 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
May 04, 2026This report describes ARIS (Auto-Research-in-sleep), an open-source research harness for autonomous research, including its architecture, assurance mechanisms, and early deployment experience. The performance of agent systems built on LLMs depends on both the model weights and the harness around them, which governs what information to store, retrieve, and present to the model. For long-horizon research workflows, the central failure mode is not a visible breakdown but a plausible unsupported success: a long-running agent can produce claims whose evidential support is incomplete, misreported, or silently inherited from the executor's framing. Therefore, we present ARIS as a research harness that coordinates machine-learning research workflows through cross-model adversarial collaboration as a default configuration: an executor model drives forward progress while a reviewer from a different model family is recommended to critique intermediate artifacts and request revisions. ARIS has three architectural layers. The execution layer provides more than 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki for iterative reuse of prior findings, and deterministic figure generation. The orchestration layer coordinates five end-to-end workflows with adjustable effort settings and configurable routing to reviewer models. The assurance layer includes a three-stage process for checking whether experimental claims are supported by evidence: integrity verification, result-to-claim mapping, and claim auditing that cross-checks manuscript statements against the claim ledger and raw evidence, as well as a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of the rendered PDF. A prototype self-improvement loop records research traces and proposes harness improvements that are adopted only after reviewer approval.
Multi-Subspace Multi-Modal Modeling for Diffusion Models: Estimation, Convergence and Mixture of Experts
Jan 04, 2026Recently, diffusion models have achieved a great performance with a small dataset of size $n$ and a fast optimization process. However, the estimation error of diffusion models suffers from the curse of dimensionality $n^{-1/D}$ with the data dimension $D$. Since images are usually a union of low-dimensional manifolds, current works model the data as a union of linear subspaces with Gaussian latent and achieve a $1/\sqrt{n}$ bound. Though this modeling reflects the multi-manifold property, the Gaussian latent can not capture the multi-modal property of the latent manifold. To bridge this gap, we propose the mixture subspace of low-rank mixture of Gaussian (MoLR-MoG) modeling, which models the target data as a union of $K$ linear subspaces, and each subspace admits a mixture of Gaussian latent ($n_k$ modals with dimension $d_k$). With this modeling, the corresponding score function naturally has a mixture of expert (MoE) structure, captures the multi-modal information, and contains nonlinear property. We first conduct real-world experiments to show that the generation results of MoE-latent MoG NN are much better than MoE-latent Gaussian score. Furthermore, MoE-latent MoG NN achieves a comparable performance with MoE-latent Unet with $10 \times$ parameters. These results indicate that the MoLR-MoG modeling is reasonable and suitable for real-world data. After that, based on such MoE-latent MoG score, we provide a $R^4\sqrt{Σ_{k=1}^Kn_k}\sqrt{Σ_{k=1}^Kn_kd_k}/\sqrt{n}$ estimation error, which escapes the curse of dimensionality by using data structure. Finally, we study the optimization process and prove the convergence guarantee under the MoLR-MoG modeling. Combined with these results, under a setting close to real-world data, this work explains why diffusion models only require a small training sample and enjoy a fast optimization process to achieve a great performance.
Elucidating Rectified Flow with Deterministic Sampler: Polynomial Discretization Complexity for Multi and One-step Models
Aug 12, 2025Recently, rectified flow (RF)-based models have achieved state-of-the-art performance in many areas for both the multi-step and one-step generation. However, only a few theoretical works analyze the discretization complexity of RF-based models. Existing works either focus on flow-based models with stochastic samplers or establish complexity results that exhibit exponential dependence on problem parameters. In this work, under the realistic bounded support assumption, we prove the first polynomial discretization complexity for multi-step and one-step RF-based models with a deterministic sampler simultaneously. For the multi-step setting, inspired by the predictor-corrector framework of diffusion models, we introduce a Langevin process as a corrector and show that RF-based models can achieve better polynomial discretization complexity than diffusion models. To achieve this result, we conduct a detailed analysis of the RF-based model and explain why it is better than previous popular models, such as variance preserving (VP) and variance exploding (VE)-based models. Based on the observation of multi-step RF-based models, we further provide the first polynomial discretization complexity result for one-step RF-based models, improving upon prior results for one-step diffusion-based models. These findings mark the first step toward theoretically understanding the impressive empirical performance of RF-based models in both multi-step and one-step generation.
Understanding Representation Learnability of Nonlinear Self-Supervised Learning
Jan 06, 2024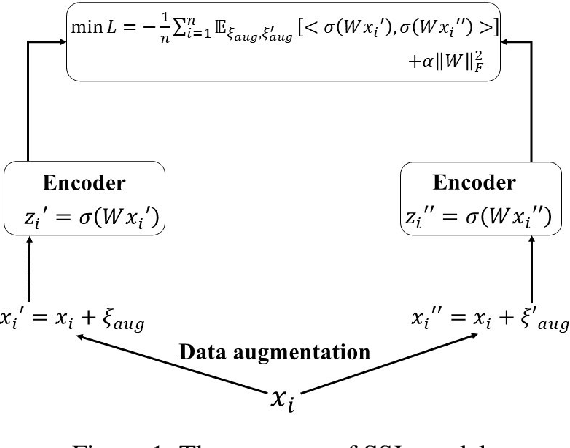
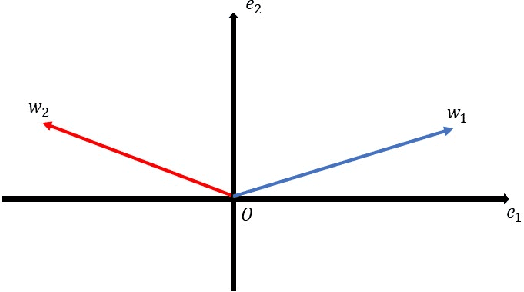
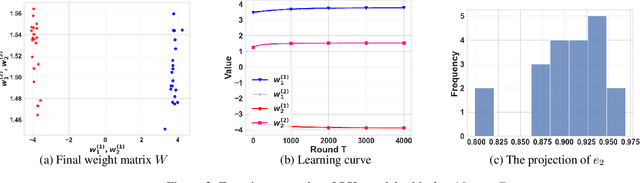
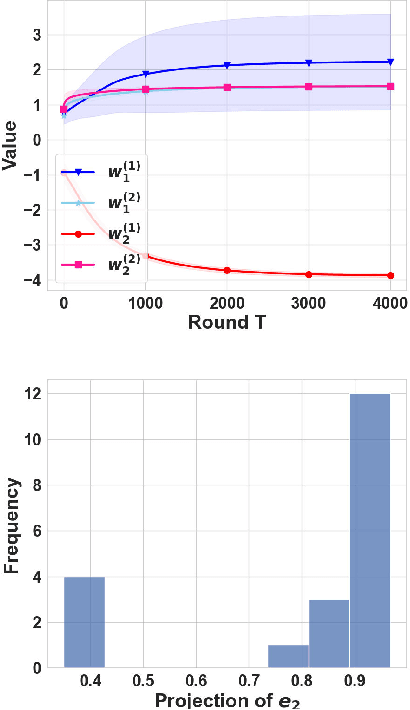
Self-supervised learning (SSL) has empirically shown its data representation learnability in many downstream tasks. There are only a few theoretical works on data representation learnability, and many of those focus on final data representation, treating the nonlinear neural network as a ``black box". However, the accurate learning results of neural networks are crucial for describing the data distribution features learned by SSL models. Our paper is the first to analyze the learning results of the nonlinear SSL model accurately. We consider a toy data distribution that contains two features: the label-related feature and the hidden feature. Unlike previous linear setting work that depends on closed-form solutions, we use the gradient descent algorithm to train a 1-layer nonlinear SSL model with a certain initialization region and prove that the model converges to a local minimum. Furthermore, different from the complex iterative analysis, we propose a new analysis process which uses the exact version of Inverse Function Theorem to accurately describe the features learned by the local minimum. With this local minimum, we prove that the nonlinear SSL model can capture the label-related feature and hidden feature at the same time. In contrast, the nonlinear supervised learning (SL) model can only learn the label-related feature. We also present the learning processes and results of the nonlinear SSL and SL model via simulation experiments.
Learning Adversarial Low-rank Markov Decision Processes with Unknown Transition and Full-information Feedback
Nov 14, 2023

In this work, we study the low-rank MDPs with adversarially changed losses in the full-information feedback setting. In particular, the unknown transition probability kernel admits a low-rank matrix decomposition \citep{REPUCB22}, and the loss functions may change adversarially but are revealed to the learner at the end of each episode. We propose a policy optimization-based algorithm POLO, and we prove that it attains the $\widetilde{O}(K^{\frac{5}{6}}A^{\frac{1}{2}}d\ln(1+M)/(1-\gamma)^2)$ regret guarantee, where $d$ is rank of the transition kernel (and hence the dimension of the unknown representations), $A$ is the cardinality of the action space, $M$ is the cardinality of the model class, and $\gamma$ is the discounted factor. Notably, our algorithm is oracle-efficient and has a regret guarantee with no dependence on the size of potentially arbitrarily large state space. Furthermore, we also prove an $\Omega(\frac{\gamma^2}{1-\gamma} \sqrt{d A K})$ regret lower bound for this problem, showing that low-rank MDPs are statistically more difficult to learn than linear MDPs in the regret minimization setting. To the best of our knowledge, we present the first algorithm that interleaves representation learning, exploration, and exploitation to achieve the sublinear regret guarantee for RL with nonlinear function approximation and adversarial losses.