 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers represent belief state geometry in their residual stream
May 24, 2024What computational structure are we building into large language models when we train them on next-token prediction? Here, we present evidence that this structure is given by the meta-dynamics of belief updating over hidden states of the data-generating process. Leveraging the theory of optimal prediction, we anticipate and then find that belief states are linearly represented in the residual stream of transformers, even in cases where the predicted belief state geometry has highly nontrivial fractal structure. We investigate cases where the belief state geometry is represented in the final residual stream or distributed across the residual streams of multiple layers, providing a framework to explain these observations. Furthermore we demonstrate that the inferred belief states contain information about the entire future, beyond the local next-token prediction that the transformers are explicitly trained on. Our work provides a framework connecting the structure of training data to the computational structure and representations that transformers use to carry out their behavior.
Complexity-calibrated Benchmarks for Machine Learning Reveal When Next-Generation Reservoir Computer Predictions Succeed and Mislead
Mar 25, 2023Recurrent neural networks are used to forecast time series in finance, climate, language, and from many other domains. Reservoir computers are a particularly easily trainable form of recurrent neural network. Recently, a "next-generation" reservoir computer was introduced in which the memory trace involves only a finite number of previous symbols. We explore the inherent limitations of finite-past memory traces in this intriguing proposal. A lower bound from Fano's inequality shows that, on highly non-Markovian processes generated by large probabilistic state machines, next-generation reservoir computers with reasonably long memory traces have an error probability that is at least ~ 60% higher than the minimal attainable error probability in predicting the next observation. More generally, it appears that popular recurrent neural networks fall far short of optimally predicting such complex processes. These results highlight the need for a new generation of optimized recurrent neural network architectures. Alongside this finding, we present concentration-of-measure results for randomly-generated but complex processes. One conclusion is that large probabilistic state machines -- specifically, large $\epsilon$-machines -- are key to generating challenging and structurally-unbiased stimuli for ground-truthing recurrent neural network architectures.
Nearly Maximally Predictive Features and Their Dimensions
Feb 27, 2017
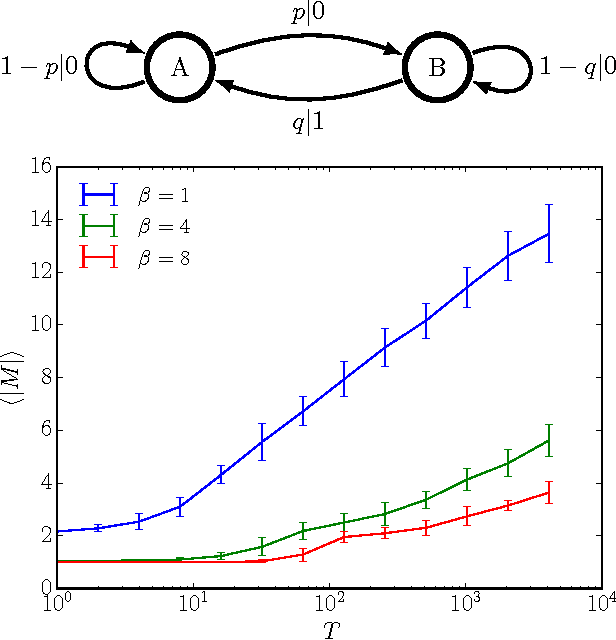
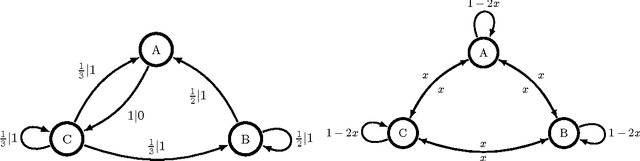
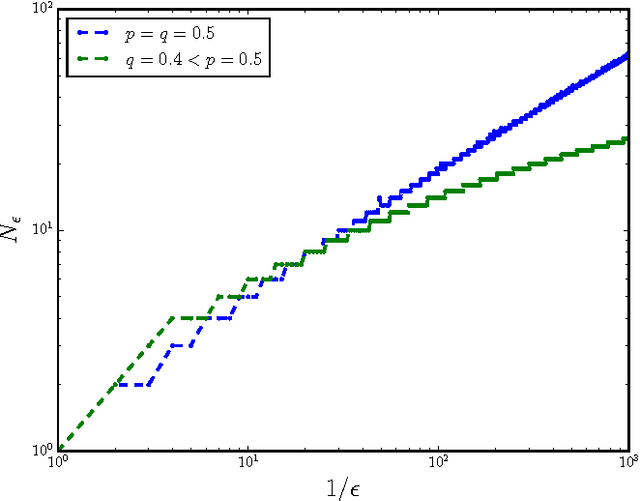
Scientific explanation often requires inferring maximally predictive features from a given data set. Unfortunately, the collection of minimal maximally predictive features for most stochastic processes is uncountably infinite. In such cases, one compromises and instead seeks nearly maximally predictive features. Here, we derive upper-bounds on the rates at which the number and the coding cost of nearly maximally predictive features scales with desired predictive power. The rates are determined by the fractal dimensions of a process' mixed-state distribution. These results, in turn, show how widely-used finite-order Markov models can fail as predictors and that mixed-state predictive features offer a substantial improvement.
* 6 pages, 2 figures; Supplementary materials, 5 pages, 1 figure; http://csc.ucdavis.edu/~cmg/compmech/pubs/nmpf.htm
Time Resolution Dependence of Information Measures for Spiking Neurons: Atoms, Scaling, and Universality
Apr 18, 2015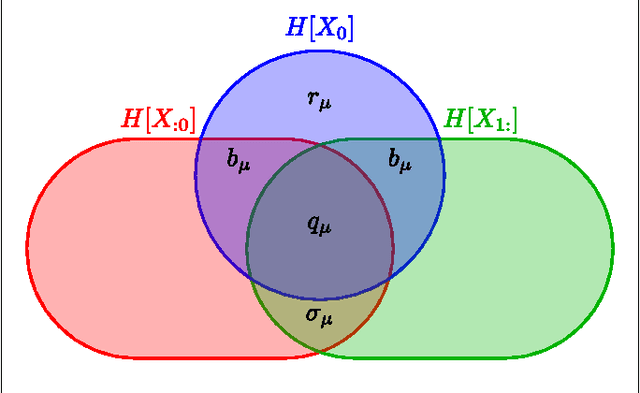
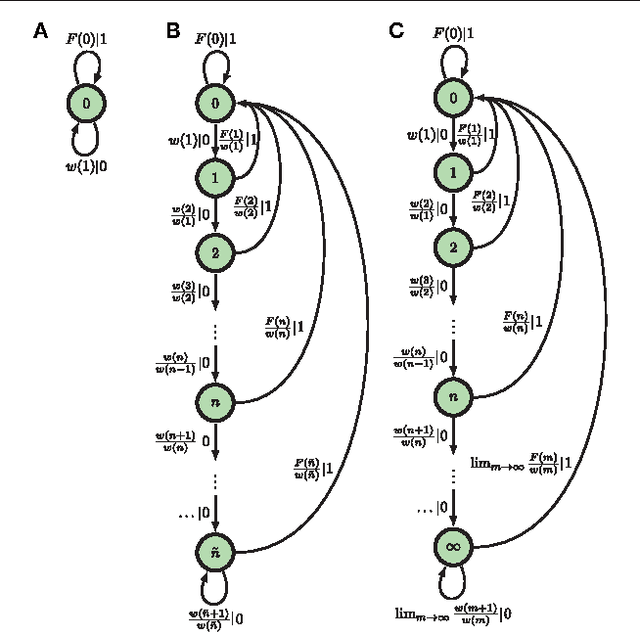
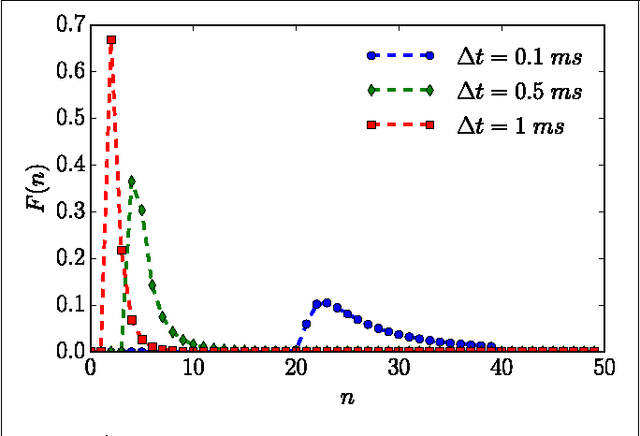
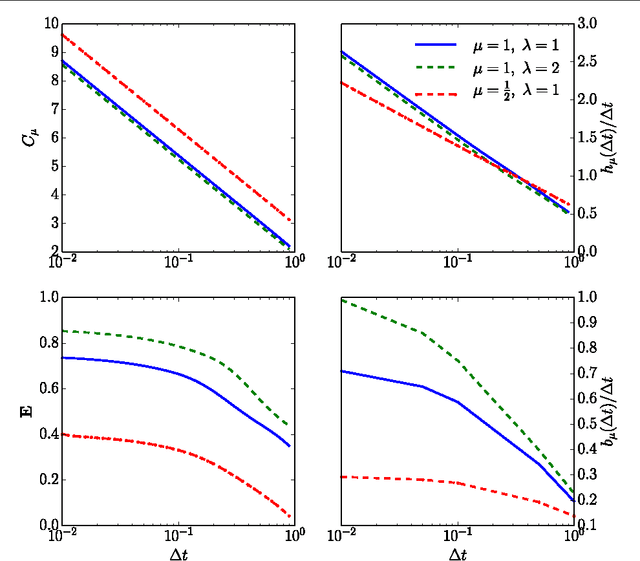
The mutual information between stimulus and spike-train response is commonly used to monitor neural coding efficiency, but neuronal computation broadly conceived requires more refined and targeted information measures of input-output joint processes. A first step towards that larger goal is to develop information measures for individual output processes, including information generation (entropy rate), stored information (statistical complexity), predictable information (excess entropy), and active information accumulation (bound information rate). We calculate these for spike trains generated by a variety of noise-driven integrate-and-fire neurons as a function of time resolution and for alternating renewal processes. We show that their time-resolution dependence reveals coarse-grained structural properties of interspike interval statistics; e.g., $\tau$-entropy rates that diverge less quickly than the firing rate indicate interspike interval correlations. We also find evidence that the excess entropy and regularized statistical complexity of different types of integrate-and-fire neurons are universal in the continuous-time limit in the sense that they do not depend on mechanism details. This suggests a surprising simplicity in the spike trains generated by these model neurons. Interestingly, neurons with gamma-distributed ISIs and neurons whose spike trains are alternating renewal processes do not fall into the same universality class. These results lead to two conclusions. First, the dependence of information measures on time resolution reveals mechanistic details about spike train generation. Second, information measures can be used as model selection tools for analyzing spike train processes.