeding and succeeding text. We lastly introduce a novel large-scale dataset constructed from online Terms-of-Service documents, on which we compare against various traditional and deep learning baselines, showing significantly better performance of Transformer-based methods.
TopExNet: Entity-Centric Network Topic Exploration in News Streams
May 31, 2019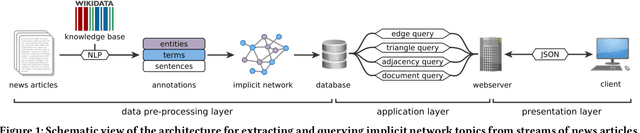
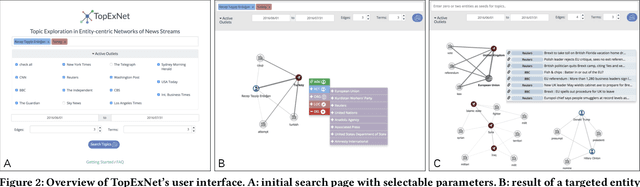
The recent introduction of entity-centric implicit network representations of unstructured text offers novel ways for exploring entity relations in document collections and streams efficiently and interactively. Here, we present TopExNet as a tool for exploring entity-centric network topics in streams of news articles. The application is available as a web service at https://topexnet.ifi.uni-heidelberg.de/ .
Word Embeddings for Entity-annotated Texts
Mar 20, 2019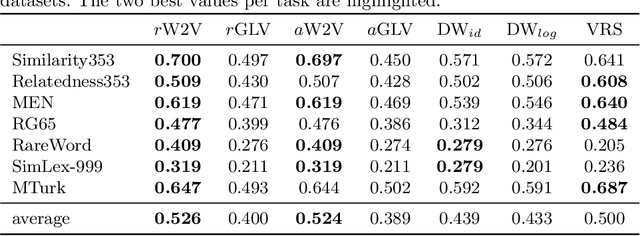
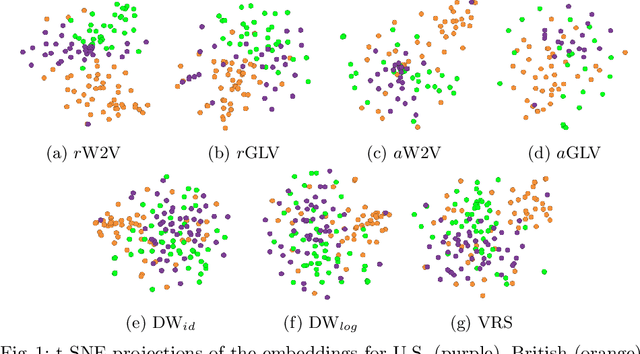
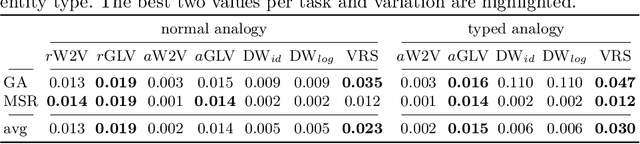

Many information retrieval and natural language processing tasks due to their ability to capture lexical semantics. However, while many such tasks involve or even rely on named entities as central components, popular word embedding models have so far failed to include entities as first-class citizens. While it seems intuitive that annotating named entities in the training, corpus should result in more intelligent word features for downstream tasks, performance issues arise when popular embedding approaches are naively applied to entity annotated corpora. Not only are the resulting entity embeddings less useful than expected, but one also finds that the performance of the non-entity word embeddings degrades in comparison to those trained on the raw, unannotated corpus. In this paper, we investigate approaches to jointly train word and entity embeddings on a large corpus with automatically annotated and linked entities. We discuss two distinct approaches to the generation of such embeddings, namely the training of state-of-the-art embeddings on raw text and annotated versions of the corpus, as well as node embeddings of a co-occurrence graph representation of the annotated corpus. We compare the performance of annotated embeddings and classical word embeddings on a variety of word similarity, analogy, and clustering evaluation tasks, and investigate their performance in entity-specific tasks. Our findings show that it takes more than training popular word embedding models on an annotated corpus to create entity embeddings with acceptable performance on common test cases. Based on these results, we discuss how and when node embeddings of the co-occurrence graph representation of the text can restore the performance.