 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-UIR: 3D Gaussian for Underwater 3D Scene Reconstruction via Physics Based Appearance-Medium Decoupling
May 29, 2025Novel view synthesis for underwater scene reconstruction presents unique challenges due to complex light-media interactions. Optical scattering and absorption in water body bring inhomogeneous medium attenuation interference that disrupts conventional volume rendering assumptions of uniform propagation medium. While 3D Gaussian Splatting (3DGS) offers real-time rendering capabilities, it struggles with underwater inhomogeneous environments where scattering media introduce artifacts and inconsistent appearance. In this study, we propose a physics-based framework that disentangles object appearance from water medium effects through tailored Gaussian modeling. Our approach introduces appearance embeddings, which are explicit medium representations for backscatter and attenuation, enhancing scene consistency. In addition, we propose a distance-guided optimization strategy that leverages pseudo-depth maps as supervision with depth regularization and scale penalty terms to improve geometric fidelity. By integrating the proposed appearance and medium modeling components via an underwater imaging model, our approach achieves both high-quality novel view synthesis and physically accurate scene restoration. Experiments demonstrate our significant improvements in rendering quality and restoration accuracy over existing methods. The project page is available at https://bilityniu.github.io/3D-UIR.
Low-Light Video Enhancement via Spatial-Temporal Consistent Illumination and Reflection Decomposition
May 24, 2024Low-Light Video Enhancement (LLVE) seeks to restore dynamic and static scenes plagued by severe invisibility and noise. One critical aspect is formulating a consistency constraint specifically for temporal-spatial illumination and appearance enhanced versions, a dimension overlooked in existing methods. In this paper, we present an innovative video Retinex-based decomposition strategy that operates without the need for explicit supervision to delineate illumination and reflectance components. We leverage dynamic cross-frame correspondences for intrinsic appearance and enforce a scene-level continuity constraint on the illumination field to yield satisfactory consistent decomposition results. To further ensure consistent decomposition, we introduce a dual-structure enhancement network featuring a novel cross-frame interaction mechanism. This mechanism can seamlessly integrate with encoder-decoder single-frame networks, incurring minimal additional parameter costs. By supervising different frames simultaneously, this network encourages them to exhibit matching decomposition features, thus achieving the desired temporal propagation. Extensive experiments are conducted on widely recognized LLVE benchmarks, covering diverse scenarios. Our framework consistently outperforms existing methods, establishing a new state-of-the-art (SOTA) performance.
Low-Light Image Enhancement via Structure Modeling and Guidance
May 10, 2023This paper proposes a new framework for low-light image enhancement by simultaneously conducting the appearance as well as structure modeling. It employs the structural feature to guide the appearance enhancement, leading to sharp and realistic results. The structure modeling in our framework is implemented as the edge detection in low-light images. It is achieved with a modified generative model via designing a structure-aware feature extractor and generator. The detected edge maps can accurately emphasize the essential structural information, and the edge prediction is robust towards the noises in dark areas. Moreover, to improve the appearance modeling, which is implemented with a simple U-Net, a novel structure-guided enhancement module is proposed with structure-guided feature synthesis layers. The appearance modeling, edge detector, and enhancement module can be trained end-to-end. The experiments are conducted on representative datasets (sRGB and RAW domains), showing that our model consistently achieves SOTA performance on all datasets with the same architecture.
Deep Parametric 3D Filters for Joint Video Denoising and Illumination Enhancement in Video Super Resolution
Jul 05, 2022


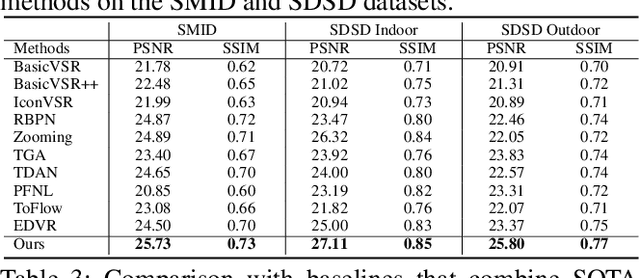
Despite the quality improvement brought by the recent methods, video super-resolution (SR) is still very challenging, especially for videos that are low-light and noisy. The current best solution is to subsequently employ best models of video SR, denoising, and illumination enhancement, but doing so often lowers the image quality, due to the inconsistency between the models. This paper presents a new parametric representation called the Deep Parametric 3D Filters (DP3DF), which incorporates local spatiotemporal information to enable simultaneous denoising, illumination enhancement, and SR efficiently in a single encoder-and-decoder network. Also, a dynamic residual frame is jointly learned with the DP3DF via a shared backbone to further boost the SR quality. We performed extensive experiments, including a large-scale user study, to show our method's effectiveness. Our method consistently surpasses the best state-of-the-art methods on all the challenging real datasets with top PSNR and user ratings, yet having a very fast run time.
Automatic Real-time Background Cut for Portrait Videos
Apr 28, 2017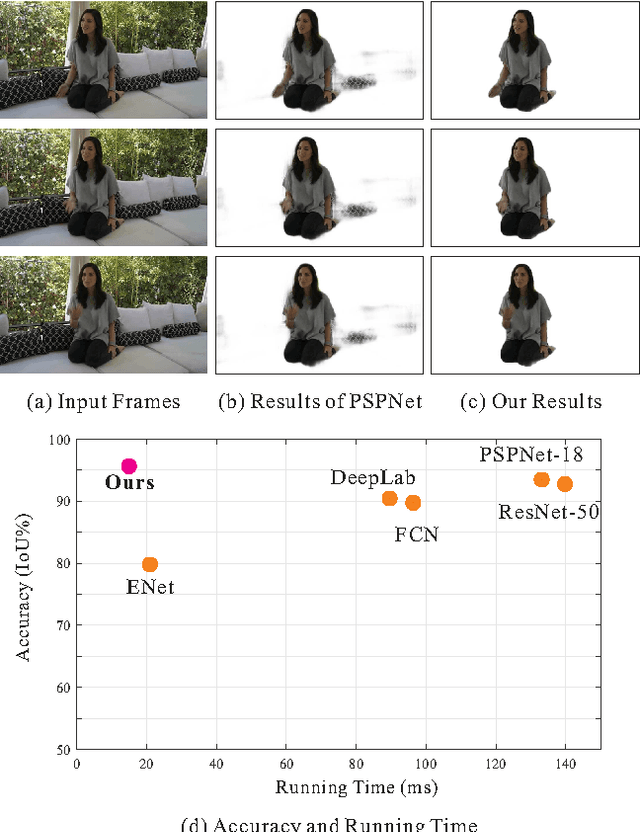
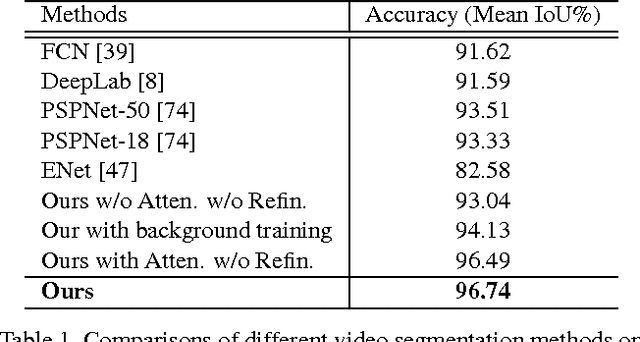


We in this paper solve the problem of high-quality automatic real-time background cut for 720p portrait videos. We first handle the background ambiguity issue in semantic segmentation by proposing a global background attenuation model. A spatial-temporal refinement network is developed to further refine the segmentation errors in each frame and ensure temporal coherence in the segmentation map. We form an end-to-end network for training and testing. Each module is designed considering efficiency and accuracy. We build a portrait dataset, which includes 8,000 images with high-quality labeled map for training and testing. To further improve the performance, we build a portrait video dataset with 50 sequences to fine-tune video segmentation. Our framework benefits many video processing applications.