 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTradutor: Building a Variety Specific Translation Model
Feb 20, 2025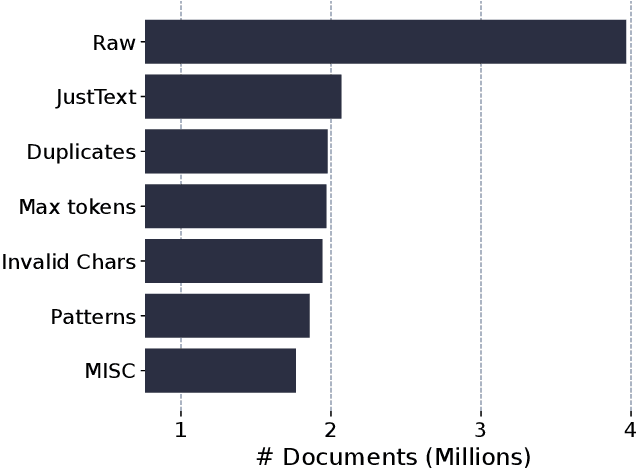
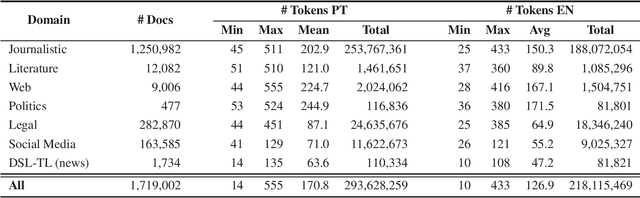
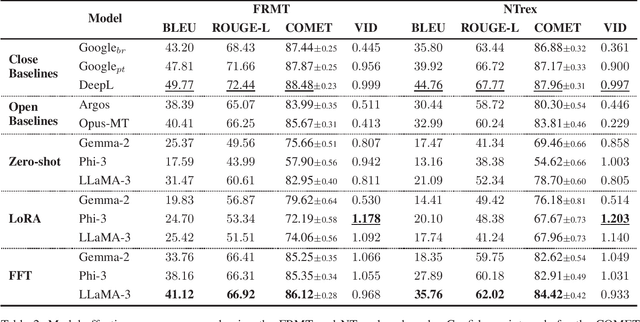
Language models have become foundational to many widely used systems. However, these seemingly advantageous models are double-edged swords. While they excel in tasks related to resource-rich languages like English, they often lose the fine nuances of language forms, dialects, and varieties that are inherent to languages spoken in multiple regions of the world. Languages like European Portuguese are neglected in favor of their more popular counterpart, Brazilian Portuguese, leading to suboptimal performance in various linguistic tasks. To address this gap, we introduce the first open-source translation model specifically tailored for European Portuguese, along with a novel dataset specifically designed for this task. Results from automatic evaluations on two benchmark datasets demonstrate that our best model surpasses existing open-source translation systems for Portuguese and approaches the performance of industry-leading closed-source systems for European Portuguese. By making our dataset, models, and code publicly available, we aim to support and encourage further research, fostering advancements in the representation of underrepresented language varieties.
Enhancing Portuguese Variety Identification with Cross-Domain Approaches
Feb 20, 2025



Recent advances in natural language processing have raised expectations for generative models to produce coherent text across diverse language varieties. In the particular case of the Portuguese language, the predominance of Brazilian Portuguese corpora online introduces linguistic biases in these models, limiting their applicability outside of Brazil. To address this gap and promote the creation of European Portuguese resources, we developed a cross-domain language variety identifier (LVI) to discriminate between European and Brazilian Portuguese. Motivated by the findings of our literature review, we compiled the PtBrVarId corpus, a cross-domain LVI dataset, and study the effectiveness of transformer-based LVI classifiers for cross-domain scenarios. Although this research focuses on two Portuguese varieties, our contribution can be extended to other varieties and languages. We open source the code, corpus, and models to foster further research in this task.
TEI2GO: A Multilingual Approach for Fast Temporal Expression Identification
Mar 25, 2024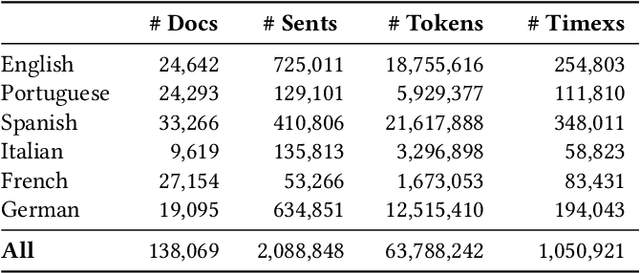
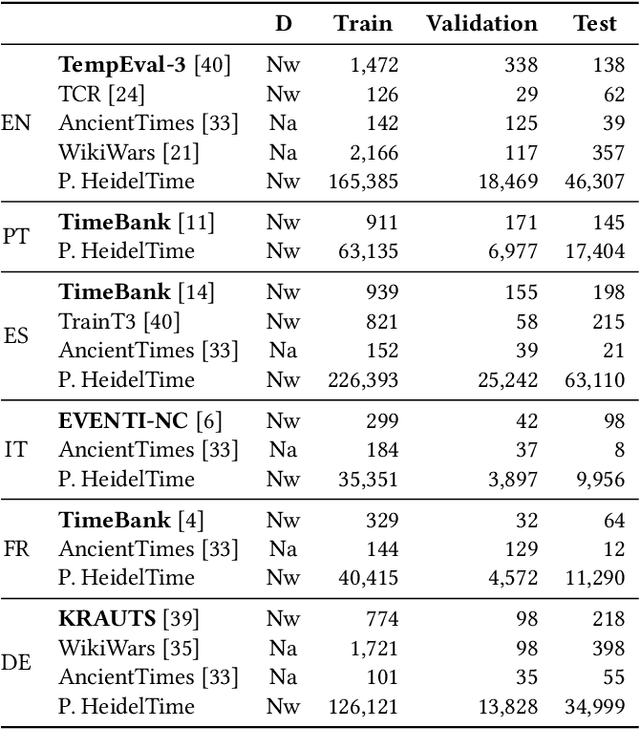
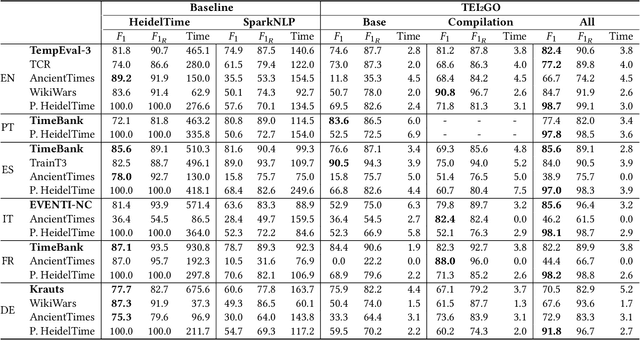
Temporal expression identification is crucial for understanding texts written in natural language. Although highly effective systems such as HeidelTime exist, their limited runtime performance hampers adoption in large-scale applications and production environments. In this paper, we introduce the TEI2GO models, matching HeidelTime's effectiveness but with significantly improved runtime, supporting six languages, and achieving state-of-the-art results in four of them. To train the TEI2GO models, we used a combination of manually annotated reference corpus and developed ``Professor HeidelTime'', a comprehensive weakly labeled corpus of news texts annotated with HeidelTime. This corpus comprises a total of $138,069$ documents (over six languages) with $1,050,921$ temporal expressions, the largest open-source annotated dataset for temporal expression identification to date. By describing how the models were produced, we aim to encourage the research community to further explore, refine, and extend the set of models to additional languages and domains. Code, annotations, and models are openly available for community exploration and use. The models are conveniently on HuggingFace for seamless integration and application.
Physio: An LLM-Based Physiotherapy Advisor
Jan 03, 2024The capabilities of the most recent language models have increased the interest in integrating them into real-world applications. However, the fact that these models generate plausible, yet incorrect text poses a constraint when considering their use in several domains. Healthcare is a prime example of a domain where text-generative trustworthiness is a hard requirement to safeguard patient well-being. In this paper, we present Physio, a chat-based application for physical rehabilitation. Physio is capable of making an initial diagnosis while citing reliable health sources to support the information provided. Furthermore, drawing upon external knowledge databases, Physio can recommend rehabilitation exercises and over-the-counter medication for symptom relief. By combining these features, Physio can leverage the power of generative models for language processing while also conditioning its response on dependable and verifiable sources. A live demo of Physio is available at https://physio.inesctec.pt.
GPT Struct Me: Probing GPT Models on Narrative Entity Extraction
Nov 24, 2023
The importance of systems that can extract structured information from textual data becomes increasingly pronounced given the ever-increasing volume of text produced on a daily basis. Having a system that can effectively extract such information in an interoperable manner would be an asset for several domains, be it finance, health, or legal. Recent developments in natural language processing led to the production of powerful language models that can, to some degree, mimic human intelligence. Such effectiveness raises a pertinent question: Can these models be leveraged for the extraction of structured information? In this work, we address this question by evaluating the capabilities of two state-of-the-art language models -- GPT-3 and GPT-3.5, commonly known as ChatGPT -- in the extraction of narrative entities, namely events, participants, and temporal expressions. This study is conducted on the Text2Story Lusa dataset, a collection of 119 Portuguese news articles whose annotation framework includes a set of entity structures along with several tags and attribute values. We first select the best prompt template through an ablation study over prompt components that provide varying degrees of information on a subset of documents of the dataset. Subsequently, we use the best templates to evaluate the effectiveness of the models on the remaining documents. The results obtained indicate that GPT models are competitive with out-of-the-box baseline systems, presenting an all-in-one alternative for practitioners with limited resources. By studying the strengths and limitations of these models in the context of information extraction, we offer insights that can guide future improvements and avenues to explore in this field.
A Biomedical Entity Extraction Pipeline for Oncology Health Records in Portuguese
Apr 18, 2023Textual health records of cancer patients are usually protracted and highly unstructured, making it very time-consuming for health professionals to get a complete overview of the patient's therapeutic course. As such limitations can lead to suboptimal and/or inefficient treatment procedures, healthcare providers would greatly benefit from a system that effectively summarizes the information of those records. With the advent of deep neural models, this objective has been partially attained for English clinical texts, however, the research community still lacks an effective solution for languages with limited resources. In this paper, we present the approach we developed to extract procedures, drugs, and diseases from oncology health records written in European Portuguese. This project was conducted in collaboration with the Portuguese Institute for Oncology which, besides holding over $10$ years of duly protected medical records, also provided oncologist expertise throughout the development of the project. Since there is no annotated corpus for biomedical entity extraction in Portuguese, we also present the strategy we followed in annotating the corpus for the development of the models. The final models, which combined a neural architecture with entity linking, achieved $F_1$ scores of $88.6$, $95.0$, and $55.8$ per cent in the mention extraction of procedures, drugs, and diseases, respectively.
tieval: An Evaluation Framework for Temporal Information Extraction Systems
Jan 11, 2023
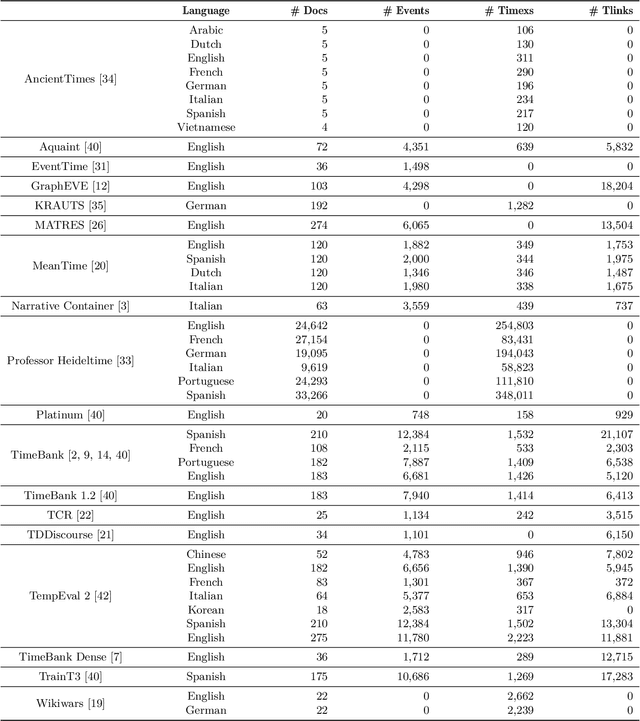


Temporal information extraction (TIE) has attracted a great deal of interest over the last two decades, leading to the development of a significant number of datasets. Despite its benefits, having access to a large volume of corpora makes it difficult when it comes to benchmark TIE systems. On the one hand, different datasets have different annotation schemes, thus hindering the comparison between competitors across different corpora. On the other hand, the fact that each corpus is commonly disseminated in a different format requires a considerable engineering effort for a researcher/practitioner to develop parsers for all of them. This constraint forces researchers to select a limited amount of datasets to evaluate their systems which consequently limits the comparability of the systems. Yet another obstacle that hinders the comparability of the TIE systems is the evaluation metric employed. While most research works adopt traditional metrics such as precision, recall, and $F_1$, a few others prefer temporal awareness -- a metric tailored to be more comprehensive on the evaluation of temporal systems. Although the reason for the absence of temporal awareness in the evaluation of most systems is not clear, one of the factors that certainly weights this decision is the necessity to implement the temporal closure algorithm in order to compute temporal awareness, which is not straightforward to implement neither is currently easily available. All in all, these problems have limited the fair comparison between approaches and consequently, the development of temporal extraction systems. To mitigate these problems, we have developed tieval, a Python library that provides a concise interface for importing different corpora and facilitates system evaluation. In this paper, we present the first public release of tieval and highlight its most relevant features.