 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeheiDS at ArchEHR-QA 2025: From Fixed-k to Query-dependent-k for Retrieval Augmented Generation
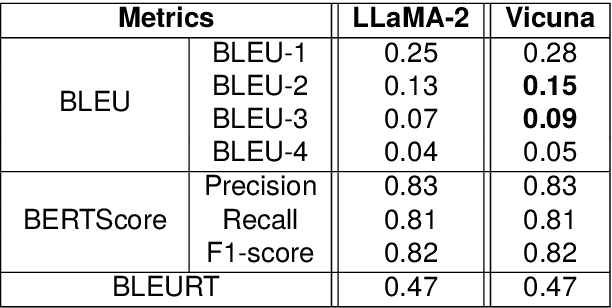
Jun 24, 2025This paper presents the approach of our team called heiDS for the ArchEHR-QA 2025 shared task. A pipeline using a retrieval augmented generation (RAG) framework is designed to generate answers that are attributed to clinical evidence from the electronic health records (EHRs) of patients in response to patient-specific questions. We explored various components of a RAG framework, focusing on ranked list truncation (RLT) retrieval strategies and attribution approaches. Instead of using a fixed top-k RLT retrieval strategy, we employ a query-dependent-k retrieval strategy, including the existing surprise and autocut methods and two new methods proposed in this work, autocut* and elbow. The experimental results show the benefits of our strategy in producing factual and relevant answers when compared to a fixed-$k$.
ClusterTalk: Corpus Exploration Framework using Multi-Dimensional Exploratory Search
Dec 19, 2024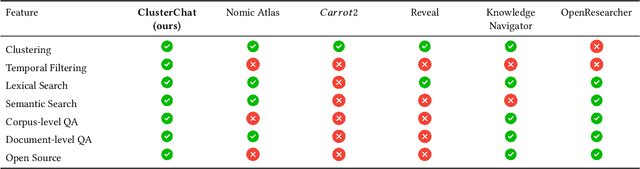
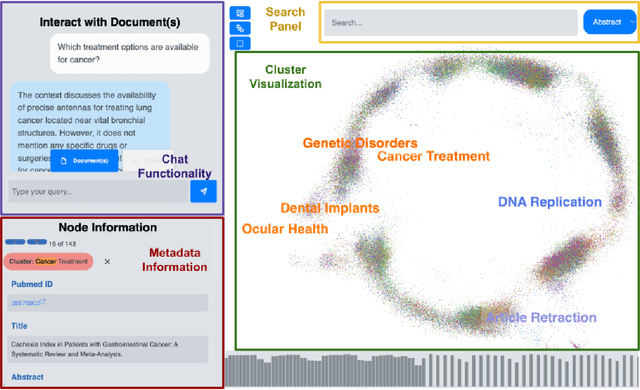
Exploratory search of large text corpora is essential in domains like biomedical research, where large amounts of research literature are continuously generated. This paper presents ClusterTalk (The demo video and source code are available at: https://github.com/achouhan93/ClusterTalk), a framework for corpus exploration using multi-dimensional exploratory search. Our system integrates document clustering with faceted search, allowing users to interactively refine their exploration and ask corpus and document-level queries. Compared to traditional one-dimensional search approaches like keyword search or clustering, this system improves the discoverability of information by encouraging a deeper interaction with the corpus. We demonstrate the functionality of the ClusterTalk framework based on four million PubMed abstracts for the four-year time frame.
Numbers Matter! Bringing Quantity-awareness to Retrieval Systems
Jul 14, 2024Quantitative information plays a crucial role in understanding and interpreting the content of documents. Many user queries contain quantities and cannot be resolved without understanding their semantics, e.g., ``car that costs less than $10k''. Yet, modern search engines apply the same ranking mechanisms for both words and quantities, overlooking magnitude and unit information. In this paper, we introduce two quantity-aware ranking techniques designed to rank both the quantity and textual content either jointly or independently. These techniques incorporate quantity information in available retrieval systems and can address queries with numerical conditions equal, greater than, and less than. To evaluate the effectiveness of our proposed models, we introduce two novel quantity-aware benchmark datasets in the domains of finance and medicine and compare our method against various lexical and neural models. The code and data are available under https://github.com/satya77/QuantityAwareRankers.
LexDrafter: Terminology Drafting for Legislative Documents using Retrieval Augmented Generation
Mar 24, 2024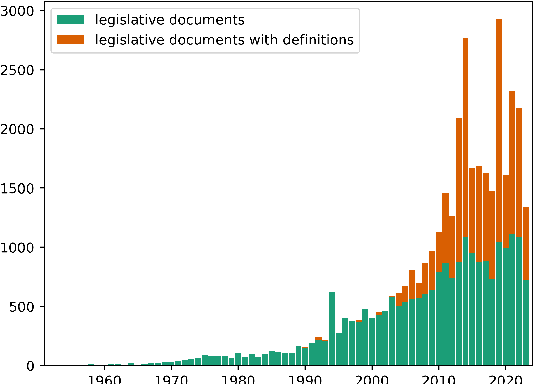
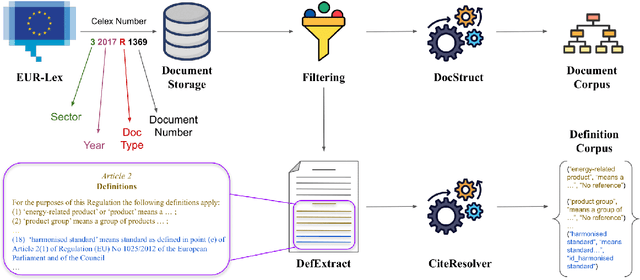
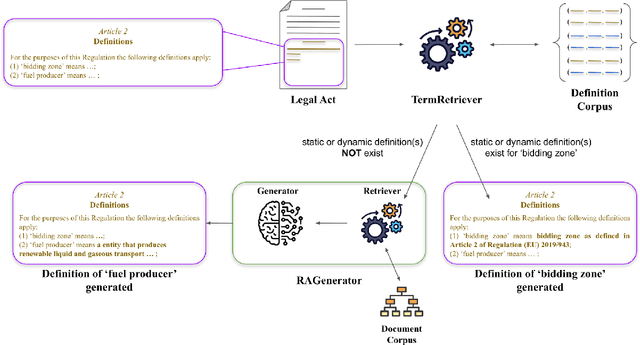
With the increase in legislative documents at the EU, the number of new terms and their definitions is increasing as well. As per the Joint Practical Guide of the European Parliament, the Council and the Commission, terms used in legal documents shall be consistent, and identical concepts shall be expressed without departing from their meaning in ordinary, legal, or technical language. Thus, while drafting a new legislative document, having a framework that provides insights about existing definitions and helps define new terms based on a document's context will support such harmonized legal definitions across different regulations and thus avoid ambiguities. In this paper, we present LexDrafter, a framework that assists in drafting Definitions articles for legislative documents using retrieval augmented generation (RAG) and existing term definitions present in different legislative documents. For this, definition elements are built by extracting definitions from existing documents. Using definition elements and RAG, a Definitions article can be suggested on demand for a legislative document that is being drafted. We demonstrate and evaluate the functionality of LexDrafter using a collection of EU documents from the energy domain. The code for LexDrafter framework is available at https://github.com/achouhan93/LexDrafter.
Evaluating Factual Consistency of Texts with Semantic Role Labeling
May 22, 2023Automated evaluation of text generation systems has recently seen increasing attention, particularly checking whether generated text stays truthful to input sources. Existing methods frequently rely on an evaluation using task-specific language models, which in turn allows for little interpretability of generated scores. We introduce SRLScore, a reference-free evaluation metric designed with text summarization in mind. Our approach generates fact tuples constructed from Semantic Role Labels, applied to both input and summary texts. A final factuality score is computed by an adjustable scoring mechanism, which allows for easy adaption of the method across domains. Correlation with human judgments on English summarization datasets shows that SRLScore is competitive with state-of-the-art methods and exhibits stable generalization across datasets without requiring further training or hyperparameter tuning. We experiment with an optional co-reference resolution step, but find that the performance boost is mostly outweighed by the additional compute required. Our metric is available online at https://github.com/heyjing/SRLScore.
CQE: A Comprehensive Quantity Extractor
May 15, 2023



Quantities are essential in documents to describe factual information. They are ubiquitous in application domains such as finance, business, medicine, and science in general. Compared to other information extraction approaches, interestingly only a few works exist that describe methods for a proper extraction and representation of quantities in text. In this paper, we present such a comprehensive quantity extraction framework from text data. It efficiently detects combinations of values and units, the behavior of a quantity (e.g., rising or falling), and the concept a quantity is associated with. Our framework makes use of dependency parsing and a dictionary of units, and it provides for a proper normalization and standardization of detected quantities. Using a novel dataset for evaluation, we show that our open source framework outperforms other systems and -- to the best of our knowledge -- is the first to detect concepts associated with identified quantities. The code and data underlying our framework are available at https://github.com/vivkaz/CQE.
On the State of German Text Summarization
Jan 17, 2023With recent advancements in the area of Natural Language Processing, the focus is slowly shifting from a purely English-centric view towards more language-specific solutions, including German. Especially practical for businesses to analyze their growing amount of textual data are text summarization systems, which transform long input documents into compressed and more digestible summary texts. In this work, we assess the particular landscape of German abstractive text summarization and investigate the reasons why practically useful solutions for abstractive text summarization are still absent in industry. Our focus is two-fold, analyzing a) training resources, and b) publicly available summarization systems. We are able to show that popular existing datasets exhibit crucial flaws in their assumptions about the original sources, which frequently leads to detrimental effects on system generalization and evaluation biases. We confirm that for the most popular training dataset, MLSUM, over 50% of the training set is unsuitable for abstractive summarization purposes. Furthermore, available systems frequently fail to compare to simple baselines, and ignore more effective and efficient extractive summarization approaches. We attribute poor evaluation quality to a variety of different factors, which are investigated in more detail in this work: A lack of qualitative (and diverse) gold data considered for training, understudied (and untreated) positional biases in some of the existing datasets, and the lack of easily accessible and streamlined pre-processing strategies or analysis tools. We provide a comprehensive assessment of available models on the cleaned datasets, and find that this can lead to a reduction of more than 20 ROUGE-1 points during evaluation. The code for dataset filtering and reproducing results can be found online at https://github.com/dennlinger/summaries
UniHD at TSAR-2022 Shared Task: Is Compute All We Need for Lexical Simplification?
Jan 05, 2023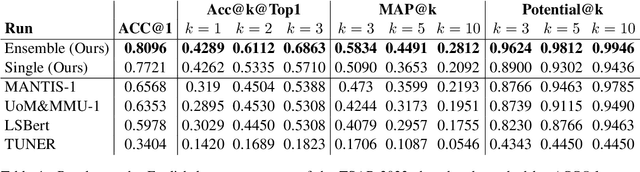

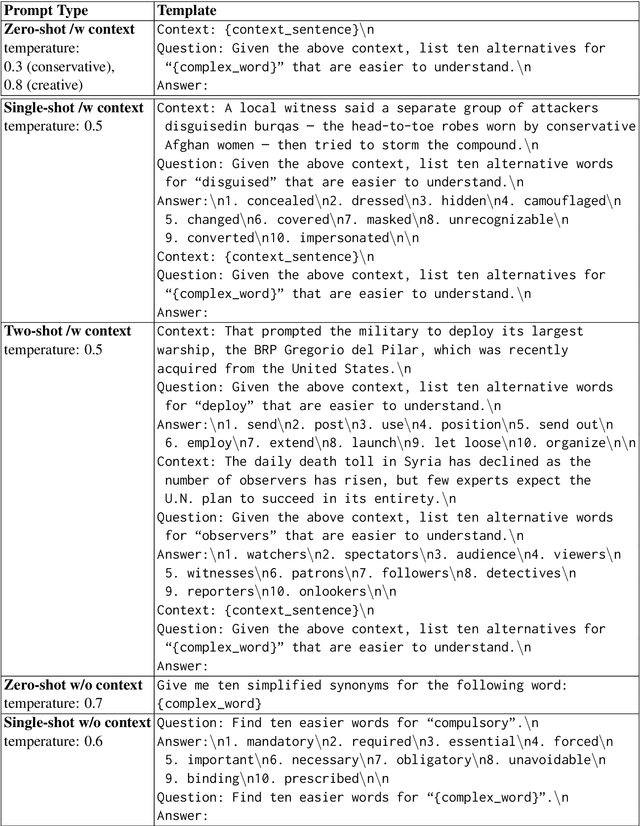
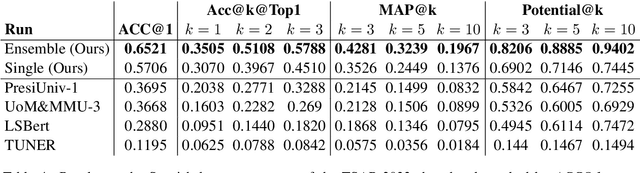
Previous state-of-the-art models for lexical simplification consist of complex pipelines with several components, each of which requires deep technical knowledge and fine-tuned interaction to achieve its full potential. As an alternative, we describe a frustratingly simple pipeline based on prompted GPT-3 responses, beating competing approaches by a wide margin in settings with few training instances. Our best-performing submission to the English language track of the TSAR-2022 shared task consists of an ``ensemble'' of six different prompt templates with varying context levels. As a late-breaking result, we further detail a language transfer technique that allows simplification in languages other than English. Applied to the Spanish and Portuguese subset, we achieve state-of-the-art results with only minor modification to the original prompts. Aside from detailing the implementation and setup, we spend the remainder of this work discussing the particularities of prompting and implications for future work. Code for the experiments is available online at https://github.com/dennlinger/TSAR-2022-Shared-Task
EUR-Lex-Sum: A Multi- and Cross-lingual Dataset for Long-form Summarization in the Legal Domain
Oct 24, 2022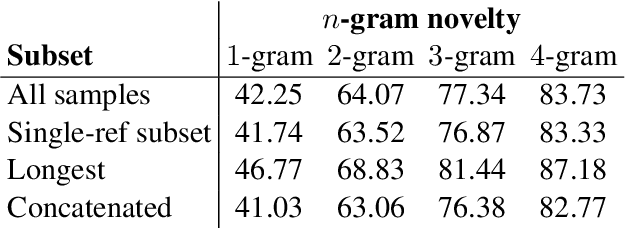

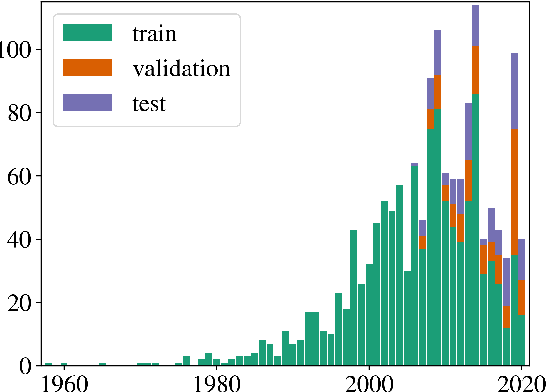

Existing summarization datasets come with two main drawbacks: (1) They tend to focus on overly exposed domains, such as news articles or wiki-like texts, and (2) are primarily monolingual, with few multilingual datasets. In this work, we propose a novel dataset, called EUR-Lex-Sum, based on manually curated document summaries of legal acts from the European Union law platform (EUR-Lex). Documents and their respective summaries exist as cross-lingual paragraph-aligned data in several of the 24 official European languages, enabling access to various cross-lingual and lower-resourced summarization setups. We obtain up to 1,500 document/summary pairs per language, including a subset of 375 cross-lingually aligned legal acts with texts available in all 24 languages. In this work, the data acquisition process is detailed and key characteristics of the resource are compared to existing summarization resources. In particular, we illustrate challenging sub-problems and open questions on the dataset that could help the facilitation of future research in the direction of domain-specific cross-lingual summarization. Limited by the extreme length and language diversity of samples, we further conduct experiments with suitable extractive monolingual and cross-lingual baselines for future work. Code for the extraction as well as access to our data and baselines is available online at: https://github.com/achouhan93/eur-lex-sum.
Klexikon: A German Dataset for Joint Summarization and Simplification
Jan 18, 2022
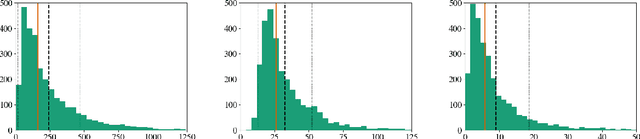
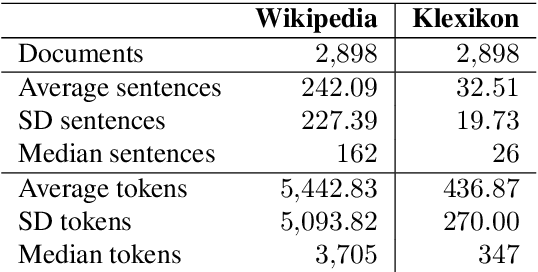
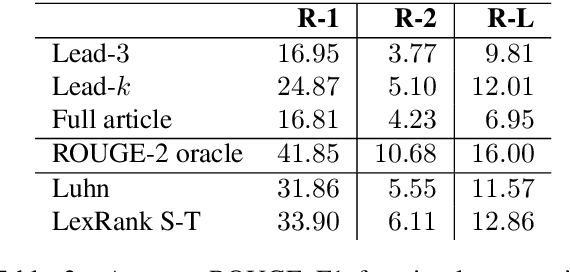
Traditionally, Text Simplification is treated as a monolingual translation task where sentences between source texts and their simplified counterparts are aligned for training. However, especially for longer input documents, summarizing the text (or dropping less relevant content altogether) plays an important role in the simplification process, which is currently not reflected in existing datasets. Simultaneously, resources for non-English languages are scarce in general and prohibitive for training new solutions. To tackle this problem, we pose core requirements for a system that can jointly summarize and simplify long source documents. We further describe the creation of a new dataset for joint Text Simplification and Summarization based on German Wikipedia and the German children's lexicon "Klexikon", consisting of almost 2900 documents. We release a document-aligned version that particularly highlights the summarization aspect, and provide statistical evidence that this resource is well suited to simplification as well. Code and data are available on Github: https://github.com/dennlinger/klexikon