 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textrm{D}^3\textrm{Former}$: Debiased Dual Distilled Transformer for Incremental Learning
Paper and Code
Jul 25, 2022
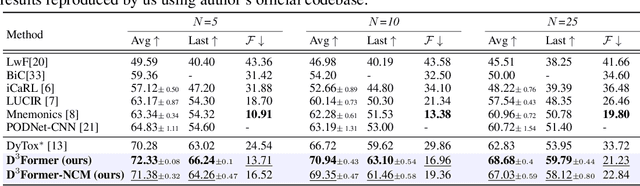


Class incremental learning (CIL) involves learning a classification model where groups of new classes are encountered in every learning phase. The goal is to learn a unified model performant on all the classes observed so far. Given the recent popularity of Vision Transformers (ViTs) in conventional classification settings, an interesting question is to study their continual learning behaviour. In this work, we develop a Debiased Dual Distilled Transformer for CIL dubbed $\textrm{D}^3\textrm{Former}$. The proposed model leverages a hybrid nested ViT design to ensure data efficiency and scalability to small as well as large datasets. In contrast to a recent ViT based CIL approach, our $\textrm{D}^3\textrm{Former}$ does not dynamically expand its architecture when new tasks are learned and remains suitable for a large number of incremental tasks. The improved CIL behaviour of $\textrm{D}^3\textrm{Former}$ owes to two fundamental changes to the ViT design. First, we treat the incremental learning as a long-tail classification problem where the majority samples from new classes vastly outnumber the limited exemplars available for old classes. To avoid biasness against the minority old classes, we propose to dynamically adjust logits to emphasize on retaining the representations relevant to old tasks. Second, we propose to preserve the configuration of spatial attention maps as the learning progresses across tasks. This helps in reducing catastrophic forgetting via constraining the model to retain the attention on the most discriminative regions. $\textrm{D}^3\textrm{Former}$ obtains favorable results on incremental versions of CIFAR-100, MNIST, SVHN, and ImageNet datasets.