 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompress then Merge: From Multiple LoRAs into One Low-Rank Adapter
Jun 02, 2026Low-rank adaptation (LoRA) enables parameter-efficient specialization of foundation models, but the proliferation of task-specific adapters fragments capabilities across many adapters, complicating reuse and deployment. We study the problem of merging $T$ LoRAs into a single rank-$r$ LoRA, thereby preserving the benefits of low-rank structure. Existing Merge-then-Compress pipelines treat the rank constraint as an afterthought: they merge adapters in the full parameter space, then compress the merged result to rank $r$ via truncated SVD. However, full-parameter merging may destroy the low-rank structure, making it difficult for subsequent compression to recover an effective rank-$r$ LoRA. We propose Compress-then-Merge (CtM), a reversed pipeline that enforces the rank-$r$ bottleneck before merging: CtM computes shared $r$-dimensional subspaces using only the LoRA weights to capture cross-adapter common structure, projects each adapter into the shared subspaces to obtain $r\times r$ coordinates, and then applies standard merging rules in this reduced space. CtM guarantees a rank-$r$ LoRA by construction, avoiding post-hoc truncation, and enables efficient computation in the core space spanned by concatenated LoRA factors. Experiments across multiple models and tasks show that CtM consistently outperforms existing single-LoRA-output baselines while narrowing the performance gap to full-parameter merging methods.
Phasing Through the Flames: Rapid Motion Planning with the AGHF PDE for Arbitrary Objective Functions and Constraints
May 02, 2025The generation of optimal trajectories for high-dimensional robotic systems under constraints remains computationally challenging due to the need to simultaneously satisfy dynamic feasibility, input limits, and task-specific objectives while searching over high-dimensional spaces. Recent approaches using the Affine Geometric Heat Flow (AGHF) Partial Differential Equation (PDE) have demonstrated promising results, generating dynamically feasible trajectories for complex systems like the Digit V3 humanoid within seconds. These methods efficiently solve trajectory optimization problems over a two-dimensional domain by evolving an initial trajectory to minimize control effort. However, these AGHF approaches are limited to a single type of optimal control problem (i.e., minimizing the integral of squared control norms) and typically require initial guesses that satisfy constraints to ensure satisfactory convergence. These limitations restrict the potential utility of the AGHF PDE especially when trying to synthesize trajectories for robotic systems. This paper generalizes the AGHF formulation to accommodate arbitrary cost functions, significantly expanding the classes of trajectories that can be generated. This work also introduces a Phase1 - Phase 2 Algorithm that enables the use of constraint-violating initial guesses while guaranteeing satisfactory convergence. The effectiveness of the proposed method is demonstrated through comparative evaluations against state-of-the-art techniques across various dynamical systems and challenging trajectory generation problems. Project Page: https://roahmlab.github.io/BLAZE/
MUSO: Achieving Exact Machine Unlearning in Over-Parameterized Regimes
Oct 11, 2024
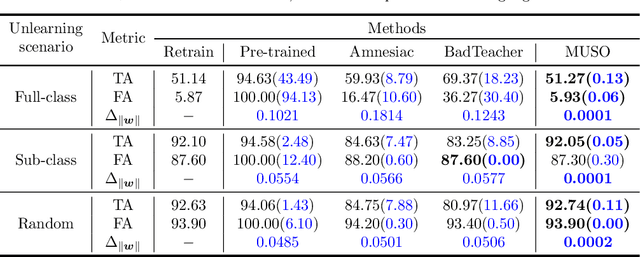
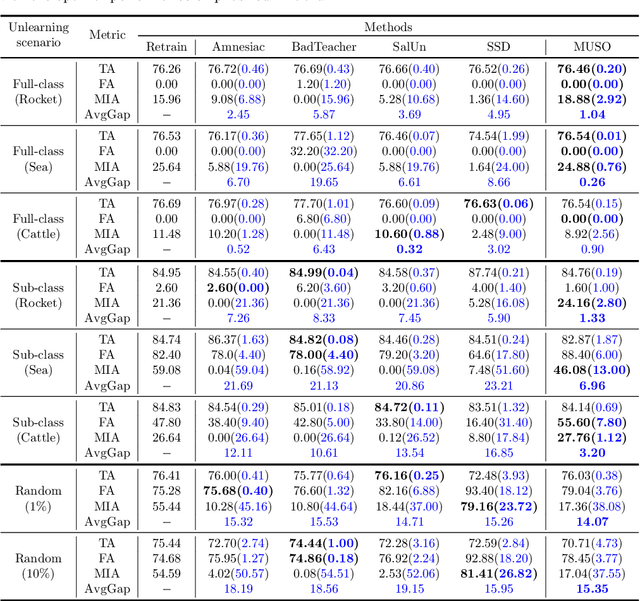
Machine unlearning (MU) is to make a well-trained model behave as if it had never been trained on specific data. In today's over-parameterized models, dominated by neural networks, a common approach is to manually relabel data and fine-tune the well-trained model. It can approximate the MU model in the output space, but the question remains whether it can achieve exact MU, i.e., in the parameter space. We answer this question by employing random feature techniques to construct an analytical framework. Under the premise of model optimization via stochastic gradient descent, we theoretically demonstrated that over-parameterized linear models can achieve exact MU through relabeling specific data. We also extend this work to real-world nonlinear networks and propose an alternating optimization algorithm that unifies the tasks of unlearning and relabeling. The algorithm's effectiveness, confirmed through numerical experiments, highlights its superior performance in unlearning across various scenarios compared to current state-of-the-art methods, particularly excelling over similar relabeling-based MU approaches.
Data Imputation by Pursuing Better Classification: A Supervised Kernel-Based Method
May 13, 2024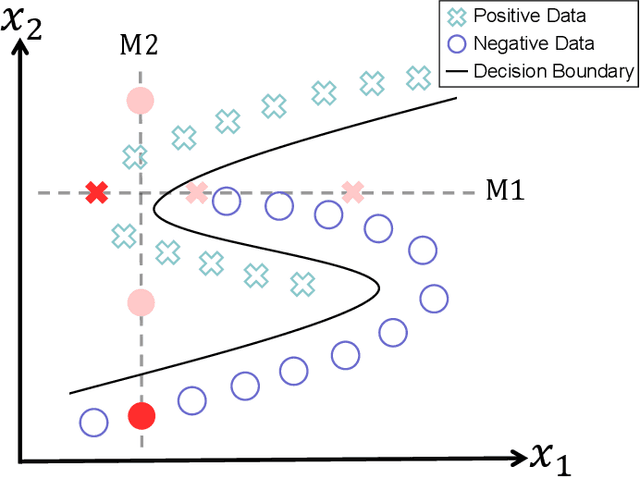
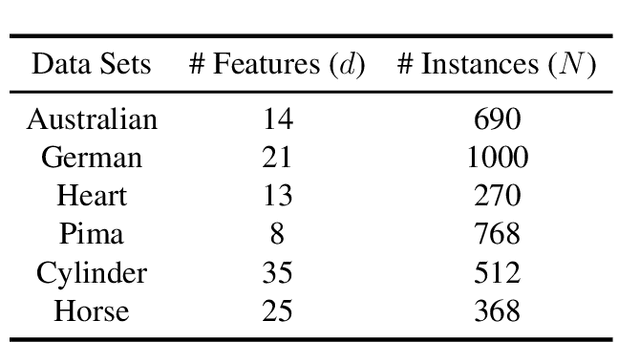

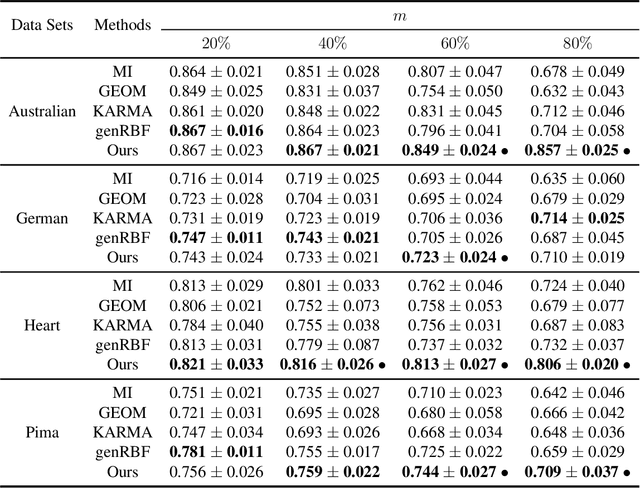
Data imputation, the process of filling in missing feature elements for incomplete data sets, plays a crucial role in data-driven learning. A fundamental belief is that data imputation is helpful for learning performance, and it follows that the pursuit of better classification can guide the data imputation process. While some works consider using label information to assist in this task, their simplistic utilization of labels lacks flexibility and may rely on strict assumptions. In this paper, we propose a new framework that effectively leverages supervision information to complete missing data in a manner conducive to classification. Specifically, this framework operates in two stages. Firstly, it leverages labels to supervise the optimization of similarity relationships among data, represented by the kernel matrix, with the goal of enhancing classification accuracy. To mitigate overfitting that may occur during this process, a perturbation variable is introduced to improve the robustness of the framework. Secondly, the learned kernel matrix serves as additional supervision information to guide data imputation through regression, utilizing the block coordinate descent method. The superiority of the proposed method is evaluated on four real-world data sets by comparing it with state-of-the-art imputation methods. Remarkably, our algorithm significantly outperforms other methods when the data is missing more than 60\% of the features
Decentralized Kernel Ridge Regression Based on Data-dependent Random Feature
May 13, 2024
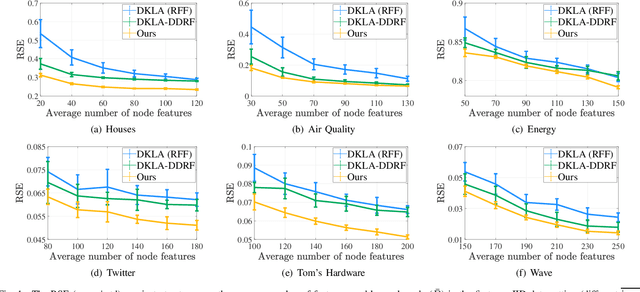
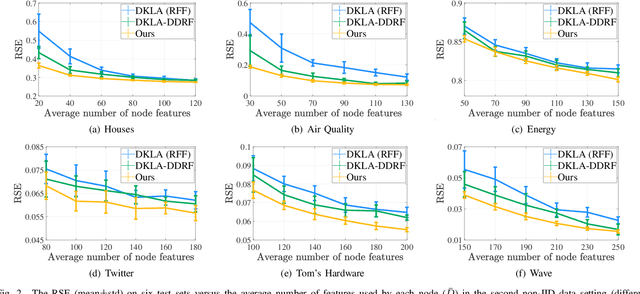
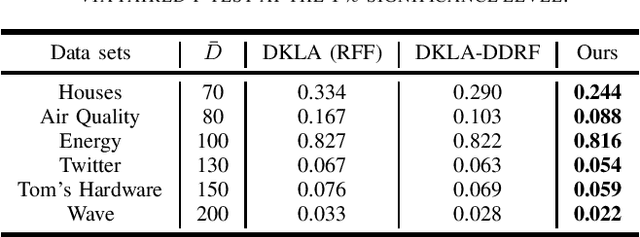
Random feature (RF) has been widely used for node consistency in decentralized kernel ridge regression (KRR). Currently, the consistency is guaranteed by imposing constraints on coefficients of features, necessitating that the random features on different nodes are identical. However, in many applications, data on different nodes varies significantly on the number or distribution, which calls for adaptive and data-dependent methods that generate different RFs. To tackle the essential difficulty, we propose a new decentralized KRR algorithm that pursues consensus on decision functions, which allows great flexibility and well adapts data on nodes. The convergence is rigorously given and the effectiveness is numerically verified: by capturing the characteristics of the data on each node, while maintaining the same communication costs as other methods, we achieved an average regression accuracy improvement of 25.5\% across six real-world data sets.