 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeheiDS at ArchEHR-QA 2025: From Fixed-k to Query-dependent-k for Retrieval Augmented Generation
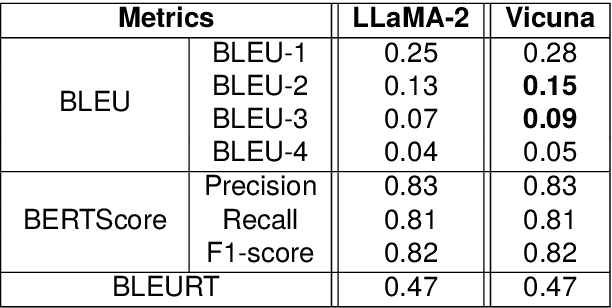
Jun 24, 2025This paper presents the approach of our team called heiDS for the ArchEHR-QA 2025 shared task. A pipeline using a retrieval augmented generation (RAG) framework is designed to generate answers that are attributed to clinical evidence from the electronic health records (EHRs) of patients in response to patient-specific questions. We explored various components of a RAG framework, focusing on ranked list truncation (RLT) retrieval strategies and attribution approaches. Instead of using a fixed top-k RLT retrieval strategy, we employ a query-dependent-k retrieval strategy, including the existing surprise and autocut methods and two new methods proposed in this work, autocut* and elbow. The experimental results show the benefits of our strategy in producing factual and relevant answers when compared to a fixed-$k$.
ClusterTalk: Corpus Exploration Framework using Multi-Dimensional Exploratory Search
Dec 19, 2024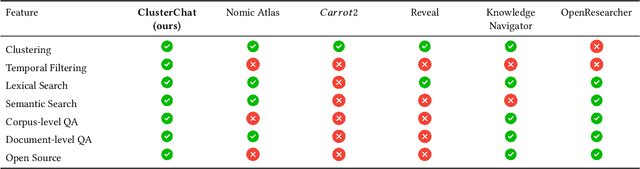
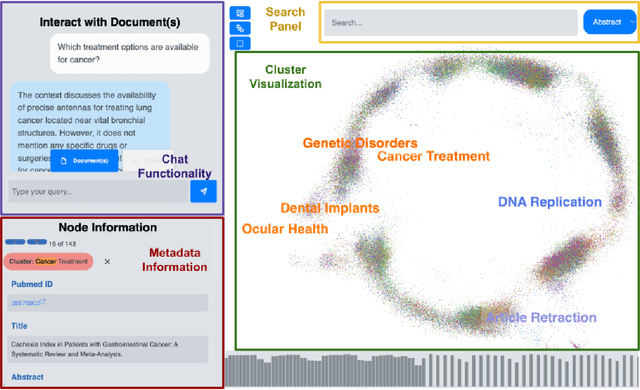
Exploratory search of large text corpora is essential in domains like biomedical research, where large amounts of research literature are continuously generated. This paper presents ClusterTalk (The demo video and source code are available at: https://github.com/achouhan93/ClusterTalk), a framework for corpus exploration using multi-dimensional exploratory search. Our system integrates document clustering with faceted search, allowing users to interactively refine their exploration and ask corpus and document-level queries. Compared to traditional one-dimensional search approaches like keyword search or clustering, this system improves the discoverability of information by encouraging a deeper interaction with the corpus. We demonstrate the functionality of the ClusterTalk framework based on four million PubMed abstracts for the four-year time frame.
LexDrafter: Terminology Drafting for Legislative Documents using Retrieval Augmented Generation
Mar 24, 2024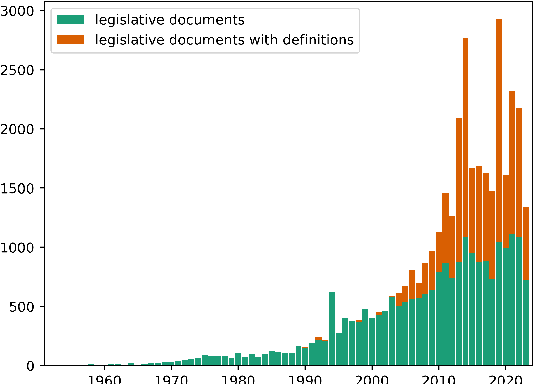
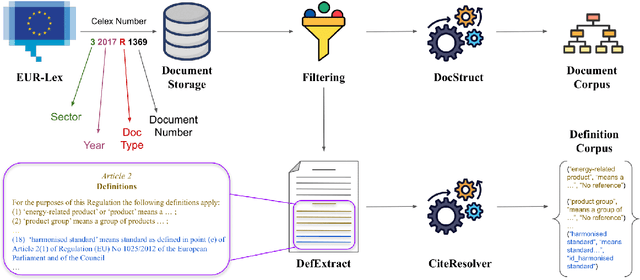
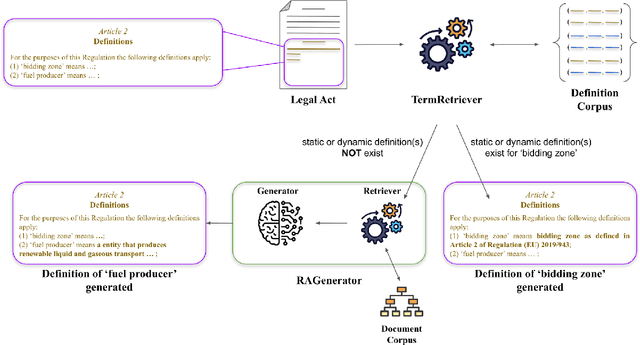
With the increase in legislative documents at the EU, the number of new terms and their definitions is increasing as well. As per the Joint Practical Guide of the European Parliament, the Council and the Commission, terms used in legal documents shall be consistent, and identical concepts shall be expressed without departing from their meaning in ordinary, legal, or technical language. Thus, while drafting a new legislative document, having a framework that provides insights about existing definitions and helps define new terms based on a document's context will support such harmonized legal definitions across different regulations and thus avoid ambiguities. In this paper, we present LexDrafter, a framework that assists in drafting Definitions articles for legislative documents using retrieval augmented generation (RAG) and existing term definitions present in different legislative documents. For this, definition elements are built by extracting definitions from existing documents. Using definition elements and RAG, a Definitions article can be suggested on demand for a legislative document that is being drafted. We demonstrate and evaluate the functionality of LexDrafter using a collection of EU documents from the energy domain. The code for LexDrafter framework is available at https://github.com/achouhan93/LexDrafter.
EUR-Lex-Sum: A Multi- and Cross-lingual Dataset for Long-form Summarization in the Legal Domain
Oct 24, 2022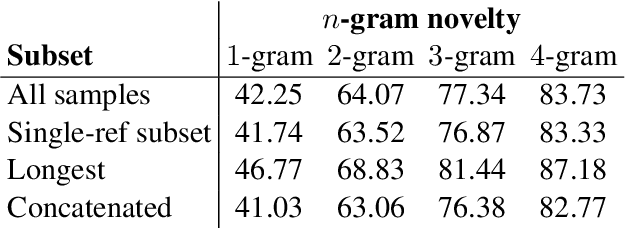


Existing summarization datasets come with two main drawbacks: (1) They tend to focus on overly exposed domains, such as news articles or wiki-like texts, and (2) are primarily monolingual, with few multilingual datasets. In this work, we propose a novel dataset, called EUR-Lex-Sum, based on manually curated document summaries of legal acts from the European Union law platform (EUR-Lex). Documents and their respective summaries exist as cross-lingual paragraph-aligned data in several of the 24 official European languages, enabling access to various cross-lingual and lower-resourced summarization setups. We obtain up to 1,500 document/summary pairs per language, including a subset of 375 cross-lingually aligned legal acts with texts available in all 24 languages. In this work, the data acquisition process is detailed and key characteristics of the resource are compared to existing summarization resources. In particular, we illustrate challenging sub-problems and open questions on the dataset that could help the facilitation of future research in the direction of domain-specific cross-lingual summarization. Limited by the extreme length and language diversity of samples, we further conduct experiments with suitable extractive monolingual and cross-lingual baselines for future work. Code for the extraction as well as access to our data and baselines is available online at: https://github.com/achouhan93/eur-lex-sum.