 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopical Change Detection in Documents via Embeddings of Long Sequences
Paper and Code
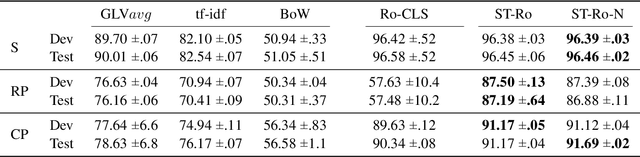
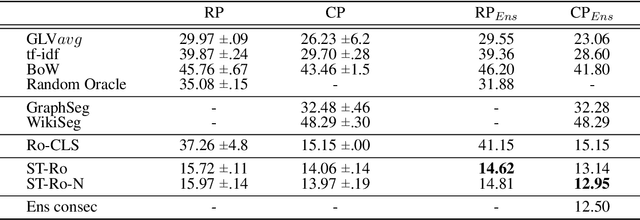

In a longer document, the topic often slightly shifts from one passage to the next, where topic boundaries are usually indicated by semantically coherent segments. Discovering this latent structure in a document improves the readability and is essential for passage retrieval and summarization tasks. We formulate the task of text segmentation as an independent supervised prediction task, making it suitable to train on Transformer-based language models. By fine-tuning on paragraphs of similar sections, we are able to show that learned features encode topic information, which can be used to find the section boundaries and divide the text into coherent segments. Unlike previous approaches, which mostly operate on sentence-level, we consistently use a broader context of an entire paragraph and assume topical independence of preceeding and succeeding text. We lastly introduce a novel large-scale dataset constructed from online Terms-of-Service documents, on which we compare against various traditional and deep learning baselines, showing significantly better performance of Transformer-based methods.