 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning Out-of-Distribution (OOD) Detectors Without Given OOD Data
Feb 05, 2026Existing out-of-distribution (OOD) detectors are often tuned by a separate dataset deemed OOD with respect to the training distribution of a neural network (NN). OOD detectors process the activations of NN layers and score the output, where parameters of the detectors are determined by fitting to an in-distribution (training) set and the aforementioned dataset chosen adhocly. At detector training time, this adhoc dataset may not be available or difficult to obtain, and even when it's available, it may not be representative of actual OOD data, which is often ''unknown unknowns." Current benchmarks may specify some left-out set from test OOD sets. We show that there can be significant variance in performance of detectors based on the adhoc dataset chosen in current literature, and thus even if such a dataset can be collected, the performance of the detector may be highly dependent on the choice. In this paper, we introduce and formalize the often neglected problem of tuning OOD detectors without a given ``OOD'' dataset. To this end, we present strong baselines as an attempt to approach this problem. Furthermore, we propose a new generic approach to OOD detector tuning that does not require any extra data other than those used to train the NN. We show that our approach improves over baseline methods consistently across higher-parameter OOD detector families, while being comparable across lower-parameter families.
Prompt-Based Exemplar Super-Compression and Regeneration for Class-Incremental Learning
Nov 30, 2023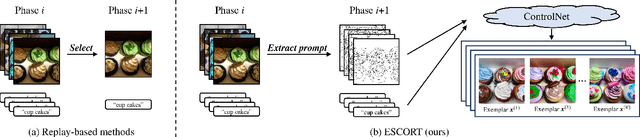
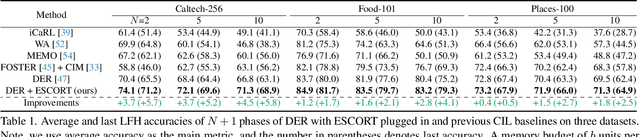
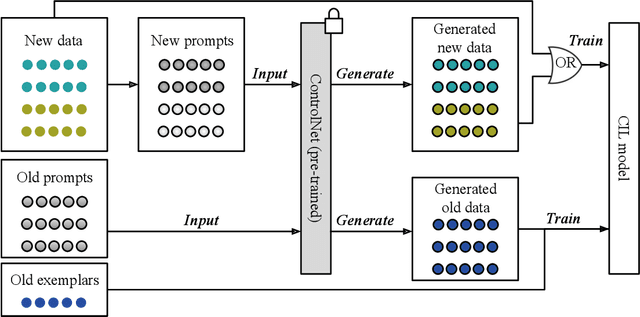
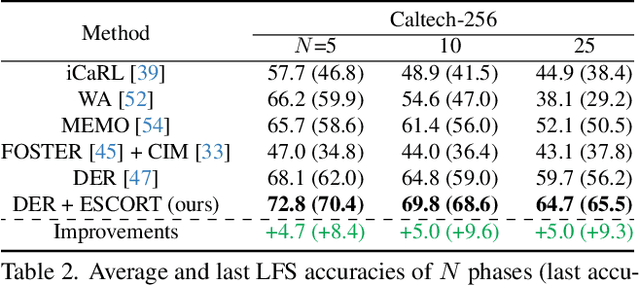
Replay-based methods in class-incremental learning (CIL) have attained remarkable success, as replaying the exemplars of old classes can significantly mitigate catastrophic forgetting. Despite their effectiveness, the inherent memory restrictions of CIL result in saving a limited number of exemplars with poor diversity, leading to data imbalance and overfitting issues. In this paper, we introduce a novel exemplar super-compression and regeneration method, ESCORT, which substantially increases the quantity and enhances the diversity of exemplars. Rather than storing past images, we compress images into visual and textual prompts, e.g., edge maps and class tags, and save the prompts instead, reducing the memory usage of each exemplar to 1/24 of the original size. In subsequent learning phases, diverse high-resolution exemplars are generated from the prompts by a pre-trained diffusion model, e.g., ControlNet. To minimize the domain gap between generated exemplars and real images, we propose partial compression and diffusion-based data augmentation, allowing us to utilize an off-the-shelf diffusion model without fine-tuning it on the target dataset. Therefore, the same diffusion model can be downloaded whenever it is needed, incurring no memory consumption. Comprehensive experiments demonstrate that our method significantly improves model performance across multiple CIL benchmarks, e.g., 5.0 percentage points higher than the previous state-of-the-art on 10-phase Caltech-256 dataset.
Evidential Uncertainty Quantification: A Variance-Based Perspective
Nov 19, 2023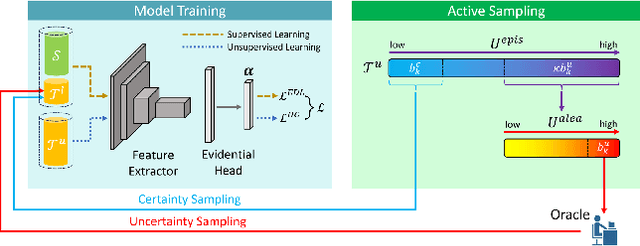
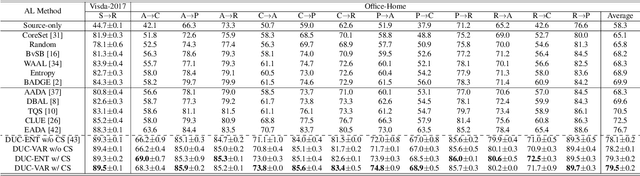
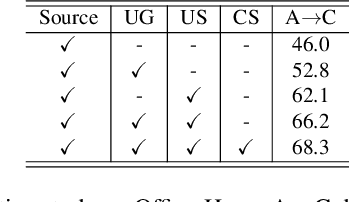
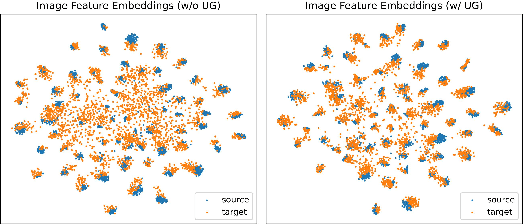
Uncertainty quantification of deep neural networks has become an active field of research and plays a crucial role in various downstream tasks such as active learning. Recent advances in evidential deep learning shed light on the direct quantification of aleatoric and epistemic uncertainties with a single forward pass of the model. Most traditional approaches adopt an entropy-based method to derive evidential uncertainty in classification, quantifying uncertainty at the sample level. However, the variance-based method that has been widely applied in regression problems is seldom used in the classification setting. In this work, we adapt the variance-based approach from regression to classification, quantifying classification uncertainty at the class level. The variance decomposition technique in regression is extended to class covariance decomposition in classification based on the law of total covariance, and the class correlation is also derived from the covariance. Experiments on cross-domain datasets are conducted to illustrate that the variance-based approach not only results in similar accuracy as the entropy-based one in active domain adaptation but also brings information about class-wise uncertainties as well as between-class correlations. The code is available at https://github.com/KerryDRX/EvidentialADA. This alternative means of evidential uncertainty quantification will give researchers more options when class uncertainties and correlations are important in their applications.