 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Shape Features with Multiple Color Spaces in Open-Ended 3D Object Recognition
Sep 19, 2020



As a consequence of an ever-increasing number of camera-based service robots, there is a growing demand for highly accurate real-time 3D object recognition. Considering the expansion of robot applications in more complex and dynamic environments, it is evident that it is impossible to pre-program all possible object categories. Robots will have to be able to learn new object categories in the field. The network architecture proposed in this work expands from the OrthographicNet, an approach recently proposed by Kasaei et al., using a deep transfer learning strategy which not only meets the aforementioned requirements but additionally generates a scale and rotation-invariant reference frame for the classification of objects. In its current iteration, the OrthographicNet only uses shape-information. With the addition of multiple color spaces, the upgraded network architecture proposed here, can achieve an even higher descriptiveness while simultaneously increasing the robustness of predictions for similarly shaped objects. Multiple color space combinations and network architectures are evaluated to find the most descriptive system. However, this performance increase is not achieved at the cost of longer processing times, because any system deployed in robotic applications will need the ability to provide real-time information about its environment. Experimental results show that the proposed network architecture ranks competitively among other state-of-the-art algorithms.
The State of Service Robots: Current Bottlenecks in Object Perception and Manipulation
Mar 18, 2020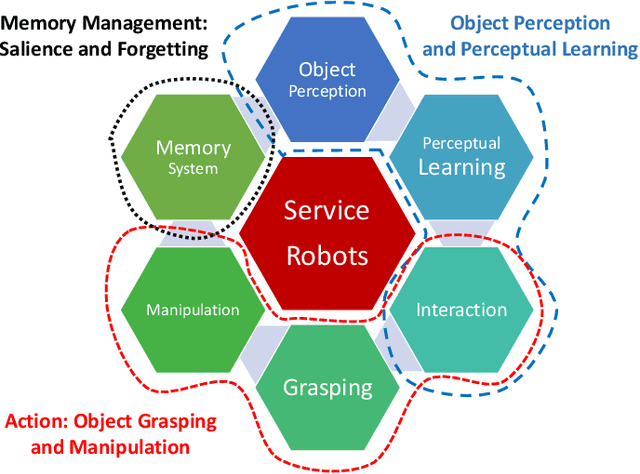
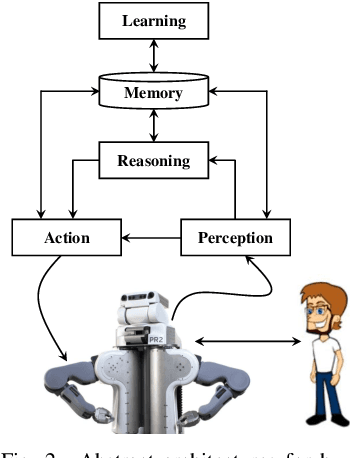


Service robots are appearing more and more in our daily life. The development of service robots combines multiple fields of research, from object perception to object manipulation. The state-of-the-art continues to improve to make a proper coupling between object perception and manipulation. This coupling is necessary for service robots not only to perform various tasks in a reasonable amount of time but also to adapt to new environments through time and interact with non-expert human users safely. Nowadays, robots are able to recognize various objects, and quickly plan a collision-free trajectory to grasp a target object. While there are many successes, the robot should be painstakingly coded in advance to perform a set of predefined tasks. Besides, in most of the cases, there is a reliance on large amounts of training data. Therefore, the knowledge of such robots is fixed after the training phase, and any changes in the environment require complicated, time-consuming, and expensive robot re-programming by human experts. Therefore, these approaches are still too rigid for real-life applications in unstructured environments, where a significant portion of the environment is unknown and cannot be directly sensed or controlled. In this paper, we review advances in service robots from object perception to complex object manipulation and shed a light on the current challenges and bottlenecks.
Learning to Grasp 3D Objects using Deep Residual U-Nets
Feb 10, 2020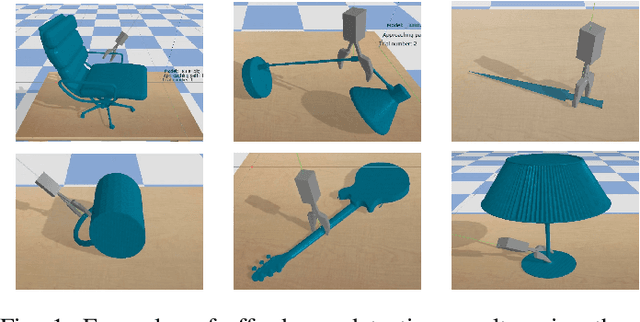
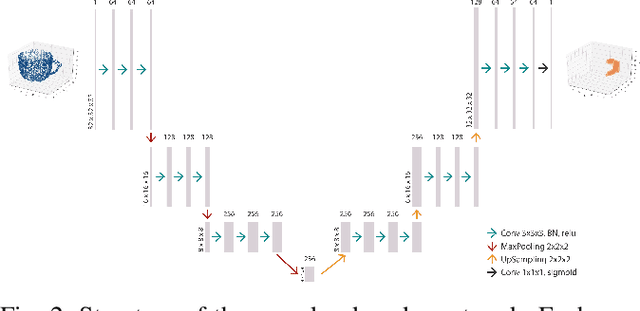
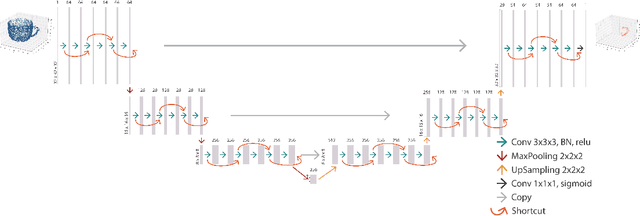
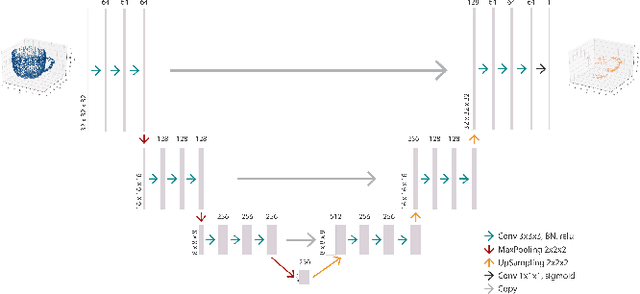
Affordance detection is one of the challenging tasks in robotics because it must predict the grasp configuration for the object of interest in real-time to enable the robot to interact with the environment. In this paper, we present a new deep learning approach to detect object affordances for a given 3D object. The method trains a Convolutional Neural Network (CNN) to learn a set of grasping features from RGB-D images. We named our approach \emph{Res-U-Net} since the architecture of the network is designed based on U-Net structure and residual network-styled blocks. It devised to be robust and efficient to compute and use. A set of experiments has been performed to assess the performance of the proposed approach regarding grasp success rate on simulated robotic scenarios. Experiments validate the promising performance of the proposed architecture on a subset of ShapeNetCore dataset and simulated robot scenarios.
Investigating the Importance of Shape Features, Color Constancy, Color Spaces and Similarity Measures in Open-Ended 3D Object Recognition
Feb 10, 2020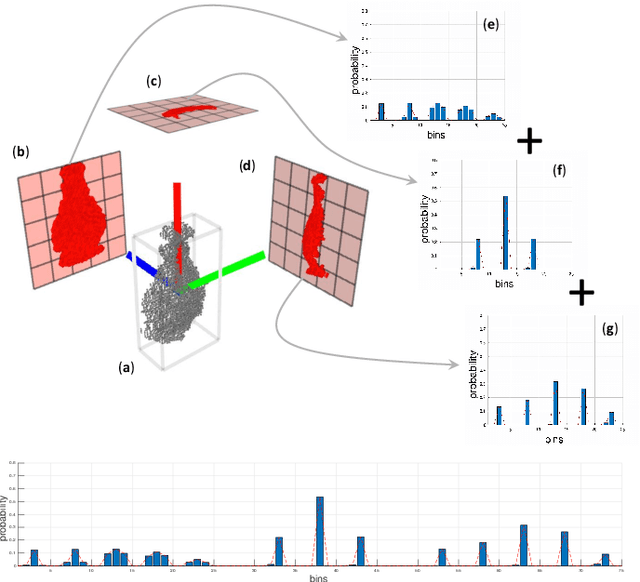
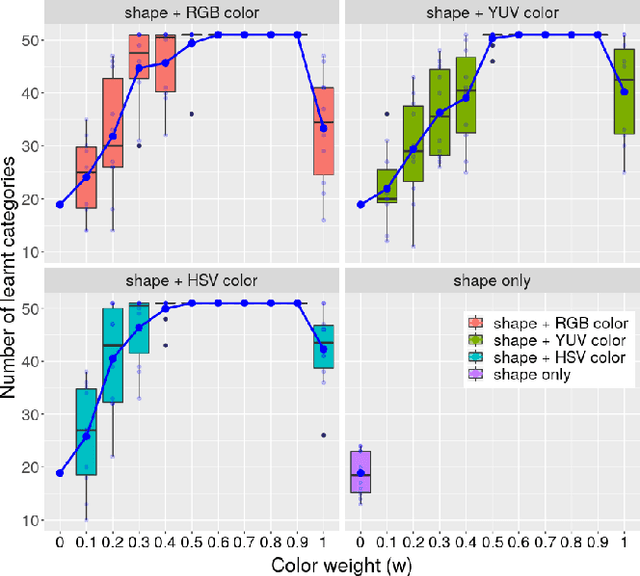
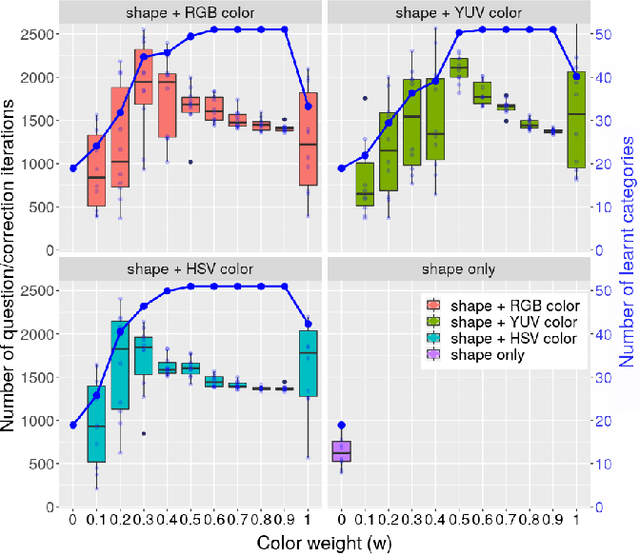

Despite the recent success of state-of-the-art 3D object recognition approaches, service robots are frequently failed to recognize many objects in real human-centric environments. For these robots, object recognition is a challenging task due to the high demand for accurate and real-time response under changing and unpredictable environmental conditions. Most of the recent approaches use either the shape information only and ignore the role of color information or vice versa. Furthermore, they mainly utilize the $L_n$ Minkowski family functions to measure the similarity of two object views, while there are various distance measures that are applicable to compare two object views. In this paper, we explore the importance of shape information, color constancy, color spaces, and various similarity measures in open-ended 3D object recognition. Towards this goal, we extensively evaluate the performance of object recognition approaches in three different configurations, including \textit{color-only}, \textit{shape-only}, and \textit{ combinations of color and shape}, in both offline and online settings. Experimental results concerning scalability, memory usage, and object recognition performance show that all of the \textit{combinations of color and shape} yields significant improvements over the \textit{shape-only} and \textit{color-only} approaches. The underlying reason is that color information is an important feature to distinguish objects that have very similar geometric properties with different colors and vice versa. Moreover, by combining color and shape information, we demonstrate that the robot can learn new object categories from very few training examples in a real-world setting.
Interactive Open-Ended Learning for 3D Object Recognition
Dec 19, 2019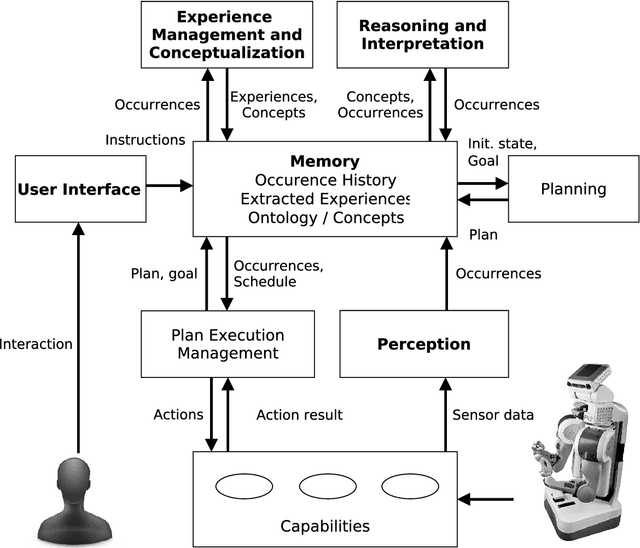

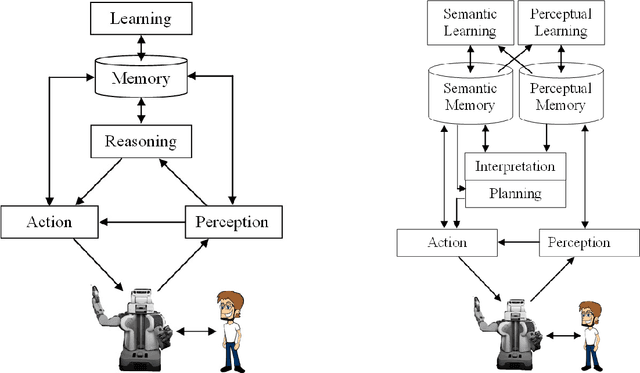
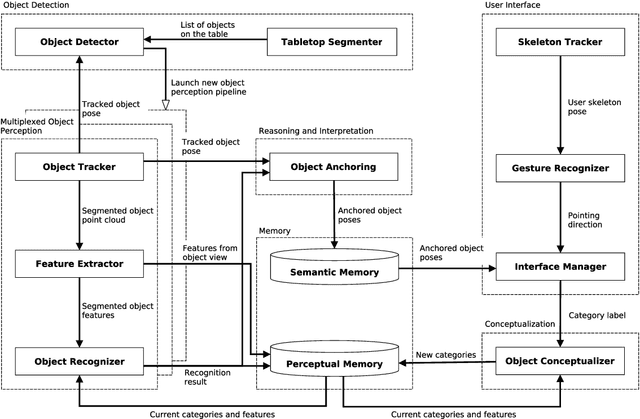
The thesis contributes in several important ways to the research area of 3D object category learning and recognition. To cope with the mentioned limitations, we look at human cognition, in particular at the fact that human beings learn to recognize object categories ceaselessly over time. This ability to refine knowledge from the set of accumulated experiences facilitates the adaptation to new environments. Inspired by this capability, we seek to create a cognitive object perception and perceptual learning architecture that can learn 3D object categories in an open-ended fashion. In this context, ``open-ended'' implies that the set of categories to be learned is not known in advance, and the training instances are extracted from actual experiences of a robot, and thus become gradually available, rather than being available since the beginning of the learning process. In particular, this architecture provides perception capabilities that will allow robots to incrementally learn object categories from the set of accumulated experiences and reason about how to perform complex tasks. This framework integrates detection, tracking, teaching, learning, and recognition of objects. An extensive set of systematic experiments, in multiple experimental settings, was carried out to thoroughly evaluate the described learning approaches. Experimental results show that the proposed system is able to interact with human users, learn new object categories over time, as well as perform complex tasks. The contributions presented in this thesis have been fully implemented and evaluated on different standard object and scene datasets and empirically evaluated on different robotic platforms.
Look Further to Recognize Better: Learning Shared Topics and Category-Specific Dictionaries for Open-Ended 3D Object Recognition
Jul 26, 2019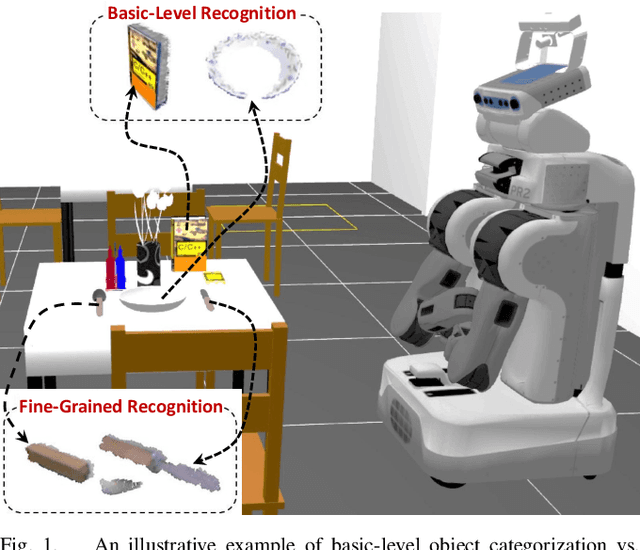
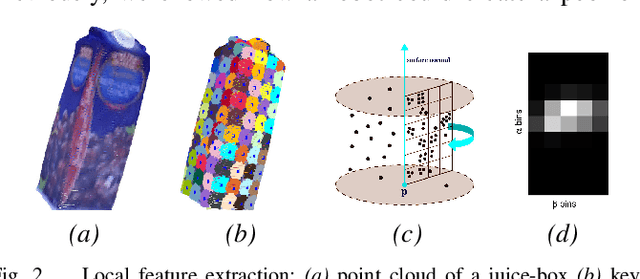


Service robots are expected to operate effectively in human-centric environments for long periods of time. In such realistic scenarios, fine-grained object categorization is as important as basic-level object categorization. We tackle this problem by proposing an open-ended object recognition approach which concurrently learns both the object categories and the local features for encoding objects. In this work, each object is represented using a set of general latent visual topics and category-specific dictionaries. The general topics encode the common patterns of all categories, while the category-specific dictionary describes the content of each category in details. The proposed approach discovers both sets of general and specific representations in an unsupervised fashion and updates them incrementally using new object views. Experimental results show that our approach yields significant improvements over the previous state-of-the-art approaches concerning scalability and object classification performance. Moreover, our approach demonstrates the capability of learning from very few training examples in a real-world setting. Regarding computation time, the best result was obtained with a Bag-of-Words method followed by a variant of the Latent Dirichlet Allocation approach.
Object Perception and Grasping in Open-Ended Domains
Jul 25, 2019

Nowadays service robots are leaving the structured and completely known environments and entering human-centric settings. For these robots, object perception and grasping are two challenging tasks due to the high demand for accurate and real-time responses. Although many problems have already been understood and solved successfully, many challenges still remain. Open-ended learning is one of these challenges waiting for many improvements. Cognitive science revealed that humans learn to recognize object categories and grasp affordances ceaselessly over time. This ability allows adapting to new environments by enhancing their knowledge from the accumulation of experiences and the conceptualization of new object categories. Inspired by this, an autonomous robot must have the ability to process visual information and conduct learning and recognition tasks in an open-ended fashion. In this context, "open-ended" implies that the set of object categories to be learned is not known in advance, and the training instances are extracted from online experiences of a robot, and become gradually available over time, rather than being completely available at the beginning of the learning process. In my research, I mainly focus on interactive open-ended learning approaches to recognize multiple objects and their grasp affordances concurrently. In particular, I try to address the following research questions: (i) What is the importance of open-ended learning for autonomous robots? (ii) How robots could learn incrementally from their own experiences as well as from interaction with humans? (iii) What are the limitations of Deep Learning approaches to be used in an open-ended manner? (iv) How to evaluate open-ended learning approaches and what are the right metrics to do so?
Interactive Open-Ended Object, Affordance and Grasp Learning for Robotic Manipulation
Apr 04, 2019
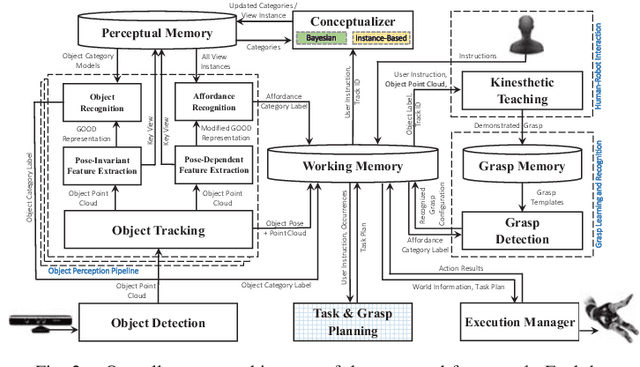

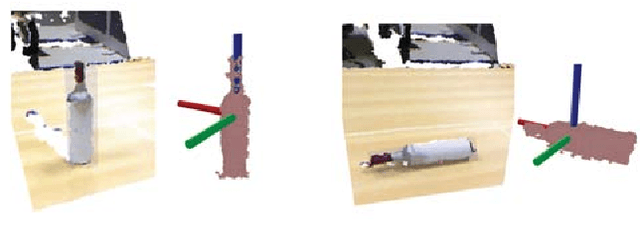
Service robots are expected to autonomously and efficiently work in human-centric environments. For this type of robots, object perception and manipulation are challenging tasks due to need for accurate and real-time response. This paper presents an interactive open-ended learning approach to recognize multiple objects and their grasp affordances concurrently. This is an important contribution in the field of service robots since no matter how extensive the training data used for batch learning, a robot might always be confronted with an unknown object when operating in human-centric environments. The paper describes the system architecture and the learning and recognition capabilities. Grasp learning associates grasp configurations (i.e., end-effector positions and orientations) to grasp affordance categories. The grasp affordance category and the grasp configuration are taught through verbal and kinesthetic teaching, respectively. A Bayesian approach is adopted for learning and recognition of object categories and an instance-based approach is used for learning and recognition of affordance categories. An extensive set of experiments has been performed to assess the performance of the proposed approach regarding recognition accuracy, scalability and grasp success rate on challenging datasets and real-world scenarios.