 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODE: Learning compositional representations of complex systems with Mixtures Of Dynamical Experts
Oct 10, 2025



Dynamical systems in the life sciences are often composed of complex mixtures of overlapping behavioral regimes. Cellular subpopulations may shift from cycling to equilibrium dynamics or branch towards different developmental fates. The transitions between these regimes can appear noisy and irregular, posing a serious challenge to traditional, flow-based modeling techniques which assume locally smooth dynamics. To address this challenge, we propose MODE (Mixture Of Dynamical Experts), a graphical modeling framework whose neural gating mechanism decomposes complex dynamics into sparse, interpretable components, enabling both the unsupervised discovery of behavioral regimes and accurate long-term forecasting across regime transitions. Crucially, because agents in our framework can jump to different governing laws, MODE is especially tailored to the aforementioned noisy transitions. We evaluate our method on a battery of synthetic and real datasets from computational biology. First, we systematically benchmark MODE on an unsupervised classification task using synthetic dynamical snapshot data, including in noisy, few-sample settings. Next, we show how MODE succeeds on challenging forecasting tasks which simulate key cycling and branching processes in cell biology. Finally, we deploy our method on human, single-cell RNA sequencing data and show that it can not only distinguish proliferation from differentiation dynamics but also predict when cells will commit to their ultimate fate, a key outstanding challenge in computational biology.
Characterizing Nonlinear Dynamics via Smooth Prototype Equivalences
Mar 13, 2025



Characterizing dynamical systems given limited measurements is a common challenge throughout the physical and biological sciences. However, this task is challenging, especially due to transient variability in systems with equivalent long-term dynamics. We address this by introducing smooth prototype equivalences (SPE), a framework that fits a diffeomorphism using normalizing flows to distinct prototypes - simplified dynamical systems that define equivalence classes of behavior. SPE enables classification by comparing the deformation loss of the observed sparse, high-dimensional measurements to the prototype dynamics. Furthermore, our approach enables estimation of the invariant sets of the observed dynamics through the learned mapping from prototype space to data space. Our method outperforms existing techniques in the classification of oscillatory systems and can efficiently identify invariant structures like limit cycles and fixed points in an equation-free manner, even when only a small, noisy subset of the phase space is observed. Finally, we show how our method can be used for the detection of biological processes like the cell cycle trajectory from high-dimensional single-cell gene expression data.
Control+Shift: Generating Controllable Distribution Shifts
Sep 12, 2024We propose a new method for generating realistic datasets with distribution shifts using any decoder-based generative model. Our approach systematically creates datasets with varying intensities of distribution shifts, facilitating a comprehensive analysis of model performance degradation. We then use these generated datasets to evaluate the performance of various commonly used networks and observe a consistent decline in performance with increasing shift intensity, even when the effect is almost perceptually unnoticeable to the human eye. We see this degradation even when using data augmentations. We also find that enlarging the training dataset beyond a certain point has no effect on the robustness and that stronger inductive biases increase robustness.
Intriguing Properties of Modern GANs
Feb 21, 2024Modern GANs achieve remarkable performance in terms of generating realistic and diverse samples. This has led many to believe that ``GANs capture the training data manifold''. In this work we show that this interpretation is wrong. We empirically show that the manifold learned by modern GANs does not fit the training distribution: specifically the manifold does not pass through the training examples and passes closer to out-of-distribution images than to in-distribution images. We also investigate the distribution over images implied by the prior over the latent codes and study whether modern GANs learn a density that approximates the training distribution. Surprisingly, we find that the learned density is very far from the data distribution and that GANs tend to assign higher density to out-of-distribution images. Finally, we demonstrate that the set of images used to train modern GANs are often not part of the typical set described by the GANs' distribution.
Posterior Sampling for Image Restoration using Explicit Patch Priors
Apr 20, 2021


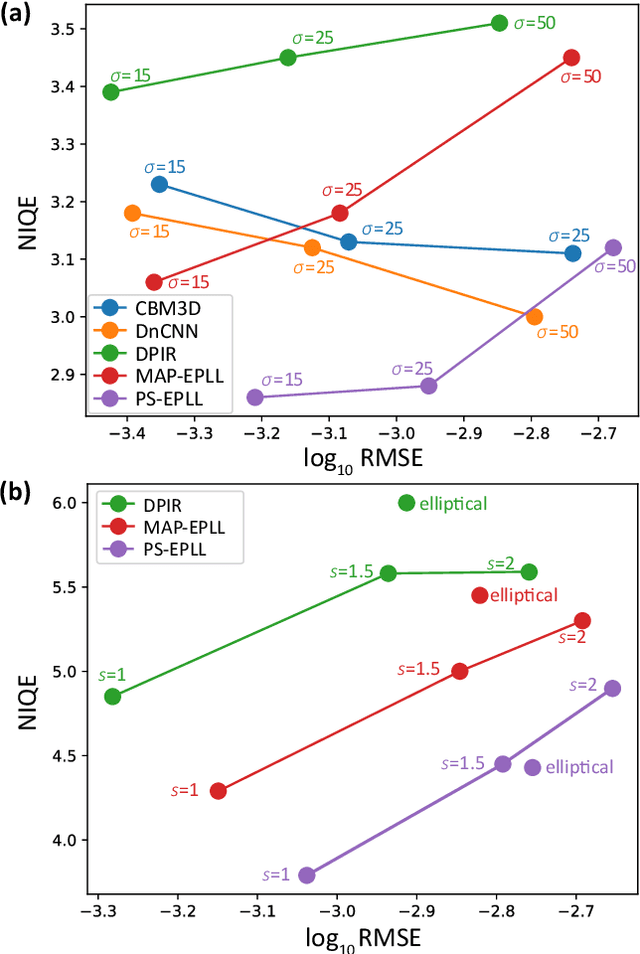
Almost all existing methods for image restoration are based on optimizing the mean squared error (MSE), even though it is known that the best estimate in terms of MSE may yield a highly atypical image due to the fact that there are many plausible restorations for a given noisy image. In this paper, we show how to combine explicit priors on patches of natural images in order to sample from the posterior probability of a full image given a degraded image. We prove that our algorithm generates correct samples from the distribution $p(x|y) \propto \exp(-E(x|y))$ where $E(x|y)$ is the cost function minimized in previous patch-based approaches that compute a single restoration. Unlike previous approaches that computed a single restoration using MAP or MMSE, our method makes explicit the uncertainty in the restored images and guarantees that all patches in the restored images will be typical given the patch prior. Unlike previous approaches that used implicit priors on fixed-size images, our approach can be used with images of any size. Our experimental results show that posterior sampling using patch priors yields images of high perceptual quality and high PSNR on a range of challenging image restoration problems.