 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSarc: Prosody-Aware Sarcasm Recognition Framework via Temporal Prosodic Incongruity
Jun 04, 2026We present ProSarc, an audio-only framework that detects sarcasm by modelling temporal prosodic incongruity, that is, the mismatch between local prosodic dynamics and the utterance-level emotional baseline. Dual encoding paths, a Global Emotion Encoder and a Temporal Prosody Encoder (BiLSTM + multi-head attention), feed a Prosodic Incongruity Analyzer that produces a scalar incongruity score for classification. Monte Carlo dropout provides uncertainty estimates, and an attention-based mechanism localises sarcastic onset without frame-level labels. ProSarc outperforms prior audio-only methods on MUStARD++ (F1=75.3) and generalises to spontaneous (PodSarc, F1=62.9) and cross-lingual speech (MuSaG, F1=65.6). Ten-run validation confirms the contribution of incongruity modelling (Wilcoxon p=0.002, Cohen's d=1.51). Human evaluation shows that model uncertainty tracks perceptual ambiguity and predicted onsets align with human-annotated temporal windows.
Challenges and Solutions in DeepFakes
Sep 26, 2021
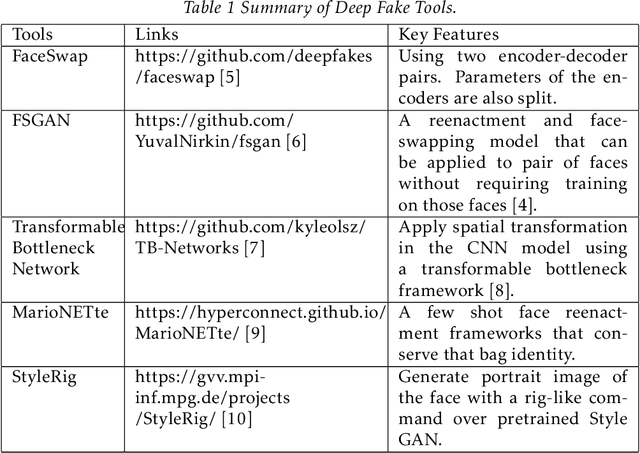

Deep learning has been successfully appertained to solve various complex problems in the area of big data analytics to computer vision. A deep learning-powered application recently emerged is Deep Fake. It helps to create fake images and videos that human cannot distinguish them from the real ones and are recent off-shelf manipulation technique that allows swapping two identities in a single video. Technology is a controversial technology with many wide-reaching issues impacting society. So, to counter this emerging problem, we introduce a dataset of 140k real and fake faces which contain 70k real faces from the Flickr dataset collected by Nvidia, as well as 70k fake faces sampled from 1 million fake faces generated by style GAN. We will train our model in the dataset so that our model can identify real or fake faces.
A Comprehensive Review on Summarizing Financial News Using Deep Learning
Sep 21, 2021



Investors make investment decisions depending on several factors such as fundamental analysis, technical analysis, and quantitative analysis. Another factor on which investors can make investment decisions is through sentiment analysis of news headlines, the sole purpose of this study. Natural Language Processing techniques are typically used to deal with such a large amount of data and get valuable information out of it. NLP algorithms convert raw text into numerical representations that machines can easily understand and interpret. This conversion can be done using various embedding techniques. In this research, embedding techniques used are BoW, TF-IDF, Word2Vec, BERT, GloVe, and FastText, and then fed to deep learning models such as RNN and LSTM. This work aims to evaluate these model's performance to choose the robust model in identifying the significant factors influencing the prediction. During this research, it was expected that Deep Leaming would be applied to get the desired results or achieve better accuracy than the state-of-the-art. The models are compared to check their outputs to know which one has performed better.
WAD: A Deep Reinforcement Learning Agent for Urban Autonomous Driving
Aug 27, 2021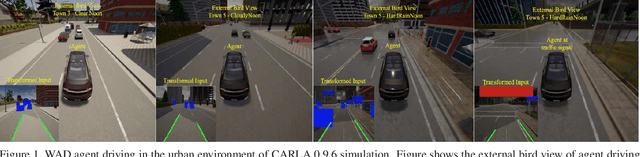
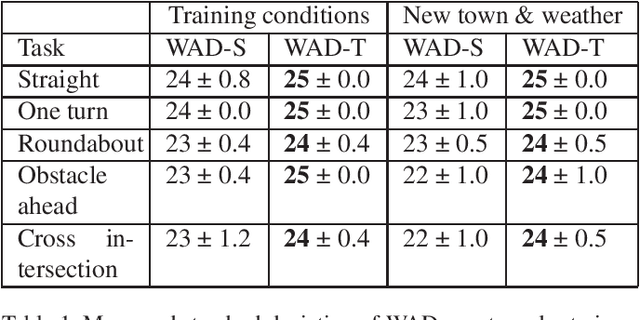
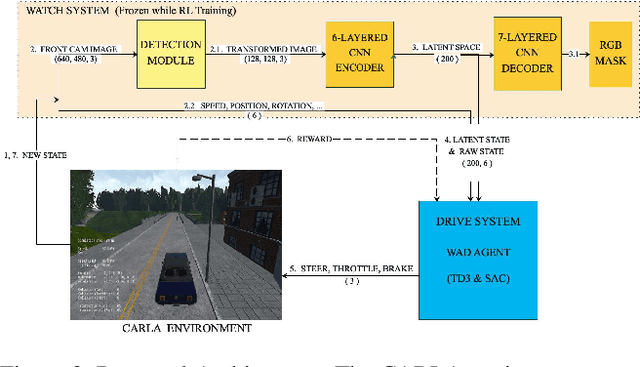

Urban autonomous driving is an open and challenging problem to solve as the decision-making system has to account for several dynamic factors like multi-agent interactions, diverse scene perceptions, complex road geometries, and other rarely occurring real-world events. On the other side, with deep reinforcement learning (DRL) techniques, agents have learned many complex policies. They have even achieved super-human-level performances in various Atari Games and Deepmind's AlphaGo. However, current DRL techniques do not generalize well on complex urban driving scenarios. This paper introduces the DRL driven Watch and Drive (WAD) agent for end-to-end urban autonomous driving. Motivated by recent advancements, the study aims to detect important objects/states in high dimensional spaces of CARLA and extract the latent state from them. Further, passing on the latent state information to WAD agents based on TD3 and SAC methods to learn the optimal driving policy. Our novel approach utilizing fewer resources, step-by-step learning of different driving tasks, hard episode termination policy, and reward mechanism has led our agents to achieve a 100% success rate on all driving tasks in the original CARLA benchmark and set a new record of 82% on further complex NoCrash benchmark, outperforming the state-of-the-art model by more than +30% on NoCrash benchmark.
Content Based Image Retrieval from AWiFS Images Repository of IRS Resourcesat-2 Satellite Based on Water Bodies and Burnt Areas
Sep 26, 2018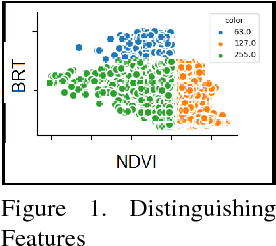
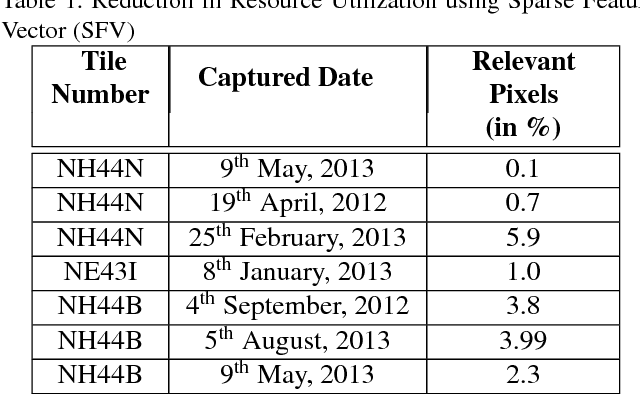
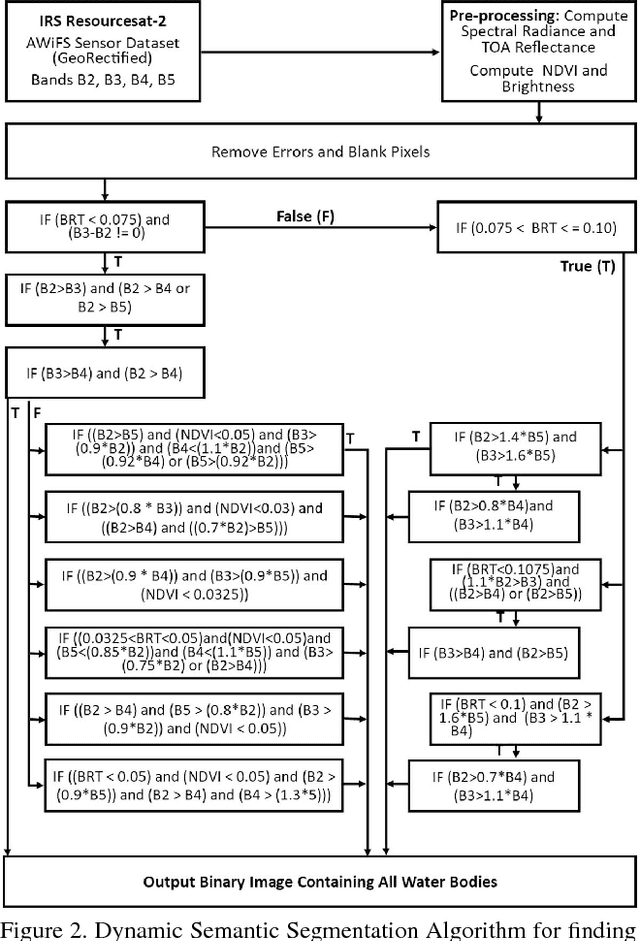

Satellite Remote Sensing Technology is becoming a major milestone in the prediction of weather anomalies, natural disasters as well as finding alternative resources in proximity using multiple multi-spectral sensors emitting electromagnetic waves at distinct wavelengths. Hence, it is imperative to extract water bodies and burnt areas from orthorectified tiles and correspondingly rank them using similarity measures. Different objects in all the spheres of the earth have the inherent capability of absorbing electromagnetic waves of distant wavelengths. This creates various unique masks in terms of reflectance on the receptor. We propose Dynamic Semantic Segmentation (DSS) algorithms that utilized the mentioned capability to extract and rank Advanced Wide Field Sensor (AWiFS) images according to various features. This system stores data intelligently in the form of a sparse feature vector which drastically mitigates the computational and spatial costs incurred for further analysis. The compressed source image is divided into chunks and stored in the database for quicker retrieval. This work is intended to utilize readily available and cost effective resources like AWiFS dataset instead of depending on advanced technologies like Moderate Resolution Imaging Spectroradiometer (MODIS) for data which is scarce.
Learning to Mix n-Step Returns: Generalizing lambda-Returns for Deep Reinforcement Learning
Nov 05, 2017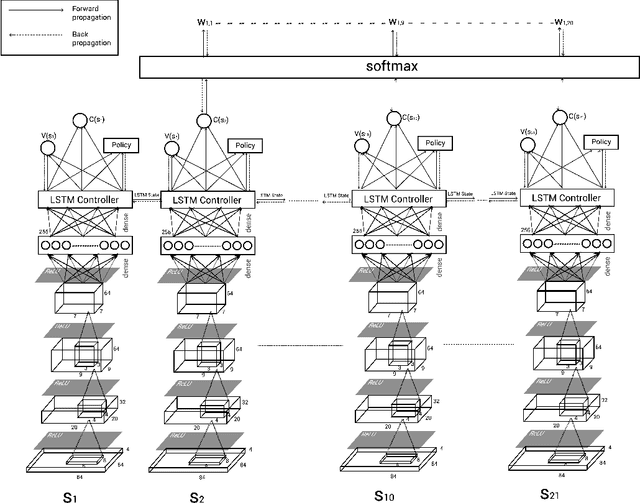
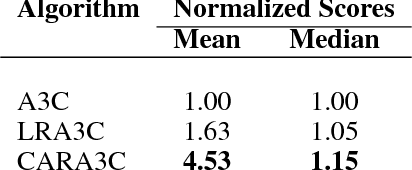

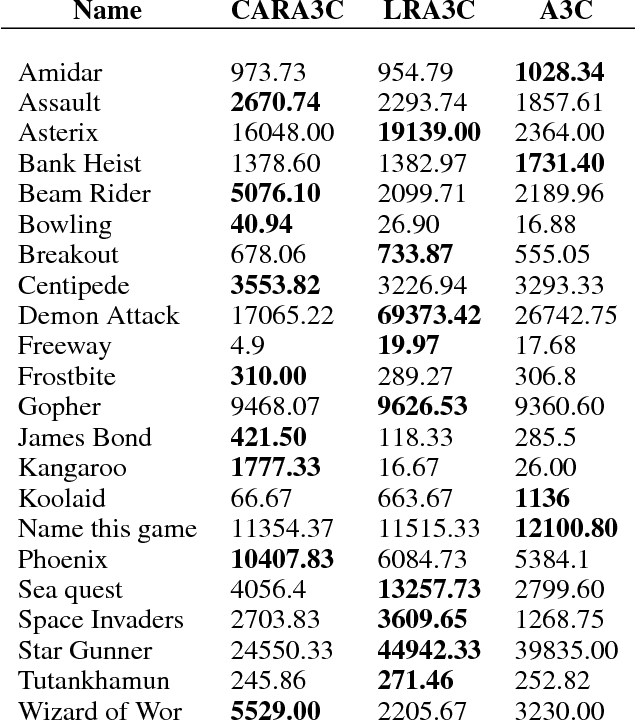
Reinforcement Learning (RL) can model complex behavior policies for goal-directed sequential decision making tasks. A hallmark of RL algorithms is Temporal Difference (TD) learning: value function for the current state is moved towards a bootstrapped target that is estimated using next state's value function. $\lambda$-returns generalize beyond 1-step returns and strike a balance between Monte Carlo and TD learning methods. While lambda-returns have been extensively studied in RL, they haven't been explored a lot in Deep RL. This paper's first contribution is an exhaustive benchmarking of lambda-returns. Although mathematically tractable, the use of exponentially decaying weighting of n-step returns based targets in lambda-returns is a rather ad-hoc design choice. Our second major contribution is that we propose a generalization of lambda-returns called Confidence-based Autodidactic Returns (CAR), wherein the RL agent learns the weighting of the n-step returns in an end-to-end manner. This allows the agent to learn to decide how much it wants to weigh the n-step returns based targets. In contrast, lambda-returns restrict RL agents to use an exponentially decaying weighting scheme. Autodidactic returns can be used for improving any RL algorithm which uses TD learning. We empirically demonstrate that using sophisticated weighted mixtures of multi-step returns (like CAR and lambda-returns) considerably outperforms the use of n-step returns. We perform our experiments on the Asynchronous Advantage Actor Critic (A3C) algorithm in the Atari 2600 domain.
Learning to Multi-Task by Active Sampling
May 21, 2017
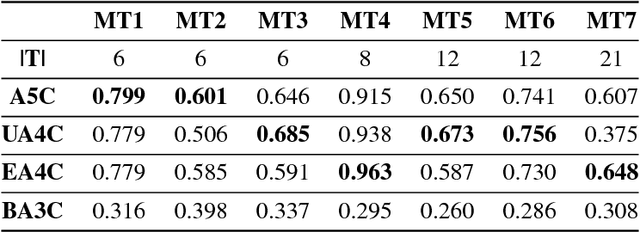
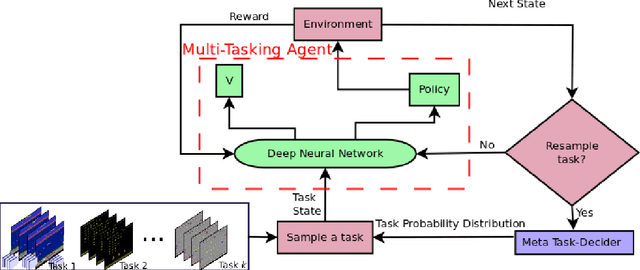
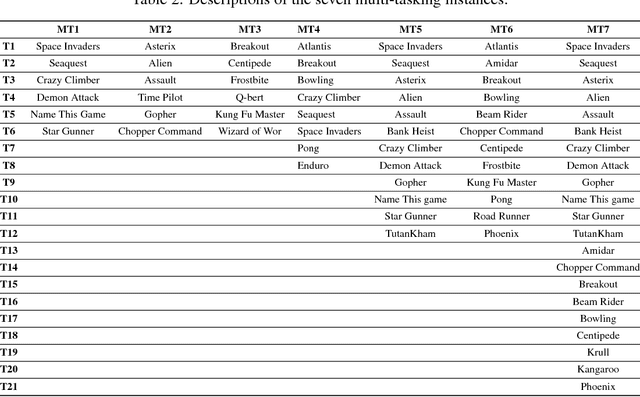
One of the long-standing challenges in Artificial Intelligence for learning goal-directed behavior is to build a single agent which can solve multiple tasks. Recent progress in multi-task learning for goal-directed sequential problems has been in the form of distillation based learning wherein a student network learns from multiple task-specific expert networks by mimicking the task-specific policies of the expert networks. While such approaches offer a promising solution to the multi-task learning problem, they require supervision from large expert networks which require extensive data and computation time for training. In this work, we propose an efficient multi-task learning framework which solves multiple goal-directed tasks in an on-line setup without the need for expert supervision. Our work uses active learning principles to achieve multi-task learning by sampling the harder tasks more than the easier ones. We propose three distinct models under our active sampling framework. An adaptive method with extremely competitive multi-tasking performance. A UCB-based meta-learner which casts the problem of picking the next task to train on as a multi-armed bandit problem. A meta-learning method that casts the next-task picking problem as a full Reinforcement Learning problem and uses actor critic methods for optimizing the multi-tasking performance directly. We demonstrate results in the Atari 2600 domain on seven multi-tasking instances: three 6-task instances, one 8-task instance, two 12-task instances and one 21-task instance.
Learning to Factor Policies and Action-Value Functions: Factored Action Space Representations for Deep Reinforcement learning
May 20, 2017
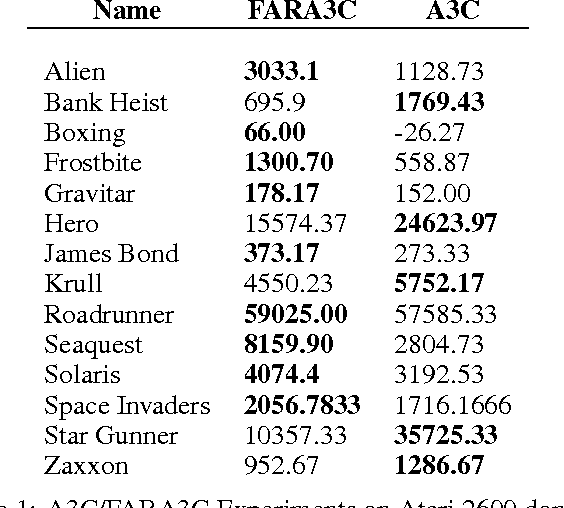
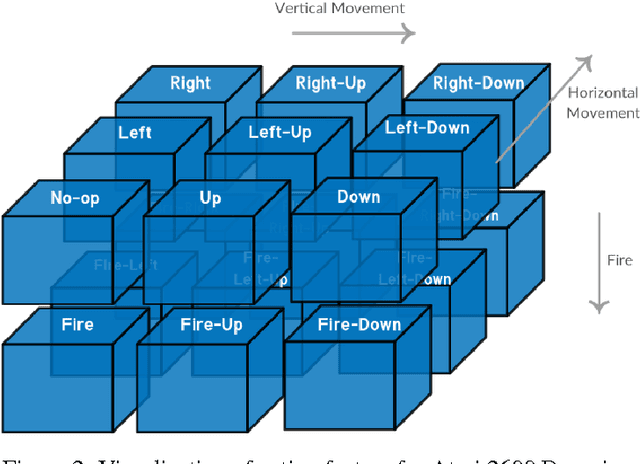

Deep Reinforcement Learning (DRL) methods have performed well in an increasing numbering of high-dimensional visual decision making domains. Among all such visual decision making problems, those with discrete action spaces often tend to have underlying compositional structure in the said action space. Such action spaces often contain actions such as go left, go up as well as go diagonally up and left (which is a composition of the former two actions). The representations of control policies in such domains have traditionally been modeled without exploiting this inherent compositional structure in the action spaces. We propose a new learning paradigm, Factored Action space Representations (FAR) wherein we decompose a control policy learned using a Deep Reinforcement Learning Algorithm into independent components, analogous to decomposing a vector in terms of some orthogonal basis vectors. This architectural modification of the control policy representation allows the agent to learn about multiple actions simultaneously, while executing only one of them. We demonstrate that FAR yields considerable improvements on top of two DRL algorithms in Atari 2600: FARA3C outperforms A3C (Asynchronous Advantage Actor Critic) in 9 out of 14 tasks and FARAQL outperforms AQL (Asynchronous n-step Q-Learning) in 9 out of 13 tasks.
Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning
Feb 20, 2017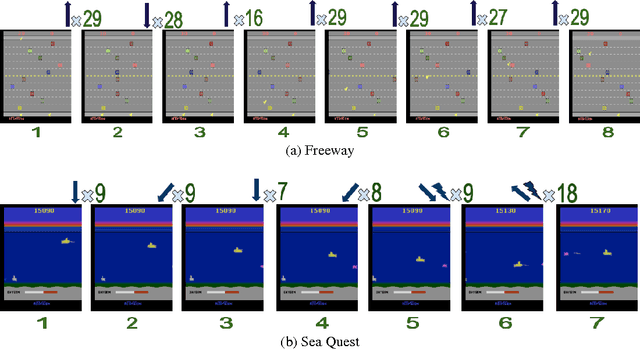


Reinforcement Learning algorithms can learn complex behavioral patterns for sequential decision making tasks wherein an agent interacts with an environment and acquires feedback in the form of rewards sampled from it. Traditionally, such algorithms make decisions, i.e., select actions to execute, at every single time step of the agent-environment interactions. In this paper, we propose a novel framework, Fine Grained Action Repetition (FiGAR), which enables the agent to decide the action as well as the time scale of repeating it. FiGAR can be used for improving any Deep Reinforcement Learning algorithm which maintains an explicit policy estimate by enabling temporal abstractions in the action space. We empirically demonstrate the efficacy of our framework by showing performance improvements on top of three policy search algorithms in different domains: Asynchronous Advantage Actor Critic in the Atari 2600 domain, Trust Region Policy Optimization in Mujoco domain and Deep Deterministic Policy Gradients in the TORCS car racing domain.
Performance Based Evaluation of Various Machine Learning Classification Techniques for Chronic Kidney Disease Diagnosis
Jul 18, 2016



Areas where Artificial Intelligence (AI) & related fields are finding their applications are increasing day by day, moving from core areas of computer science they are finding their applications in various other domains.In recent times Machine Learning i.e. a sub-domain of AI has been widely used in order to assist medical experts and doctors in the prediction, diagnosis and prognosis of various diseases and other medical disorders. In this manuscript the authors applied various machine learning algorithms to a problem in the domain of medical diagnosis and analyzed their efficiency in predicting the results. The problem selected for the study is the diagnosis of the Chronic Kidney Disease.The dataset used for the study consists of 400 instances and 24 attributes. The authors evaluated 12 classification techniques by applying them to the Chronic Kidney Disease data. In order to calculate efficiency, results of the prediction by candidate methods were compared with the actual medical results of the subject.The various metrics used for performance evaluation are predictive accuracy, precision, sensitivity and specificity. The results indicate that decision-tree performed best with nearly the accuracy of 98.6%, sensitivity of 0.9720, precision of 1 and specificity of 1.
* 6 pages, 4 figures, 2 tables