 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend, Adapt and Transfer: Attentive Deep Architecture for Adaptive Transfer from multiple sources in the same domain
Apr 18, 2017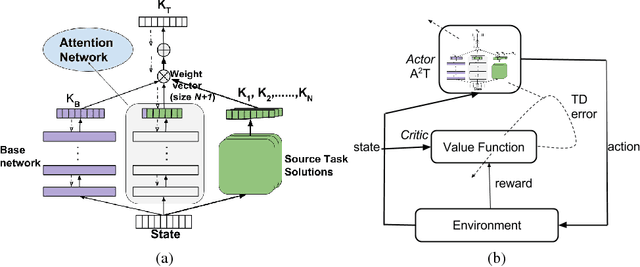
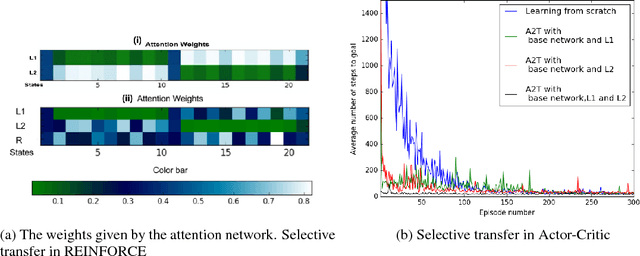

Transferring knowledge from prior source tasks in solving a new target task can be useful in several learning applications. The application of transfer poses two serious challenges which have not been adequately addressed. First, the agent should be able to avoid negative transfer, which happens when the transfer hampers or slows down the learning instead of helping it. Second, the agent should be able to selectively transfer, which is the ability to select and transfer from different and multiple source tasks for different parts of the state space of the target task. We propose A2T (Attend, Adapt and Transfer), an attentive deep architecture which adapts and transfers from these source tasks. Our model is generic enough to effect transfer of either policies or value functions. Empirical evaluations on different learning algorithms show that A2T is an effective architecture for transfer by being able to avoid negative transfer while transferring selectively from multiple source tasks in the same domain.
Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning
Feb 20, 2017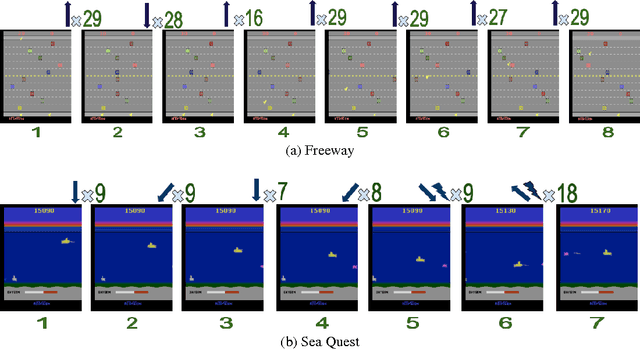


Reinforcement Learning algorithms can learn complex behavioral patterns for sequential decision making tasks wherein an agent interacts with an environment and acquires feedback in the form of rewards sampled from it. Traditionally, such algorithms make decisions, i.e., select actions to execute, at every single time step of the agent-environment interactions. In this paper, we propose a novel framework, Fine Grained Action Repetition (FiGAR), which enables the agent to decide the action as well as the time scale of repeating it. FiGAR can be used for improving any Deep Reinforcement Learning algorithm which maintains an explicit policy estimate by enabling temporal abstractions in the action space. We empirically demonstrate the efficacy of our framework by showing performance improvements on top of three policy search algorithms in different domains: Asynchronous Advantage Actor Critic in the Atari 2600 domain, Trust Region Policy Optimization in Mujoco domain and Deep Deterministic Policy Gradients in the TORCS car racing domain.
Option Discovery in Hierarchical Reinforcement Learning using Spatio-Temporal Clustering
Sep 20, 2016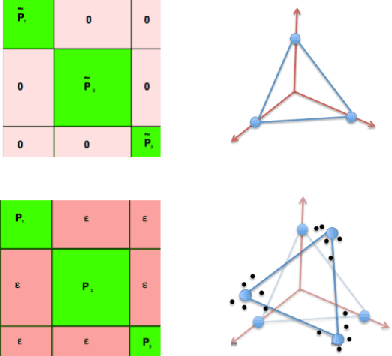

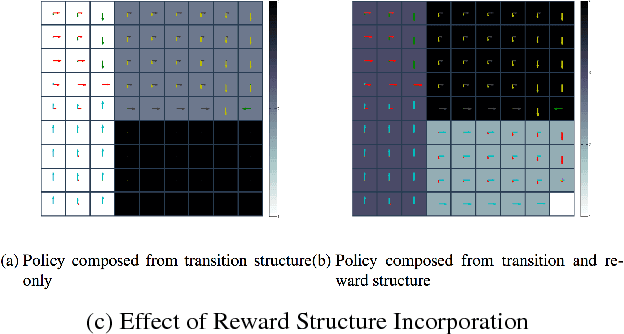
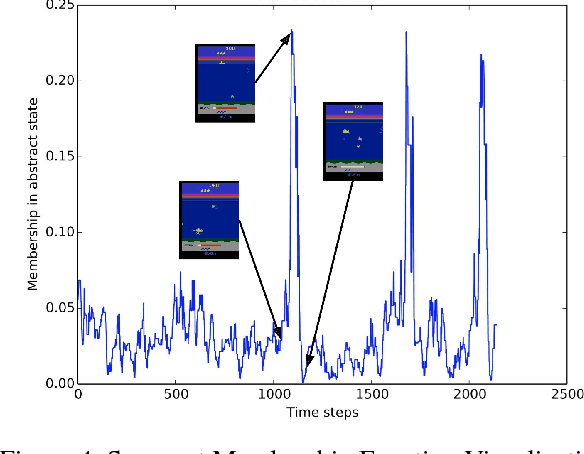
This paper introduces an automated skill acquisition framework in reinforcement learning which involves identifying a hierarchical description of the given task in terms of abstract states and extended actions between abstract states. Identifying such structures present in the task provides ways to simplify and speed up reinforcement learning algorithms. These structures also help to generalize such algorithms over multiple tasks without relearning policies from scratch. We use ideas from dynamical systems to find metastable regions in the state space and associate them with abstract states. The spectral clustering algorithm PCCA+ is used to identify suitable abstractions aligned to the underlying structure. Skills are defined in terms of the sequence of actions that lead to transitions between such abstract states. The connectivity information from PCCA+ is used to generate these skills or options. These skills are independent of the learning task and can be efficiently reused across a variety of tasks defined over the same model. This approach works well even without the exact model of the environment by using sample trajectories to construct an approximate estimate. We also present our approach to scaling the skill acquisition framework to complex tasks with large state spaces for which we perform state aggregation using the representation learned from an action conditional video prediction network and use the skill acquisition framework on the aggregated state space.
Dynamic Frame skip Deep Q Network
Jun 11, 2016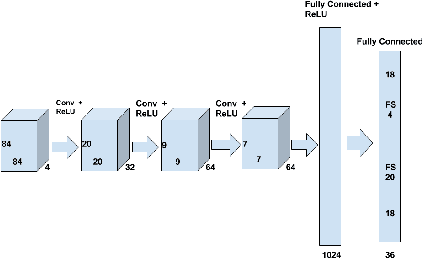
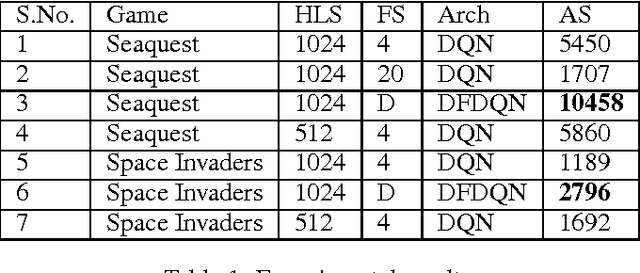
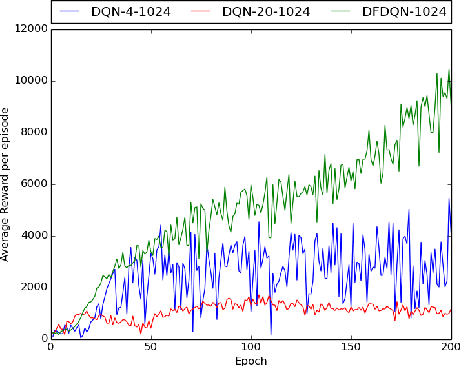
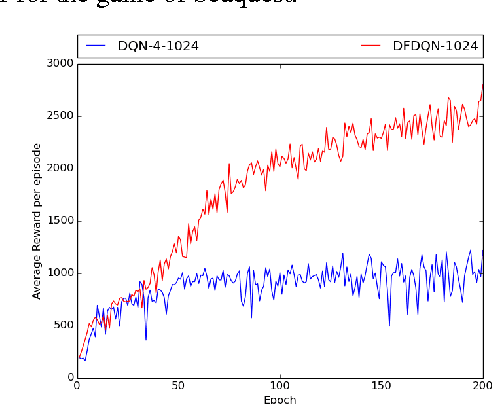
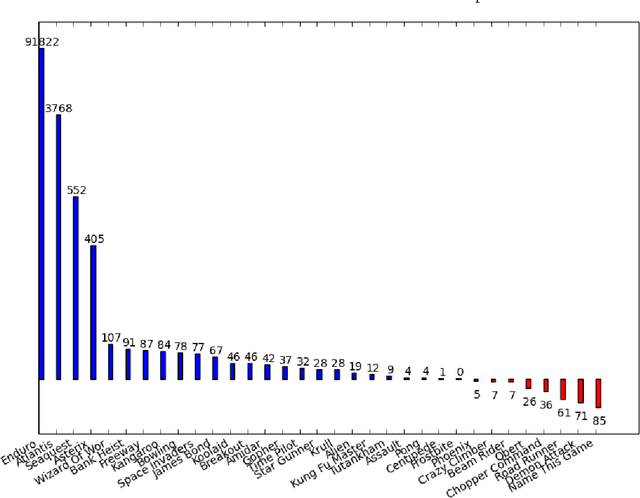
Deep Reinforcement Learning methods have achieved state of the art performance in learning control policies for the games in the Atari 2600 domain. One of the important parameters in the Arcade Learning Environment (ALE) is the frame skip rate. It decides the granularity at which agents can control game play. A frame skip value of $k$ allows the agent to repeat a selected action $k$ number of times. The current state of the art architectures like Deep Q-Network (DQN) and Dueling Network Architectures (DuDQN) consist of a framework with a static frame skip rate, where the action output from the network is repeated for a fixed number of frames regardless of the current state. In this paper, we propose a new architecture, Dynamic Frame skip Deep Q-Network (DFDQN) which makes the frame skip rate a dynamic learnable parameter. This allows us to choose the number of times an action is to be repeated based on the current state. We show empirically that such a setting improves the performance on relatively harder games like Seaquest.