 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Soccer Match Result Prediction
Paper and Code
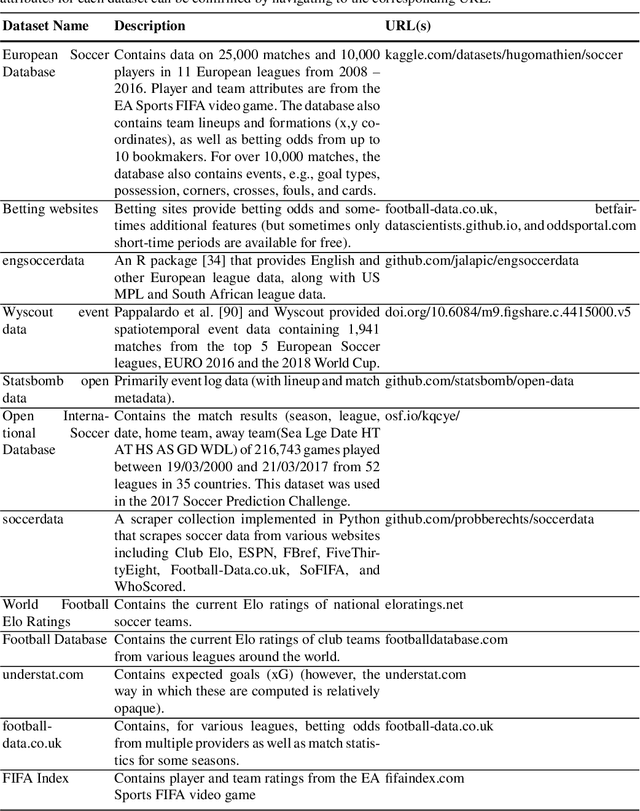
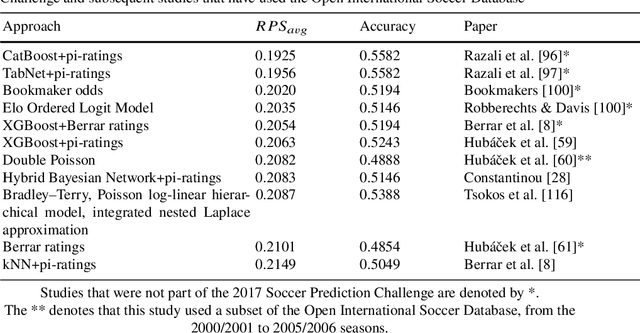
Machine learning has become a common approach to predicting the outcomes of soccer matches, and the body of literature in this domain has grown substantially in the past decade and a half. This chapter discusses available datasets, the types of models and features, and ways of evaluating model performance in this application domain. The aim of this chapter is to give a broad overview of the current state and potential future developments in machine learning for soccer match results prediction, as a resource for those interested in conducting future studies in the area. Our main findings are that while gradient-boosted tree models such as CatBoost, applied to soccer-specific ratings such as pi-ratings, are currently the best-performing models on datasets containing only goals as the match features, there needs to be a more thorough comparison of the performance of deep learning models and Random Forest on a range of datasets with different types of features. Furthermore, new rating systems using both player- and team-level information and incorporating additional information from, e.g., spatiotemporal tracking and event data, could be investigated further. Finally, the interpretability of match result prediction models needs to be enhanced for them to be more useful for team management.