 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdv-Diffusion: Imperceptible Adversarial Face Identity Attack via Latent Diffusion Model
Dec 28, 2023Adversarial attacks involve adding perturbations to the source image to cause misclassification by the target model, which demonstrates the potential of attacking face recognition models. Existing adversarial face image generation methods still can't achieve satisfactory performance because of low transferability and high detectability. In this paper, we propose a unified framework Adv-Diffusion that can generate imperceptible adversarial identity perturbations in the latent space but not the raw pixel space, which utilizes strong inpainting capabilities of the latent diffusion model to generate realistic adversarial images. Specifically, we propose the identity-sensitive conditioned diffusion generative model to generate semantic perturbations in the surroundings. The designed adaptive strength-based adversarial perturbation algorithm can ensure both attack transferability and stealthiness. Extensive qualitative and quantitative experiments on the public FFHQ and CelebA-HQ datasets prove the proposed method achieves superior performance compared with the state-of-the-art methods without an extra generative model training process. The source code is available at https://github.com/kopper-xdu/Adv-Diffusion.
Towards Generalizable Person Re-identification with a Bi-stream Generative Model
Jun 26, 2022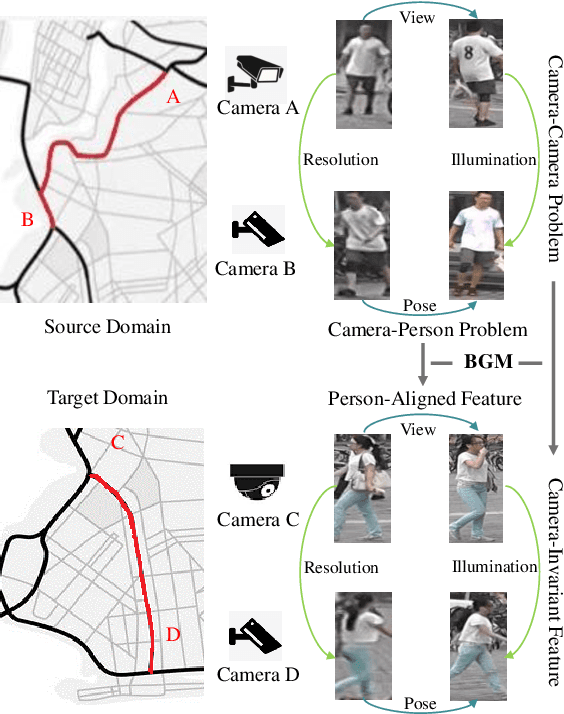
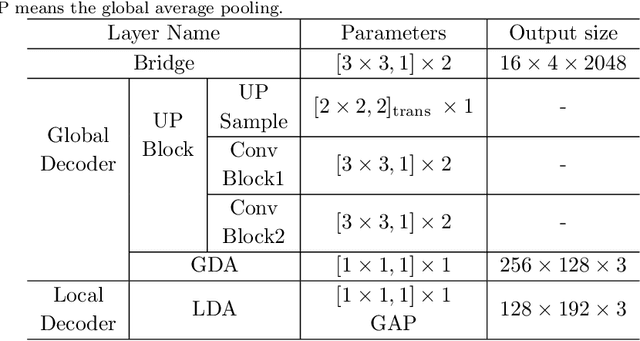
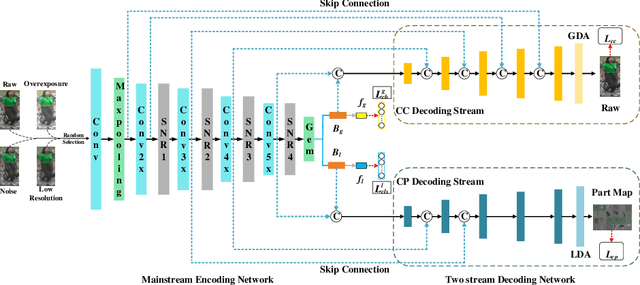
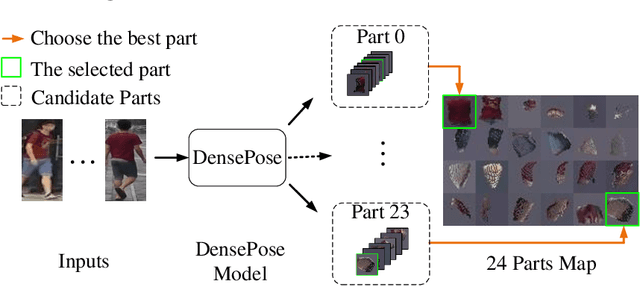
Generalizable person re-identification (re-ID) has attracted growing attention due to its powerful adaptation capability in the unseen data domain. However, existing solutions often neglect either crossing cameras (e.g., illumination and resolution differences) or pedestrian misalignments (e.g., viewpoint and pose discrepancies), which easily leads to poor generalization capability when adapted to the new domain. In this paper, we formulate these difficulties as: 1) Camera-Camera (CC) problem, which denotes the various human appearance changes caused by different cameras; 2) Camera-Person (CP) problem, which indicates the pedestrian misalignments caused by the same identity person under different camera viewpoints or changing pose. To solve the above issues, we propose a Bi-stream Generative Model (BGM) to learn the fine-grained representations fused with camera-invariant global feature and pedestrian-aligned local feature, which contains an encoding network and two stream decoding sub-networks. Guided by original pedestrian images, one stream is employed to learn a camera-invariant global feature for the CC problem via filtering cross-camera interference factors. For the CP problem, another stream learns a pedestrian-aligned local feature for pedestrian alignment using information-complete densely semantically aligned part maps. Moreover, a part-weighted loss function is presented to reduce the influence of missing parts on pedestrian alignment. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods on the large-scale generalizable re-ID benchmarks, involving domain generalization setting and cross-domain setting.