 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
Jun 01, 2026Deep-research agents solve tasks through long trajectories of search, tool use, evidence inspection, and answer synthesis. Evaluation based on final answers shows whether an agent succeeds, but not which parts of the trajectory make the answer unreliable. We study span-level error localization for deep-research agents. We collect 2,790 real trajectories from two agent frameworks, three backbone models, and three benchmarks, convert raw logs into semantic spans, and annotate harmful error spans through LLM-assisted expert review. From these annotations, we build TELBench, a 1,000-instance benchmark for identifying error spans among normal exploration, failed searches, tentative hypotheses, and harmless noise. We further propose DRIFT, a claim-centric auditing framework that tracks agent claims, checks their support in trajectory evidence, and marks spans where unsupported or conflicting claims affect the answer path. Experiments across model families and auditing frameworks show that DRIFT improves span-level error localization and first-error accuracy by up to 30 percentage points. Our work provides a process-level view of reliability in deep-research agents.
Zero-shot 3D Map Generation with LLM Agents: A Dual-Agent Architecture for Procedural Content Generation
Dec 12, 2025



Procedural Content Generation (PCG) offers scalable methods for algorithmically creating complex, customizable worlds. However, controlling these pipelines requires the precise configuration of opaque technical parameters. We propose a training-free architecture that utilizes LLM agents for zero-shot PCG parameter configuration. While Large Language Models (LLMs) promise a natural language interface for PCG tools, off-the-shelf models often fail to bridge the semantic gap between abstract user instructions and strict parameter specifications. Our system pairs an Actor agent with a Critic agent, enabling an iterative workflow where the system autonomously reasons over tool parameters and refines configurations to progressively align with human design preferences. We validate this approach on the generation of various 3D maps, establishing a new benchmark for instruction-following in PCG. Experiments demonstrate that our approach outperforms single-agent baselines, producing diverse and structurally valid environments from natural language descriptions. These results demonstrate that off-the-shelf LLMs can be effectively repurposed as generalized agents for arbitrary PCG tools. By shifting the burden from model training to architectural reasoning, our method offers a scalable framework for mastering complex software without task-specific fine-tuning.
LARP: Language-Agent Role Play for Open-World Games
Dec 24, 2023Language agents have shown impressive problem-solving skills within defined settings and brief timelines. Yet, with the ever-evolving complexities of open-world simulations, there's a pressing need for agents that can flexibly adapt to complex environments and consistently maintain a long-term memory to ensure coherent actions. To bridge the gap between language agents and open-world games, we introduce Language Agent for Role-Playing (LARP), which includes a cognitive architecture that encompasses memory processing and a decision-making assistant, an environment interaction module with a feedback-driven learnable action space, and a postprocessing method that promotes the alignment of various personalities. The LARP framework refines interactions between users and agents, predefined with unique backgrounds and personalities, ultimately enhancing the gaming experience in open-world contexts. Furthermore, it highlights the diverse uses of language models in a range of areas such as entertainment, education, and various simulation scenarios. The project page is released at https://miao-ai-lab.github.io/LARP/.
FA-Harris: A Fast and Asynchronous Corner Detector for Event Cameras
Aug 16, 2019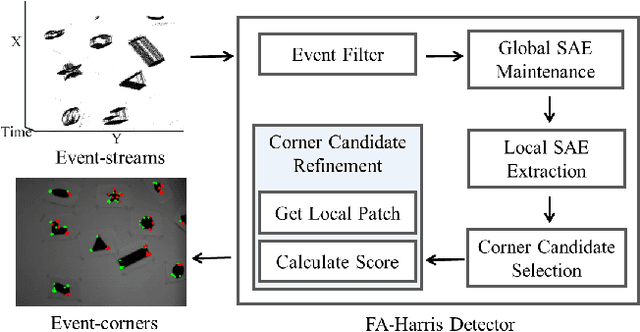
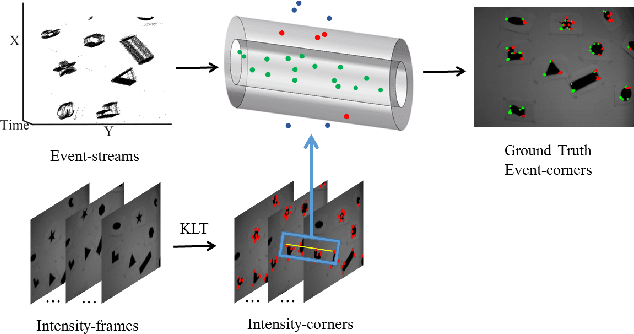

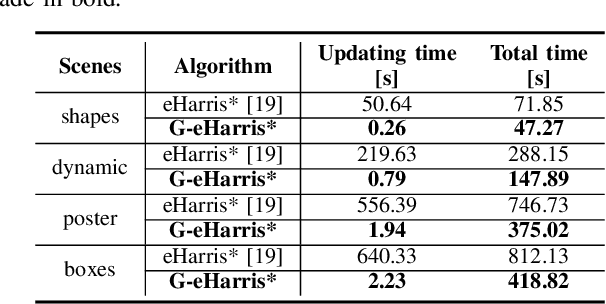
Recently, the emerging bio-inspired event cameras have demonstrated potentials for a wide range of robotic applications in dynamic environments. In this paper, we propose a novel fast and asynchronous event-based corner detection method which is called FA-Harris. FA-Harris consists of several components, including an event filter, a Global Surface of Active Events (G-SAE) maintaining unit, a corner candidate selecting unit, and a corner candidate refining unit. The proposed G-SAE maintenance algorithm and corner candidate selection algorithm greatly enhance the real-time performance for corner detection, while the corner candidate refinement algorithm maintains the accuracy of performance by using an improved event-based Harris detector. Additionally, FA-Harris does not require artificially synthesized event-frames and can operate on asynchronous events directly. We implement the proposed method in C++ and evaluate it on public Event Camera Datasets. The results show that our method achieves approximately 8x speed-up when compared with previously reported event-based Harris detector, and with no compromise on the accuracy of performance.
UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning
Feb 21, 2018

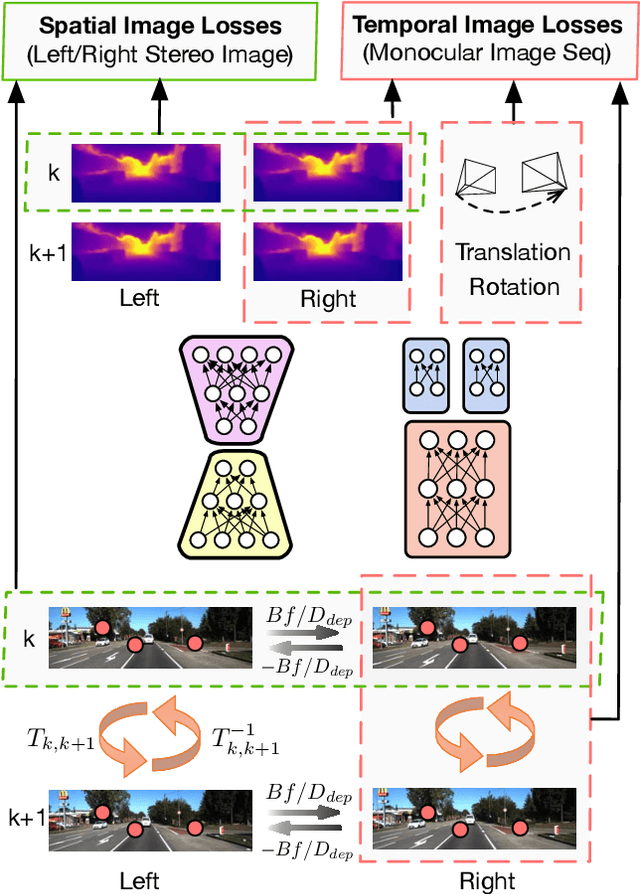
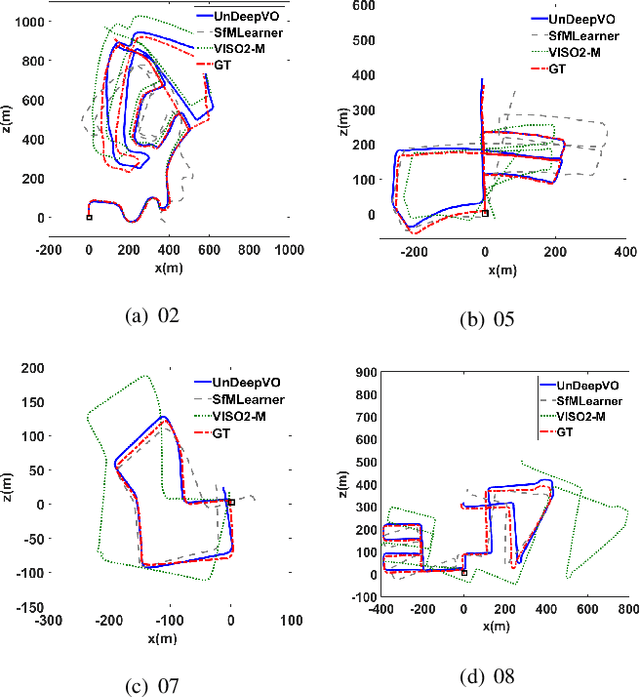
We propose a novel monocular visual odometry (VO) system called UnDeepVO in this paper. UnDeepVO is able to estimate the 6-DoF pose of a monocular camera and the depth of its view by using deep neural networks. There are two salient features of the proposed UnDeepVO: one is the unsupervised deep learning scheme, and the other is the absolute scale recovery. Specifically, we train UnDeepVO by using stereo image pairs to recover the scale but test it by using consecutive monocular images. Thus, UnDeepVO is a monocular system. The loss function defined for training the networks is based on spatial and temporal dense information. A system overview is shown in Fig. 1. The experiments on KITTI dataset show our UnDeepVO achieves good performance in terms of pose accuracy.