 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional estimation with missing data: Statistical and computational limits
Mar 17, 2026We consider computationally-efficient estimation of population parameters when observations are subject to missing data. In particular, we consider estimation under the realizable contamination model of missing data in which an $ε$ fraction of the observations are subject to an arbitrary (and unknown) missing not at random (MNAR) mechanism. When the true data is Gaussian, we provide evidence towards statistical-computational gaps in several problems. For mean estimation in $\ell_2$ norm, we show that in order to obtain error at most $ρ$, for any constant contamination $ε\in (0, 1)$, (roughly) $n \gtrsim d e^{1/ρ^2}$ samples are necessary and that there is a computationally-inefficient algorithm which achieves this error. On the other hand, we show that any computationally-efficient method within certain popular families of algorithms requires a much larger sample complexity of (roughly) $n \gtrsim d^{1/ρ^2}$ and that there exists a polynomial time algorithm based on sum-of-squares which (nearly) achieves this lower bound. For covariance estimation in relative operator norm, we show that a parallel development holds. Finally, we turn to linear regression with missing observations and show that such a gap does not persist. Indeed, in this setting we show that minimizing a simple, strongly convex empirical risk nearly achieves the information-theoretic lower bound in polynomial time.
A Fast Algorithm for Adaptive Private Mean Estimation
Jan 17, 2023We design an $(\varepsilon, \delta)$-differentially private algorithm to estimate the mean of a $d$-variate distribution, with unknown covariance $\Sigma$, that is adaptive to $\Sigma$. To within polylogarithmic factors, the estimator achieves optimal rates of convergence with respect to the induced Mahalanobis norm $||\cdot||_\Sigma$, takes time $\tilde{O}(n d^2)$ to compute, has near linear sample complexity for sub-Gaussian distributions, allows $\Sigma$ to be degenerate or low rank, and adaptively extends beyond sub-Gaussianity. Prior to this work, other methods required exponential computation time or the superlinear scaling $n = \Omega(d^{3/2})$ to achieve non-trivial error with respect to the norm $||\cdot||_\Sigma$.
Undersampling is a Minimax Optimal Robustness Intervention in Nonparametric Classification
May 26, 2022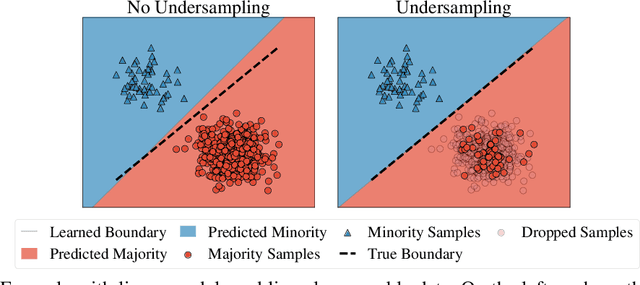
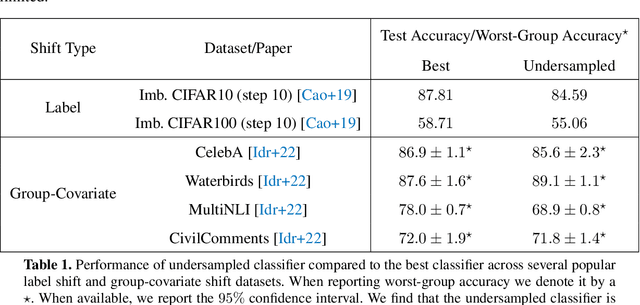
While a broad range of techniques have been proposed to tackle distribution shift, the simple baseline of training on an $\textit{undersampled}$ dataset often achieves close to state-of-the-art-accuracy across several popular benchmarks. This is rather surprising, since undersampling algorithms discard excess majority group data. To understand this phenomenon, we ask if learning is fundamentally constrained by a lack of minority group samples. We prove that this is indeed the case in the setting of nonparametric binary classification. Our results show that in the worst case, an algorithm cannot outperform undersampling unless there is a high degree of overlap between the train and test distributions (which is unlikely to be the case in real-world datasets), or if the algorithm leverages additional structure about the distribution shift. In particular, in the case of label shift we show that there is always an undersampling algorithm that is minimax optimal. While in the case of group-covariate shift we show that there is an undersampling algorithm that is minimax optimal when the overlap between the group distributions is small. We also perform an experimental case study on a label shift dataset and find that in line with our theory the test accuracy of robust neural network classifiers is constrained by the number of minority samples.
Is Importance Weighting Incompatible with Interpolating Classifiers?
Dec 24, 2021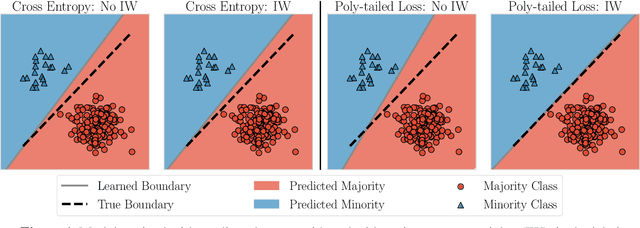
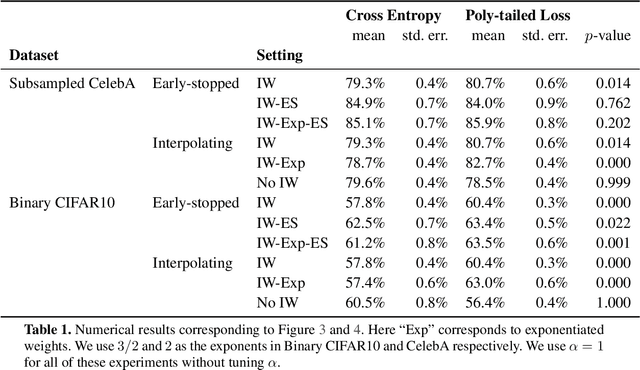
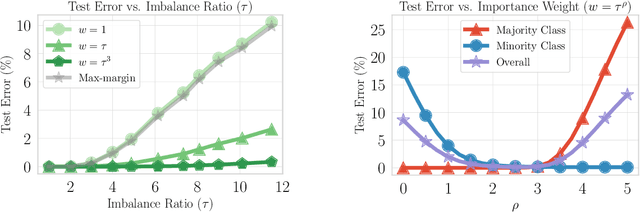
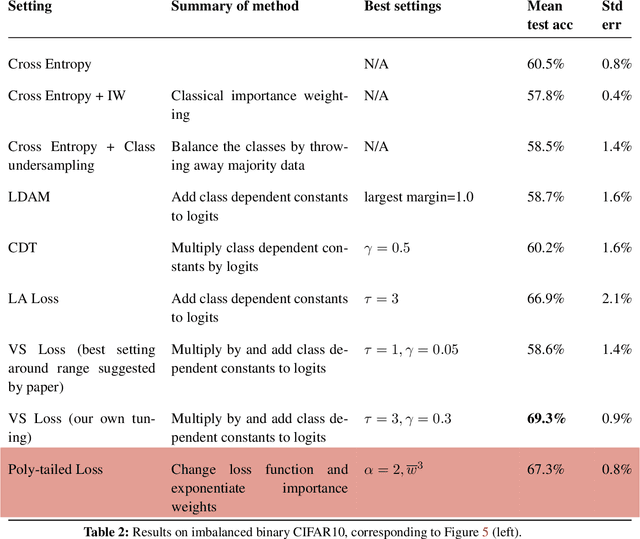
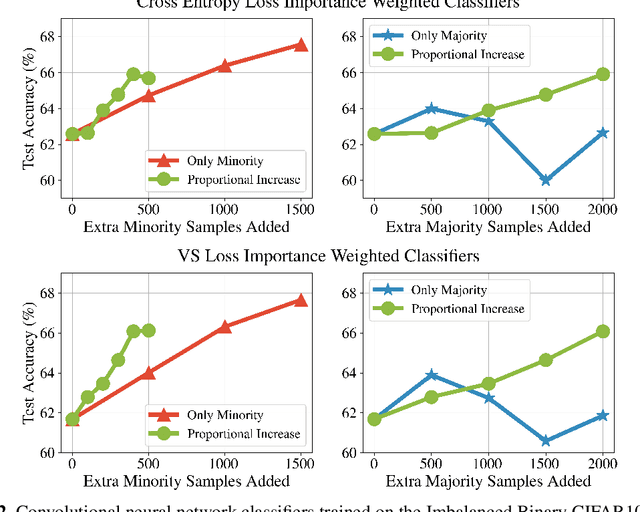
Importance weighting is a classic technique to handle distribution shifts. However, prior work has presented strong empirical and theoretical evidence demonstrating that importance weights can have little to no effect on overparameterized neural networks. Is importance weighting truly incompatible with the training of overparameterized neural networks? Our paper answers this in the negative. We show that importance weighting fails not because of the overparameterization, but instead, as a result of using exponentially-tailed losses like the logistic or cross-entropy loss. As a remedy, we show that polynomially-tailed losses restore the effects of importance reweighting in correcting distribution shift in overparameterized models. We characterize the behavior of gradient descent on importance weighted polynomially-tailed losses with overparameterized linear models, and theoretically demonstrate the advantage of using polynomially-tailed losses in a label shift setting. Surprisingly, our theory shows that using weights that are obtained by exponentiating the classical unbiased importance weights can improve performance. Finally, we demonstrate the practical value of our analysis with neural network experiments on a subpopulation shift and a label shift dataset. When reweighted, our loss function can outperform reweighted cross-entropy by as much as 9% in test accuracy. Our loss function also gives test accuracies comparable to, or even exceeding, well-tuned state-of-the-art methods for correcting distribution shifts.
Preventing Gradient Attenuation in Lipschitz Constrained Convolutional Networks
Nov 09, 2019
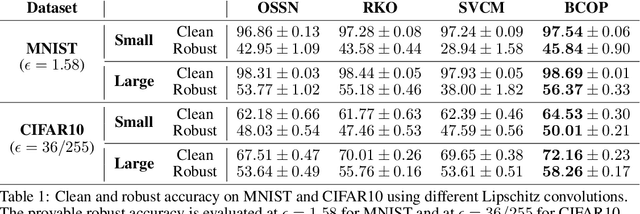
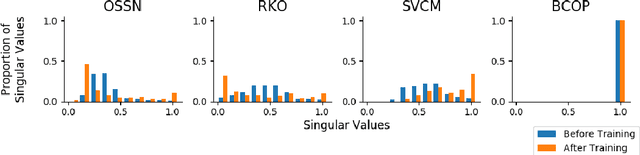

Lipschitz constraints under L2 norm on deep neural networks are useful for provable adversarial robustness bounds, stable training, and Wasserstein distance estimation. While heuristic approaches such as the gradient penalty have seen much practical success, it is challenging to achieve similar practical performance while provably enforcing a Lipschitz constraint. In principle, one can design Lipschitz constrained architectures using the composition property of Lipschitz functions, but Anil et al. recently identified a key obstacle to this approach: gradient norm attenuation. They showed how to circumvent this problem in the case of fully connected networks by designing each layer to be gradient norm preserving. We extend their approach to train scalable, expressive, provably Lipschitz convolutional networks. In particular, we present the Block Convolution Orthogonal Parameterization (BCOP), an expressive parameterization of orthogonal convolution operations. We show that even though the space of orthogonal convolutions is disconnected, the largest connected component of BCOP with 2n channels can represent arbitrary BCOP convolutions over n channels. Our BCOP parameterization allows us to train large convolutional networks with provable Lipschitz bounds. Empirically, we find that it is competitive with existing approaches to provable adversarial robustness and Wasserstein distance estimation.