 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing One-Shot Federated Learning Through Data and Ensemble Co-Boosting
Feb 23, 2024One-shot Federated Learning (OFL) has become a promising learning paradigm, enabling the training of a global server model via a single communication round. In OFL, the server model is aggregated by distilling knowledge from all client models (the ensemble), which are also responsible for synthesizing samples for distillation. In this regard, advanced works show that the performance of the server model is intrinsically related to the quality of the synthesized data and the ensemble model. To promote OFL, we introduce a novel framework, Co-Boosting, in which synthesized data and the ensemble model mutually enhance each other progressively. Specifically, Co-Boosting leverages the current ensemble model to synthesize higher-quality samples in an adversarial manner. These hard samples are then employed to promote the quality of the ensemble model by adjusting the ensembling weights for each client model. Consequently, Co-Boosting periodically achieves high-quality data and ensemble models. Extensive experiments demonstrate that Co-Boosting can substantially outperform existing baselines under various settings. Moreover, Co-Boosting eliminates the need for adjustments to the client's local training, requires no additional data or model transmission, and allows client models to have heterogeneous architectures.
DisPFL: Towards Communication-Efficient Personalized Federated Learning via Decentralized Sparse Training
Jun 01, 2022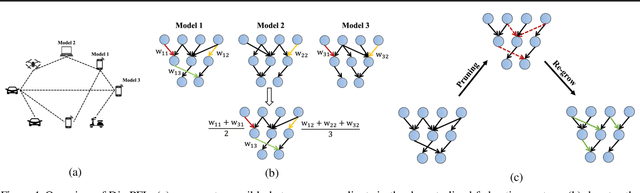
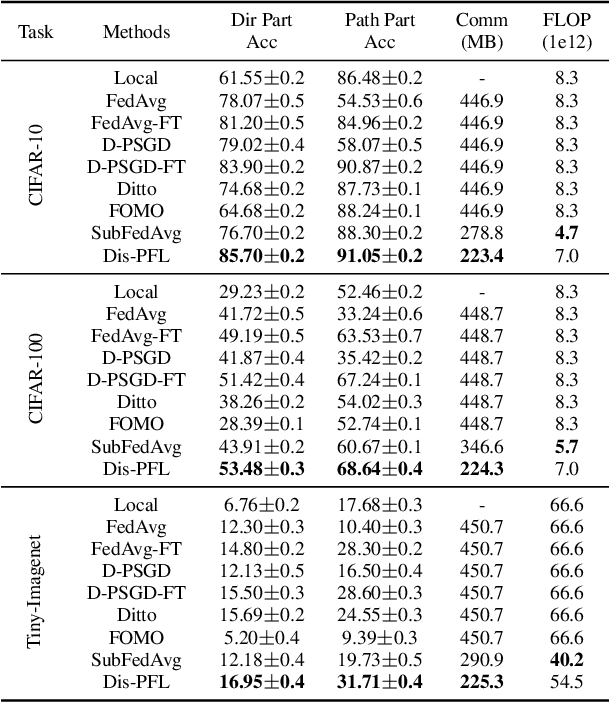
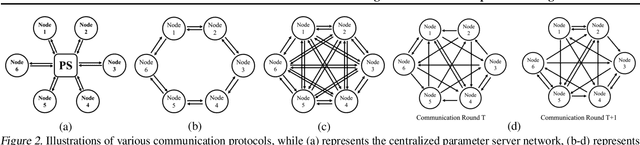
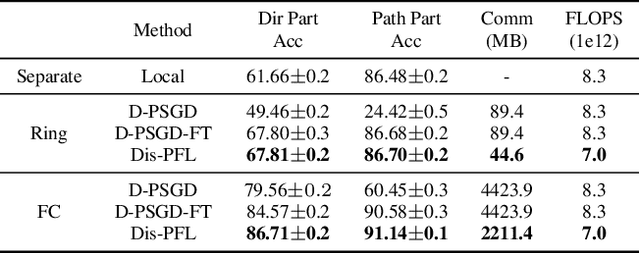
Personalized federated learning is proposed to handle the data heterogeneity problem amongst clients by learning dedicated tailored local models for each user. However, existing works are often built in a centralized way, leading to high communication pressure and high vulnerability when a failure or an attack on the central server occurs. In this work, we propose a novel personalized federated learning framework in a decentralized (peer-to-peer) communication protocol named Dis-PFL, which employs personalized sparse masks to customize sparse local models on the edge. To further save the communication and computation cost, we propose a decentralized sparse training technique, which means that each local model in Dis-PFL only maintains a fixed number of active parameters throughout the whole local training and peer-to-peer communication process. Comprehensive experiments demonstrate that Dis-PFL significantly saves the communication bottleneck for the busiest node among all clients and, at the same time, achieves higher model accuracy with less computation cost and communication rounds. Furthermore, we demonstrate that our method can easily adapt to heterogeneous local clients with varying computation complexities and achieves better personalized performances.