 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeamTrack: A Dataset for Multi-Sport Multi-Object Tracking in Full-pitch Videos
Apr 22, 2024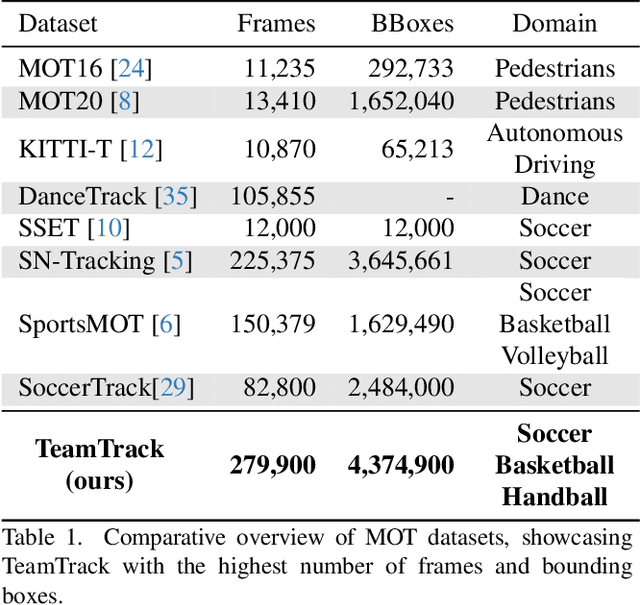

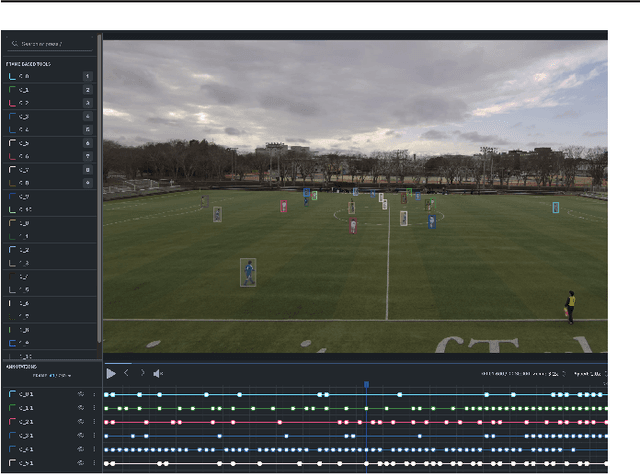
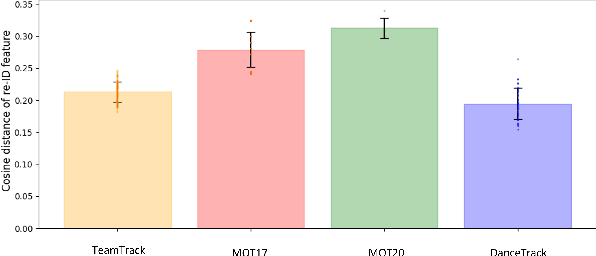
Multi-object tracking (MOT) is a critical and challenging task in computer vision, particularly in situations involving objects with similar appearances but diverse movements, as seen in team sports. Current methods, largely reliant on object detection and appearance, often fail to track targets in such complex scenarios accurately. This limitation is further exacerbated by the lack of comprehensive and diverse datasets covering the full view of sports pitches. Addressing these issues, we introduce TeamTrack, a pioneering benchmark dataset specifically designed for MOT in sports. TeamTrack is an extensive collection of full-pitch video data from various sports, including soccer, basketball, and handball. Furthermore, we perform a comprehensive analysis and benchmarking effort to underscore TeamTrack's utility and potential impact. Our work signifies a crucial step forward, promising to elevate the precision and effectiveness of MOT in complex, dynamic settings such as team sports. The dataset, project code and competition is released at: https://atomscott.github.io/TeamTrack/.
Machine Learning for Soccer Match Result Prediction
Mar 12, 2024
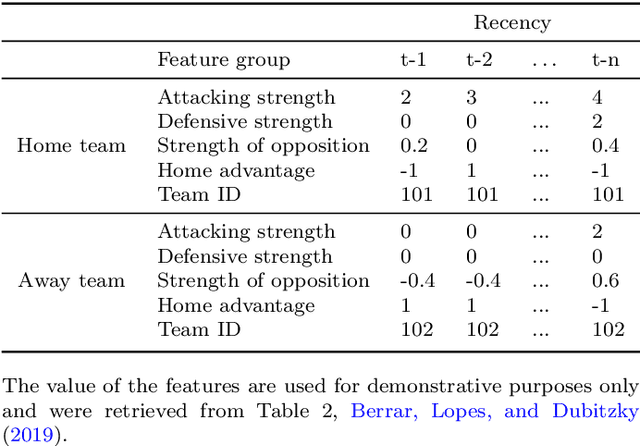
Machine learning has become a common approach to predicting the outcomes of soccer matches, and the body of literature in this domain has grown substantially in the past decade and a half. This chapter discusses available datasets, the types of models and features, and ways of evaluating model performance in this application domain. The aim of this chapter is to give a broad overview of the current state and potential future developments in machine learning for soccer match results prediction, as a resource for those interested in conducting future studies in the area. Our main findings are that while gradient-boosted tree models such as CatBoost, applied to soccer-specific ratings such as pi-ratings, are currently the best-performing models on datasets containing only goals as the match features, there needs to be a more thorough comparison of the performance of deep learning models and Random Forest on a range of datasets with different types of features. Furthermore, new rating systems using both player- and team-level information and incorporating additional information from, e.g., spatiotemporal tracking and event data, could be investigated further. Finally, the interpretability of match result prediction models needs to be enhanced for them to be more useful for team management.
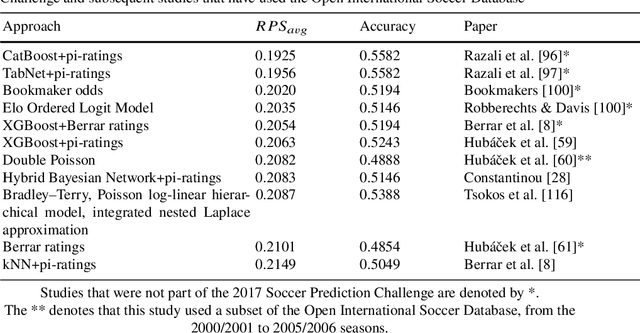
Evaluating Soccer Match Prediction Models: A Deep Learning Approach and Feature Optimization for Gradient-Boosted Trees
Sep 26, 2023


Machine learning models have become increasingly popular for predicting the results of soccer matches, however, the lack of publicly-available benchmark datasets has made model evaluation challenging. The 2023 Soccer Prediction Challenge required the prediction of match results first in terms of the exact goals scored by each team, and second, in terms of the probabilities for a win, draw, and loss. The original training set of matches and features, which was provided for the competition, was augmented with additional matches that were played between 4 April and 13 April 2023, representing the period after which the training set ended, but prior to the first matches that were to be predicted (upon which the performance was evaluated). A CatBoost model was employed using pi-ratings as the features, which were initially identified as the optimal choice for calculating the win/draw/loss probabilities. Notably, deep learning models have frequently been disregarded in this particular task. Therefore, in this study, we aimed to assess the performance of a deep learning model and determine the optimal feature set for a gradient-boosted tree model. The model was trained using the most recent five years of data, and three training and validation sets were used in a hyperparameter grid search. The results from the validation sets show that our model had strong performance and stability compared to previously published models from the 2017 Soccer Prediction Challenge for win/draw/loss prediction.
Supervised sequential pattern mining of event sequences in sport to identify important patterns of play: an application to rugby union
Oct 29, 2020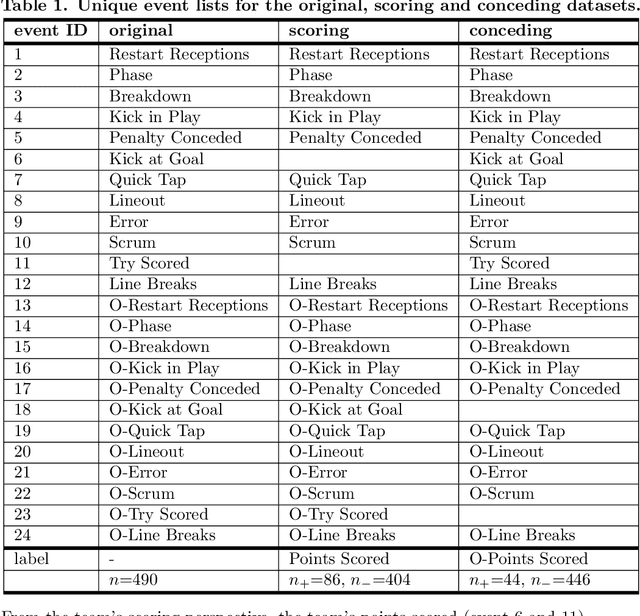
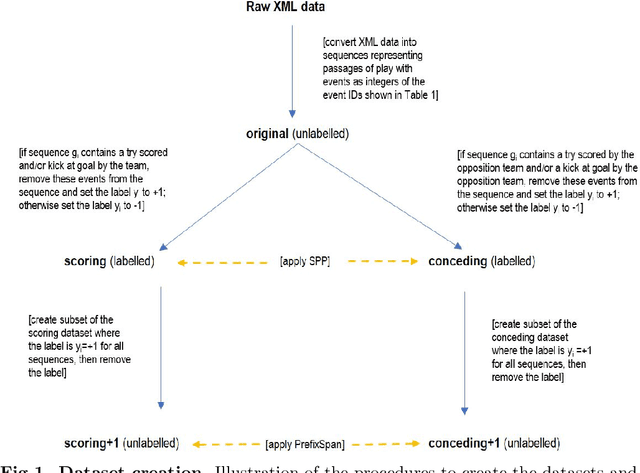
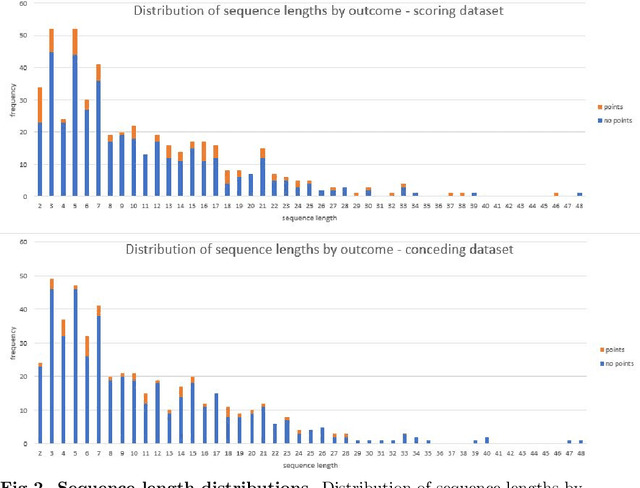
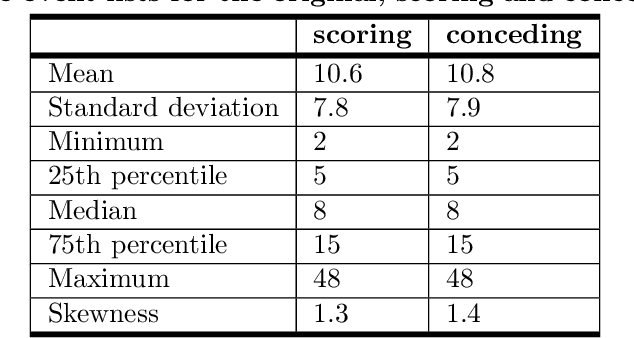
Given a set of sequences comprised of time-ordered events, sequential pattern mining is useful to identify frequent sub-sequences from different sequences or within the same sequence. However, in sport, these techniques cannot determine the importance of particular patterns of play to good or bad outcomes, which is often of greater interest to coaches. In this study, we apply a supervised sequential pattern mining algorithm called safe pattern pruning (SPP) to 490 labelled event sequences representing passages of play from one rugby team's matches from the 2018 Japan Top League, and then evaluate the importance of the obtained sub-sequences to points-scoring outcomes. Linebreaks, successful lineouts, regained kicks in play, repeated phase-breakdown play, and failed opposition exit plays were identified as important patterns of play for the team scoring. When sequences were labelled with points scoring outcomes for the opposition teams, opposition team linebreaks, errors made by the team, opposition team lineouts, and repeated phase-breakdown play by the opposition team were identified as important patterns of play for the opposition team scoring. By virtue of its supervised nature and pruning properties, SPP obtained a greater variety of generally more sophisticated patterns than the well-known unsupervised PrefixSpan algorithm.
The Application of Machine Learning Techniques for Predicting Results in Team Sport: A Review
Dec 26, 2019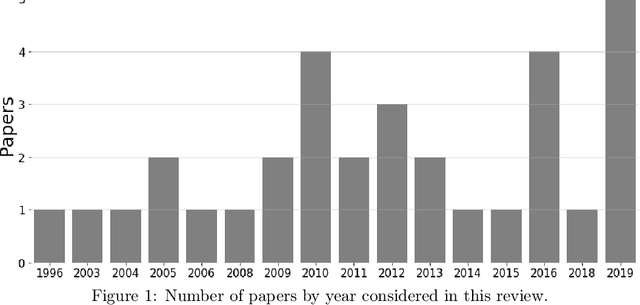
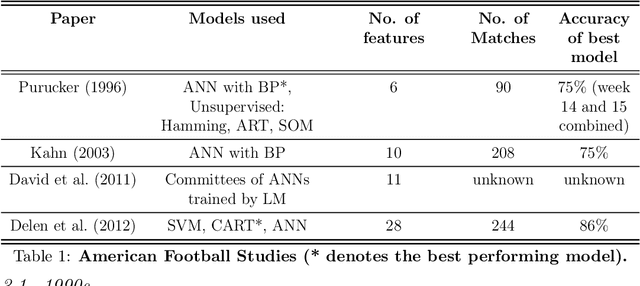
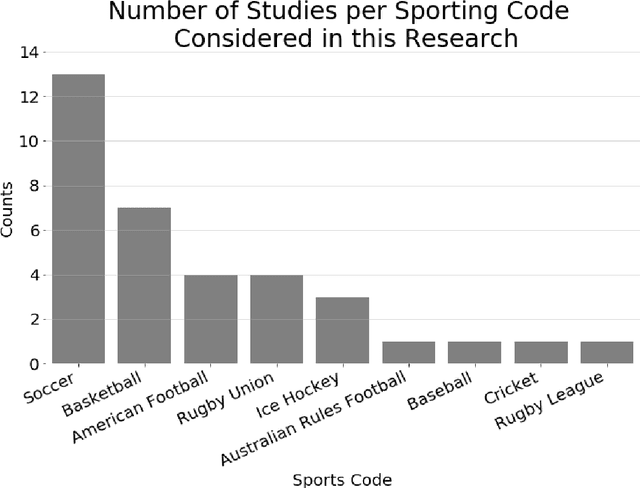
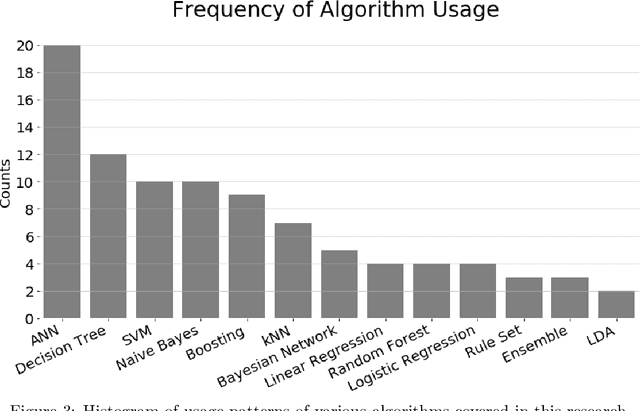
Over the past two decades, Machine Learning (ML) techniques have been increasingly utilized for the purpose of predicting outcomes in sport. In this paper, we provide a review of studies that have used ML for predicting results in team sport, covering studies from 1996 to 2019. We sought to answer five key research questions while extensively surveying papers in this field. This paper offers insights into which ML algorithms have tended to be used in this field, as well as those that are beginning to emerge with successful outcomes. Our research highlights defining characteristics of successful studies and identifies robust strategies for evaluating accuracy results in this application domain. Our study considers accuracies that have been achieved across different sports and explores the notion that outcomes of some team sports could be inherently more difficult to predict than others. Finally, our study uncovers common themes of future research directions across all surveyed papers, looking for gaps and opportunities, while proposing recommendations for future researchers in this domain.