 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Based Exemplar Super-Compression and Regeneration for Class-Incremental Learning
Paper and Code
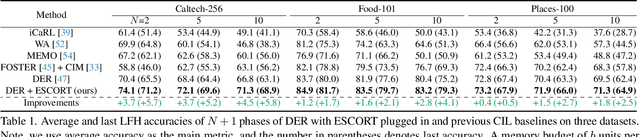
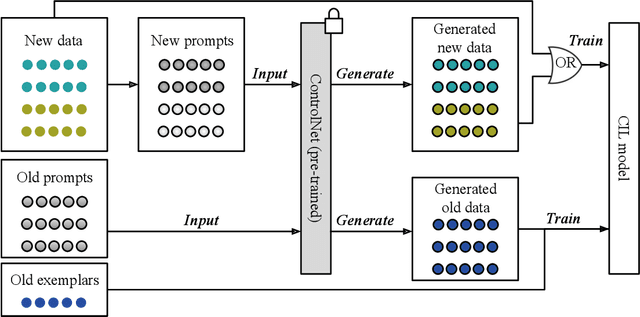
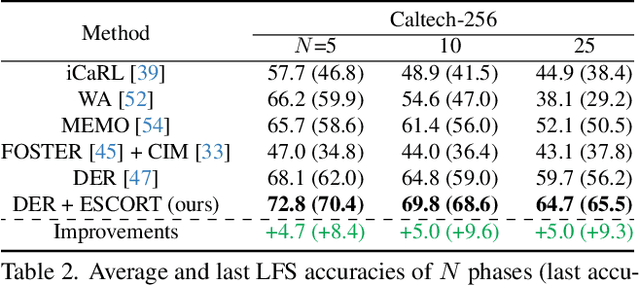
Replay-based methods in class-incremental learning (CIL) have attained remarkable success, as replaying the exemplars of old classes can significantly mitigate catastrophic forgetting. Despite their effectiveness, the inherent memory restrictions of CIL result in saving a limited number of exemplars with poor diversity, leading to data imbalance and overfitting issues. In this paper, we introduce a novel exemplar super-compression and regeneration method, ESCORT, which substantially increases the quantity and enhances the diversity of exemplars. Rather than storing past images, we compress images into visual and textual prompts, e.g., edge maps and class tags, and save the prompts instead, reducing the memory usage of each exemplar to 1/24 of the original size. In subsequent learning phases, diverse high-resolution exemplars are generated from the prompts by a pre-trained diffusion model, e.g., ControlNet. To minimize the domain gap between generated exemplars and real images, we propose partial compression and diffusion-based data augmentation, allowing us to utilize an off-the-shelf diffusion model without fine-tuning it on the target dataset. Therefore, the same diffusion model can be downloaded whenever it is needed, incurring no memory consumption. Comprehensive experiments demonstrate that our method significantly improves model performance across multiple CIL benchmarks, e.g., 5.0 percentage points higher than the previous state-of-the-art on 10-phase Caltech-256 dataset.