 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunable Domain Adaptation Using Unfolding
Mar 27, 2026Machine learning models often struggle to generalize across domains with varying data distributions, such as differing noise levels, leading to degraded performance. Traditional strategies like personalized training, which trains separate models per domain, and joint training, which uses a single model for all domains, have significant limitations in flexibility and effectiveness. To address this, we propose two novel domain adaptation methods for regression tasks based on interpretable unrolled networks--deep architectures inspired by iterative optimization algorithms. These models leverage the functional dependence of select tunable parameters on domain variables, enabling controlled adaptation during inference. Our methods include Parametric Tunable-Domain Adaptation (P-TDA), which uses known domain parameters for dynamic tuning, and Data-Driven Tunable-Domain Adaptation (DD-TDA), which infers domain adaptation directly from input data. We validate our approach on compressed sensing problems involving noise-adaptive sparse signal recovery, domain-adaptive gain calibration, and domain-adaptive phase retrieval, demonstrating improved or comparable performance to domain-specific models while surpassing joint training baselines. This work highlights the potential of unrolled networks for effective, interpretable domain adaptation in regression settings.
Adaptive Non-Uniform Sampling of Bandlimited Signals via Algorithm-Encoder Co-Design
Jan 22, 2026We propose an adaptive non-uniform sampling framework for bandlimited signals based on an algorithm-encoder co-design perspective. By revisiting the convergence analysis of iterative reconstruction algorithms for non-uniform measurements, we derive a local, energy-based sufficient condition that governs reconstruction behavior as a function of the signal and derivative energies within each sampling interval. Unlike classical approaches that impose a global Nyquist-type bound on the inter-sample spacing, the proposed condition permits large gaps in slowly varying regions while enforcing denser sampling only where the signal exhibits rapid temporal variation. Building on this theoretical insight, we design a variable-bias, variable-threshold integrate-and-fire time encoding machine (VBT-IF-TEM) whose firing mechanism is explicitly shaped to enforce the derived local convergence condition. To ensure robustness, a shifted-signal formulation is introduced to suppress excessive firing in regions where the magnitude of the signal amplitude is close to zero or the local signal energy approaches zero. Using the proposed encoder, an analog signal is discretely represented by time encodings and signal averages, enabling perfect reconstruction via a standard iterative algorithm even when the local sampling rate falls below the Nyquist rate. Simulation results on synthetic signals and experiments on ultrasonic guided-wave and ECG signals demonstrate that the proposed framework achieves substantial reductions in sampling density compared to uniform sampling and conventional IF-TEMs, while maintaining accurate reconstruction. The results further highlight a controllable tradeoff between sampling density, reconstruction accuracy, and convergence behavior, which can be navigated through adaptive parameter selection.
Verifiable Deep Quantitative Group Testing
Dec 08, 2025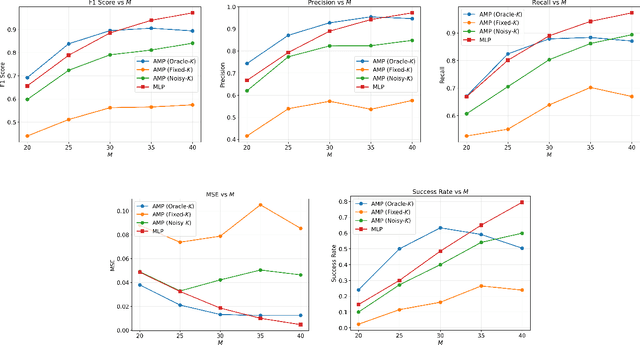
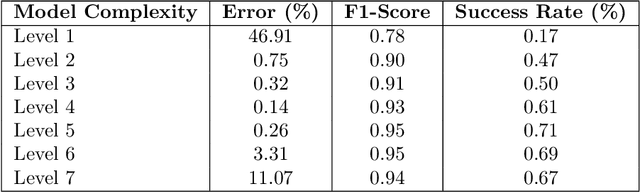
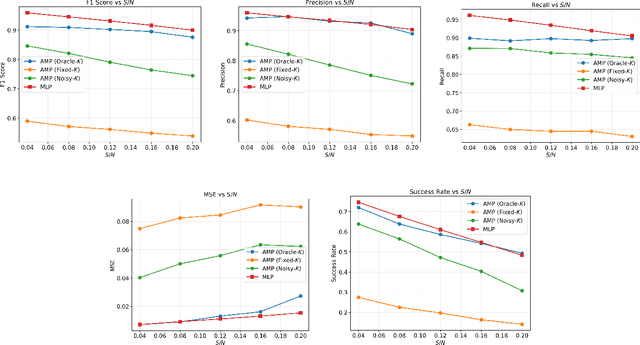
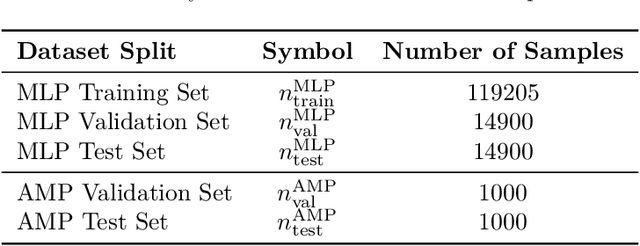
We present a neural network-based framework for solving the quantitative group testing (QGT) problem that achieves both high decoding accuracy and structural verifiability. In QGT, the objective is to identify a small subset of defective items among $N$ candidates using only $M \ll N$ pooled tests, each reporting the number of defectives in the tested subset. We train a multi-layer perceptron to map noisy measurement vectors to binary defect indicators, achieving accurate and robust recovery even under sparse, bounded perturbations. Beyond accuracy, we show that the trained network implicitly learns the underlying pooling structure that links items to tests, allowing this structure to be recovered directly from the network's Jacobian. This indicates that the model does not merely memorize training patterns but internalizes the true combinatorial relationships governing QGT. Our findings reveal that standard feedforward architectures can learn verifiable inverse mappings in structured combinatorial recovery problems.
Linear-Bias Time Encoding for Low-Rate Quantized Representation of Bandlimited Signals
Nov 12, 2025Integrate-and-fire time encoding machines (IF-TEMs) provide an efficient framework for asynchronous sampling of bandlimited signals through discrete firing times. However, conventional IF-TEMs often exhibit excessive oversampling, leading to inefficient encoding for signals with smoothly distributed information. This letter introduces a linear-bias IF-TEM (LB-IF-TEM), where the bias dynamically tracks the input signal to maintain a nearly constant integrator input, thereby localizing the firing intervals. The resulting concentrated distribution enables effective non-uniform quantization with reduced distortion. Theoretical analysis establishes explicit bounds on the achievable oversampling range, while experimental results demonstrate that the proposed method attains comparable reconstruction accuracy at significantly lower bitrate than existing IF-TEM variants. The LB-IF-TEM thus provides a low-power, communication-efficient, and analytically tractable framework for time-based signal encoding and reconstruction.
Compressed Sensing Based Residual Recovery Algorithms and Hardware for Modulo Sampling
Dec 17, 2024



Analog-to-Digital Converters (ADCs) are essential components in modern data acquisition systems. A key design challenge is accommodating high dynamic range (DR) input signals without clipping. Existing solutions, such as oversampling, automatic gain control (AGC), and compander-based methods, have limitations in handling high-DR signals. Recently, the Unlimited Sampling Framework (USF) has emerged as a promising alternative. It uses a non-linear modulo operator to map high-DR signals within the ADC range. Existing recovery algorithms, such as higher-order differences (HODs), prediction-based methods, and beyond bandwidth residual recovery (B2R2), have shown potential but are either noise-sensitive, require high sampling rates, or are computationally intensive. To address these challenges, we propose LASSO-B2R2, a fast and robust recovery algorithm. Specifically, we demonstrate that the first-order difference of the residual (the difference between the folded and original samples) is sparse, and we derive an upper bound on its sparsity. This insight allows us to formulate the recovery as a sparse signal reconstruction problem using the least absolute shrinkage and selection operator (LASSO). Numerical simulations show that LASSO-B2R2 outperforms prior methods in terms of speed and robustness, though it requires a higher sampling rate at lower DR. To overcome this, we introduce the bits distribution mechanism, which allocates 1 bit from the total bit budget to identify modulo folding events. This reduces the recovery problem to a simple pseudo-inverse computation, significantly enhancing computational efficiency. Finally, we validate our approach through numerical simulations and a hardware prototype that captures 1-bit folding information, demonstrating its practical feasibility.
Subsampling of Correlated Graph Signals
Sep 06, 2024Graph signals are functions of the underlying graph. When the edge-weight between a pair of nodes is high, the corresponding signals generally have a higher correlation. As a result, the signals can be represented in terms of a graph-based generative model. The question then arises whether measurements can be obtained on a few nodes and whether the correlation structure between the signals can be used to reconstruct the graph signal on the remaining nodes. We show that node subsampling is always possible for graph signals obtained through a generative model. Further, a method to determine the number of nodes to select is proposed based on the tolerable error. A correlation-based fast greedy algorithm is developed for selecting the nodes. Finally, we verify the proposed method on different deterministic and random graphs, and show that near-perfect reconstruction is possible with node subsampling.
Blind-Adaptive Quantizers
Sep 06, 2024



Sampling and quantization are crucial in digital signal processing, but quantization introduces errors, particularly due to distribution mismatch between input signals and quantizers. Existing methods to reduce this error require precise knowledge of the input's distribution, which is often unavailable. To address this, we propose a blind and adaptive method that minimizes distribution mismatch without prior knowledge of the input distribution. Our approach uses a nonlinear transformation with amplification and modulo-folding, followed by a uniform quantizer. Theoretical analysis shows that sufficient amplification makes the output distribution of modulo-folding nearly uniform, reducing mismatch across various distributions, including Gaussian, exponential, and uniform. To recover the true quantized samples, we suggest using existing unfolding techniques, which, despite requiring significant oversampling, effectively reduce mismatch and quantization error, offering a favorable trade-off similar to predictive coding strategies.
Power-Efficient Sampling
Dec 18, 2023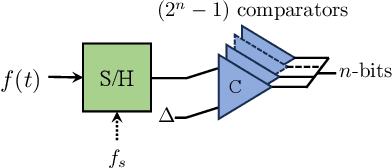

Analog-to-digital converters (ADCs) facilitate the conversion of analog signals into a digital format. While the specific designs and settings of ADCs can vary depending on their applications, it is crucial in many modern applications to minimize their power consumption. The significance of low-power ADCs is particularly evident in fields like mobile and handheld devices reliant on battery operation. Key parameters of the ADCs that dictate the ADC's power are its sampling rate, dynamic range, and number of quantization bits. Typically, these parameters are required to be higher than a threshold value but can be reduced by using the structure of the signal and by leveraging preprocessing and the system application needs. In this review, we discuss four approaches relevant to a variety of applications.
Modulation For Modulo: A Sampling-Efficient High-Dynamic Range ADC
Nov 22, 2023In high-dynamic range (HDR) analog-to-digital converters (ADCs), having many quantization bits minimizes quantization errors but results in high bit rates, limiting their application scope. A strategy combining modulo-folding with a low-DR ADC can create an efficient HDR-ADC with fewer bits. However, this typically demands oversampling, increasing the overall bit rate. An alternative method using phase modulation (PM) achieves HDR-ADC functionality by modulating the phase of a carrier signal with the analog input. This allows a low-DR ADC with fewer bits. We've derived identifiability results enabling reconstruction of the original signal from PM samples acquired at the Nyquist rate, adaptable to various signals and non-uniform sampling. Using discrete phase demodulation algorithms for practical implementation, our PM-based approach doesn't require oversampling in noise-free conditions, contrasting with modulo-based ADCs. With noise, our PM-based HDR method demonstrates efficiency with lower reconstruction errors and reduced sampling rates. Our hardware prototype illustrates reconstructing signals ten times greater than the ADC's DR from Nyquist rate samples, potentially replacing high-bit rate HDR-ADCs while meeting existing bit rate needs.
Unlabelled Sensing with Priors: Algorithm and Bounds
Sep 04, 2023



In this study, we consider a variant of unlabelled sensing where the measurements are sparsely permuted, and additionally, a few correspondences are known. We present an estimator to solve for the unknown vector. We derive a theoretical upper bound on the $\ell_2$ reconstruction error of the unknown vector. Through numerical experiments, we demonstrate that the additional known correspondences result in a significant improvement in the reconstruction error. Additionally, we compare our estimator with the classical robust regression estimator and we find that our method outperforms it on the normalized reconstruction error metric by up to $20\%$ in the high permutation regimes $(>30\%)$. Lastly, we showcase the practical utility of our framework on a non-rigid motion estimation problem. We show that using a few manually annotated points along point pairs with the key-point (SIFT-based) descriptor pairs with unknown or incorrectly known correspondences can improve motion estimation.