 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRxRx3-core: Benchmarking drug-target interactions in High-Content Microscopy
Mar 26, 2025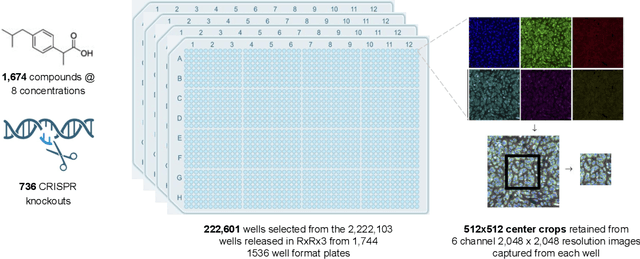


High Content Screening (HCS) microscopy datasets have transformed the ability to profile cellular responses to genetic and chemical perturbations, enabling cell-based inference of drug-target interactions (DTI). However, the adoption of representation learning methods for HCS data has been hindered by the lack of accessible datasets and robust benchmarks. To address this gap, we present RxRx3-core, a curated and compressed subset of the RxRx3 dataset, and an associated DTI benchmarking task. At just 18GB, RxRx3-core significantly reduces the size barrier associated with large-scale HCS datasets while preserving critical data necessary for benchmarking representation learning models against a zero-shot DTI prediction task. RxRx3-core includes 222,601 microscopy images spanning 736 CRISPR knockouts and 1,674 compounds at 8 concentrations. RxRx3-core is available on HuggingFace and Polaris, along with pre-trained embeddings and benchmarking code, ensuring accessibility for the research community. By providing a compact dataset and robust benchmarks, we aim to accelerate innovation in representation learning methods for HCS data and support the discovery of novel biological insights.
ViTally Consistent: Scaling Biological Representation Learning for Cell Microscopy
Nov 04, 2024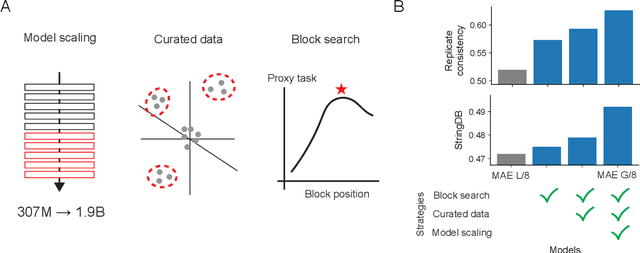
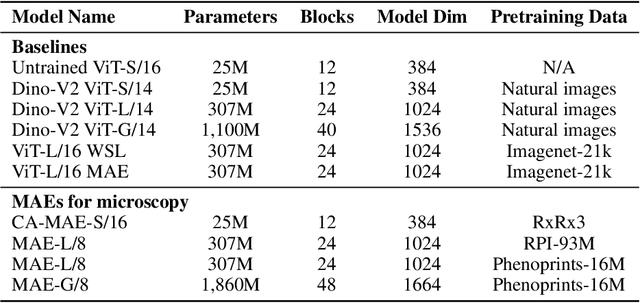
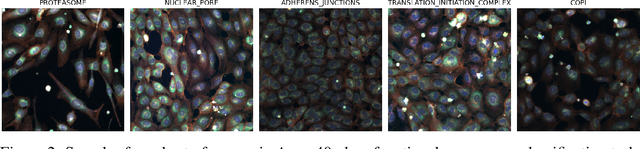
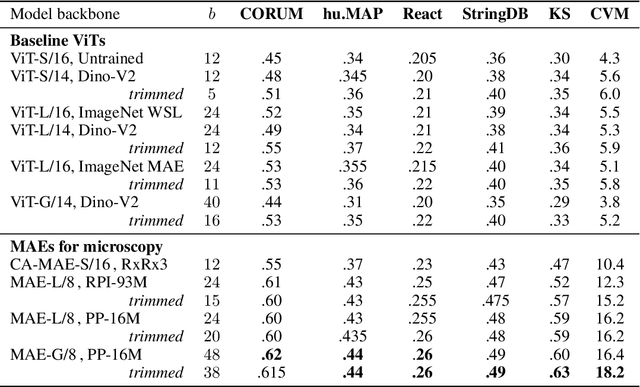
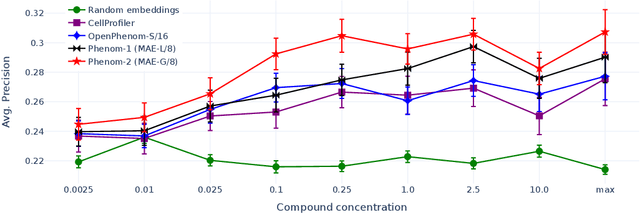
Large-scale cell microscopy screens are used in drug discovery and molecular biology research to study the effects of millions of chemical and genetic perturbations on cells. To use these images in downstream analysis, we need models that can map each image into a feature space that represents diverse biological phenotypes consistently, in the sense that perturbations with similar biological effects have similar representations. In this work, we present the largest foundation model for cell microscopy data to date, a new 1.9 billion-parameter ViT-G/8 MAE trained on over 8 billion microscopy image crops. Compared to a previous published ViT-L/8 MAE, our new model achieves a 60% improvement in linear separability of genetic perturbations and obtains the best overall performance on whole-genome biological relationship recall and replicate consistency benchmarks. Beyond scaling, we developed two key methods that improve performance: (1) training on a curated and diverse dataset; and, (2) using biologically motivated linear probing tasks to search across each transformer block for the best candidate representation of whole-genome screens. We find that many self-supervised vision transformers, pretrained on either natural or microscopy images, yield significantly more biologically meaningful representations of microscopy images in their intermediate blocks than in their typically used final blocks. More broadly, our approach and results provide insights toward a general strategy for successfully building foundation models for large-scale biological data.
Masked Autoencoders for Microscopy are Scalable Learners of Cellular Biology
Apr 16, 2024



Featurizing microscopy images for use in biological research remains a significant challenge, especially for large-scale experiments spanning millions of images. This work explores the scaling properties of weakly supervised classifiers and self-supervised masked autoencoders (MAEs) when training with increasingly larger model backbones and microscopy datasets. Our results show that ViT-based MAEs outperform weakly supervised classifiers on a variety of tasks, achieving as much as a 11.5% relative improvement when recalling known biological relationships curated from public databases. Additionally, we develop a new channel-agnostic MAE architecture (CA-MAE) that allows for inputting images of different numbers and orders of channels at inference time. We demonstrate that CA-MAEs effectively generalize by inferring and evaluating on a microscopy image dataset (JUMP-CP) generated under different experimental conditions with a different channel structure than our pretraining data (RPI-93M). Our findings motivate continued research into scaling self-supervised learning on microscopy data in order to create powerful foundation models of cellular biology that have the potential to catalyze advancements in drug discovery and beyond.
Masked autoencoders are scalable learners of cellular morphology
Sep 27, 2023
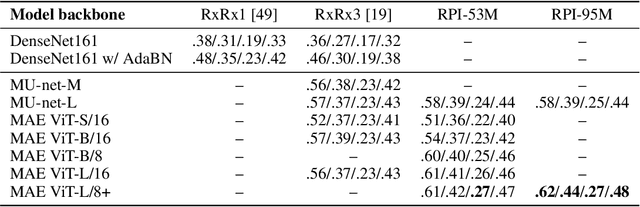

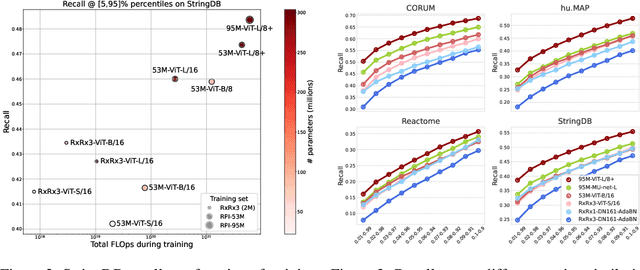
Inferring biological relationships from cellular phenotypes in high-content microscopy screens provides significant opportunity and challenge in biological research. Prior results have shown that deep vision models can capture biological signal better than hand-crafted features. This work explores how weakly supervised and self-supervised deep learning approaches scale when training larger models on larger datasets. Our results show that both CNN- and ViT-based masked autoencoders significantly outperform weakly supervised models. At the high-end of our scale, a ViT-L/8 trained on over 3.5-billion unique crops sampled from 95-million microscopy images achieves relative improvements as high as 28% over our best weakly supervised models at inferring known biological relationships curated from public databases.