 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovements on Hindsight Learning
Nov 04, 2018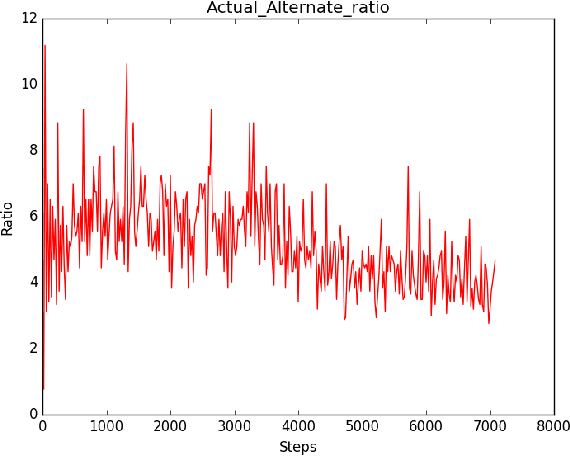
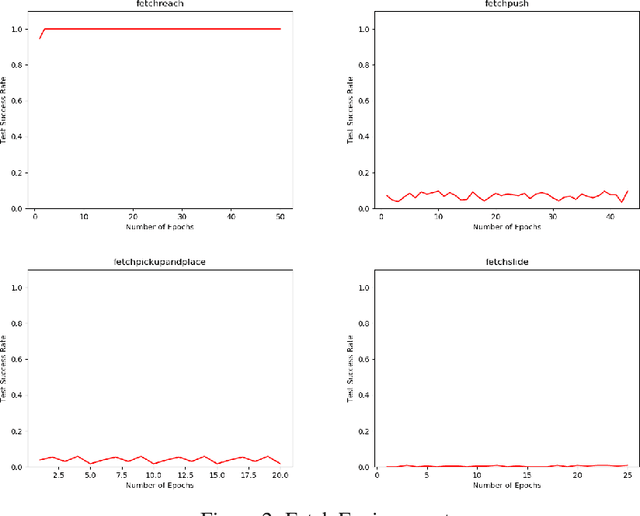
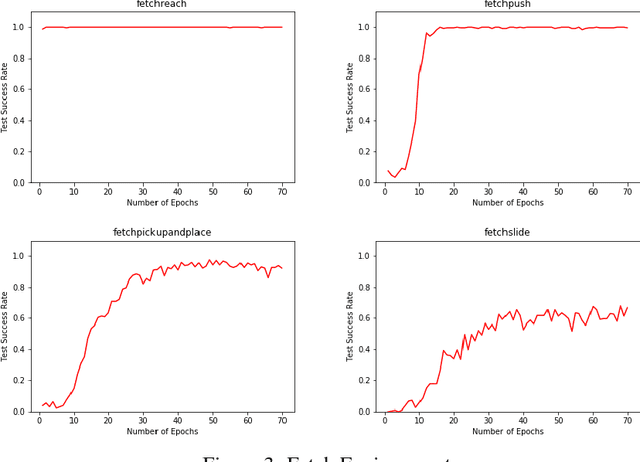
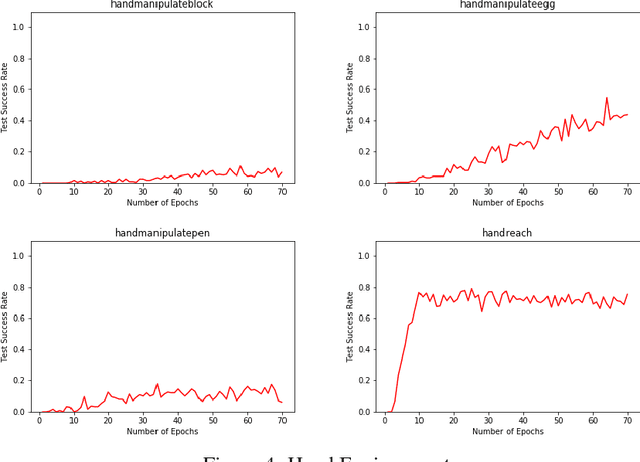
Sparse reward problems are one of the biggest challenges in Reinforcement Learning. Goal-directed tasks are one such sparse reward problems where a reward signal is received only when the goal is reached. One promising way to train an agent to perform goal-directed tasks is to use Hindsight Learning approaches. In these approaches, even when an agent fails to reach the desired goal, the agent learns to reach the goal it achieved instead. Doing this over multiple trajectories while generalizing the policy learned from the achieved goals, the agent learns a goal conditioned policy to reach any goal. One such approach is Hindsight Experience replay which uses an off-policy Reinforcement Learning algorithm to learn a goal conditioned policy. In this approach, a replay of the past transitions happens in a uniformly random fashion. Another approach is to use a Hindsight version of the policy gradients to directly learn a policy. In this work, we discuss different ways to replay past transitions to improve learning in hindsight experience replay focusing on prioritized variants in particular. Also, we implement the Hindsight Policy gradient methods to robotic tasks.
Learning to Multi-Task by Active Sampling
May 21, 2017
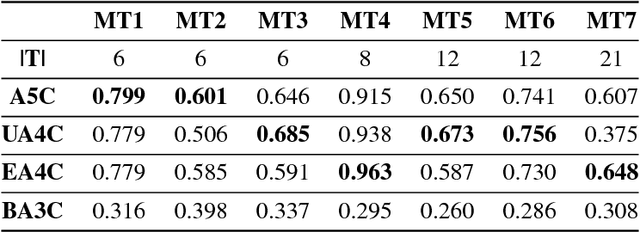
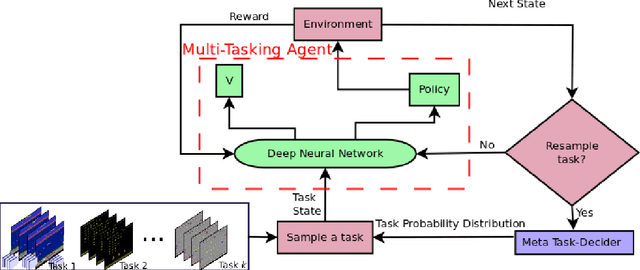
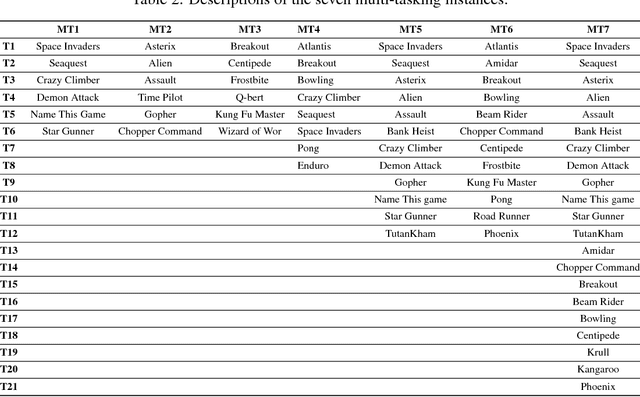
One of the long-standing challenges in Artificial Intelligence for learning goal-directed behavior is to build a single agent which can solve multiple tasks. Recent progress in multi-task learning for goal-directed sequential problems has been in the form of distillation based learning wherein a student network learns from multiple task-specific expert networks by mimicking the task-specific policies of the expert networks. While such approaches offer a promising solution to the multi-task learning problem, they require supervision from large expert networks which require extensive data and computation time for training. In this work, we propose an efficient multi-task learning framework which solves multiple goal-directed tasks in an on-line setup without the need for expert supervision. Our work uses active learning principles to achieve multi-task learning by sampling the harder tasks more than the easier ones. We propose three distinct models under our active sampling framework. An adaptive method with extremely competitive multi-tasking performance. A UCB-based meta-learner which casts the problem of picking the next task to train on as a multi-armed bandit problem. A meta-learning method that casts the next-task picking problem as a full Reinforcement Learning problem and uses actor critic methods for optimizing the multi-tasking performance directly. We demonstrate results in the Atari 2600 domain on seven multi-tasking instances: three 6-task instances, one 8-task instance, two 12-task instances and one 21-task instance.