 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection in Aerial Imagery
Nov 15, 2022



Object detection in natural images has achieved remarkable results over the years. However, a similar progress has not yet been observed in aerial object detection due to several challenges, such as high resolution images, instances scale variation, class imbalance etc. We show the performance of two-stage, one-stage and attention based object detectors on the iSAID dataset. Furthermore, we describe some modifications and analysis performed for different models - a) In two stage detector: introduced weighted attention based FPN, class balanced sampler and density prediction head. b) In one stage detector: used weighted focal loss and introduced FPN. c) In attention based detector: compare single,multi-scale attention and demonstrate effect of different backbones. Finally, we show a comparative study highlighting the pros and cons of different models in aerial imagery setting.
$\textrm{D}^3\textrm{Former}$: Debiased Dual Distilled Transformer for Incremental Learning
Jul 25, 2022
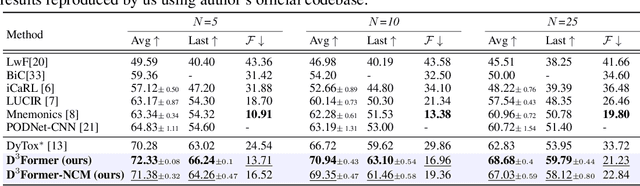


Class incremental learning (CIL) involves learning a classification model where groups of new classes are encountered in every learning phase. The goal is to learn a unified model performant on all the classes observed so far. Given the recent popularity of Vision Transformers (ViTs) in conventional classification settings, an interesting question is to study their continual learning behaviour. In this work, we develop a Debiased Dual Distilled Transformer for CIL dubbed $\textrm{D}^3\textrm{Former}$. The proposed model leverages a hybrid nested ViT design to ensure data efficiency and scalability to small as well as large datasets. In contrast to a recent ViT based CIL approach, our $\textrm{D}^3\textrm{Former}$ does not dynamically expand its architecture when new tasks are learned and remains suitable for a large number of incremental tasks. The improved CIL behaviour of $\textrm{D}^3\textrm{Former}$ owes to two fundamental changes to the ViT design. First, we treat the incremental learning as a long-tail classification problem where the majority samples from new classes vastly outnumber the limited exemplars available for old classes. To avoid biasness against the minority old classes, we propose to dynamically adjust logits to emphasize on retaining the representations relevant to old tasks. Second, we propose to preserve the configuration of spatial attention maps as the learning progresses across tasks. This helps in reducing catastrophic forgetting via constraining the model to retain the attention on the most discriminative regions. $\textrm{D}^3\textrm{Former}$ obtains favorable results on incremental versions of CIFAR-100, MNIST, SVHN, and ImageNet datasets.
Self-Supervised Learning for Fine-Grained Image Classification
Jul 29, 2021


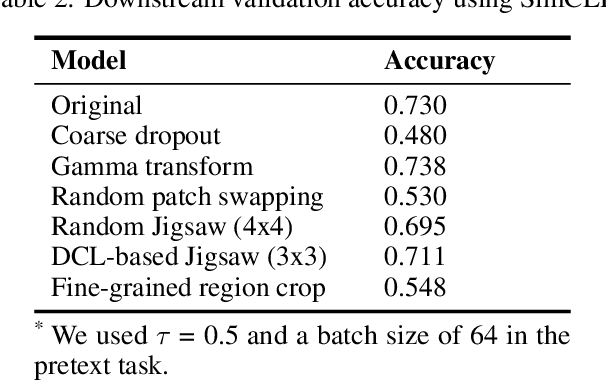
Fine-grained image classification involves identifying different subcategories of a class which possess very subtle discriminatory features. Fine-grained datasets usually provide bounding box annotations along with class labels to aid the process of classification. However, building large scale datasets with such annotations is a mammoth task. Moreover, this extensive annotation is time-consuming and often requires expertise, which is a huge bottleneck in building large datasets. On the other hand, self-supervised learning (SSL) exploits the freely available data to generate supervisory signals which act as labels. The features learnt by performing some pretext tasks on huge unlabelled data proves to be very helpful for multiple downstream tasks. Our idea is to leverage self-supervision such that the model learns useful representations of fine-grained image classes. We experimented with 3 kinds of models: Jigsaw solving as pretext task, adversarial learning (SRGAN) and contrastive learning based (SimCLR) model. The learned features are used for downstream tasks such as fine-grained image classification. Our code is available at http://github.com/rush2406/Self-Supervised-Learning-for-Fine-grained-Image-Classification