 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoRace: Winning Champion-Level Drone Racing with Robust Monocular AI
Jan 21, 2026Autonomous drone racing represents a major frontier in robotics research. It requires an Artificial Intelligence (AI) that can run on board light-weight flying robots under tight resource and time constraints, while pushing the physical system to its limits. The state of the art in this area consists of a system with a stereo camera and an inertial measurement unit (IMU) that beat human drone racing champions in a controlled indoor environment. Here, we present MonoRace: an onboard drone racing approach that uses a monocular, rolling-shutter camera and IMU that generalizes to a competition environment without any external motion tracking system. The approach features robust state estimation that combines neural-network-based gate segmentation with a drone model. Moreover, it includes an offline optimization procedure that leverages the known geometry of gates to refine any state estimation parameter. This offline optimization is based purely on onboard flight data and is important for fine-tuning the vital external camera calibration parameters. Furthermore, the guidance and control are performed by a neural network that foregoes inner loop controllers by directly sending motor commands. This small network runs on the flight controller at 500Hz. The proposed approach won the 2025 Abu Dhabi Autonomous Drone Racing Competition (A2RL), outperforming all competing AI teams and three human world champion pilots in a direct knockout tournament. It set a new milestone in autonomous drone racing research, reaching speeds up to 100 km/h on the competition track and successfully coping with problems such as camera interference and IMU saturation.
One Net to Rule Them All: Domain Randomization in Quadcopter Racing Across Different Platforms
Apr 30, 2025



In high-speed quadcopter racing, finding a single controller that works well across different platforms remains challenging. This work presents the first neural network controller for drone racing that generalizes across physically distinct quadcopters. We demonstrate that a single network, trained with domain randomization, can robustly control various types of quadcopters. The network relies solely on the current state to directly compute motor commands. The effectiveness of this generalized controller is validated through real-world tests on two substantially different crafts (3-inch and 5-inch race quadcopters). We further compare the performance of this generalized controller with controllers specifically trained for the 3-inch and 5-inch drone, using their identified model parameters with varying levels of domain randomization (0%, 10%, 20%, 30%). While the generalized controller shows slightly slower speeds compared to the fine-tuned models, it excels in adaptability across different platforms. Our results show that no randomization fails sim-to-real transfer while increasing randomization improves robustness but reduces speed. Despite this trade-off, our findings highlight the potential of domain randomization for generalizing controllers, paving the way for universal AI controllers that can adapt to any platform.
End-to-end Reinforcement Learning for Time-Optimal Quadcopter Flight
Nov 28, 2023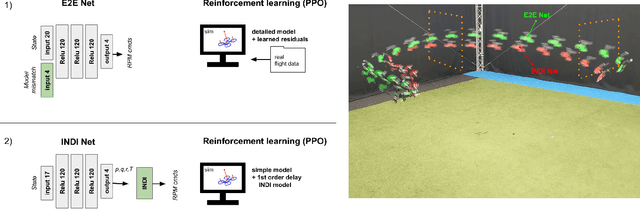
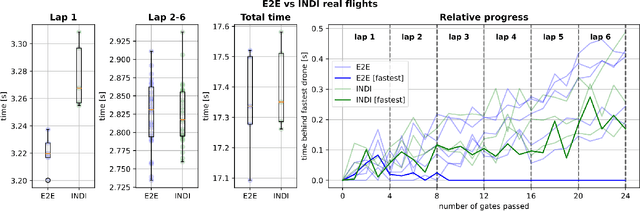
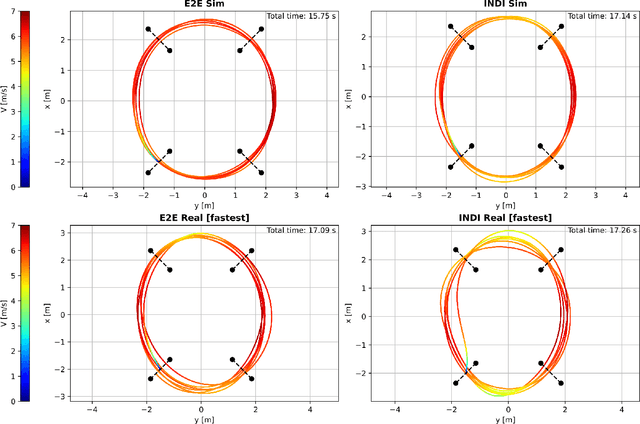
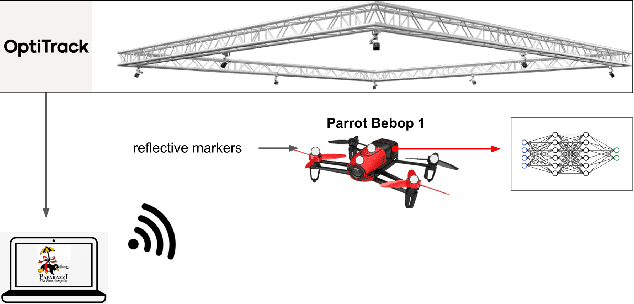
Aggressive time-optimal control of quadcopters poses a significant challenge in the field of robotics. The state-of-the-art approach leverages reinforcement learning (RL) to train optimal neural policies. However, a critical hurdle is the sim-to-real gap, often addressed by employing a robust inner loop controller -an abstraction that, in theory, constrains the optimality of the trained controller, necessitating margins to counter potential disturbances. In contrast, our novel approach introduces high-speed quadcopter control using end-to-end RL (E2E) that gives direct motor commands. To bridge the reality gap, we incorporate a learned residual model and an adaptive method that can compensate for modeling errors in thrust and moments. We compare our E2E approach against a state-of-the-art network that commands thrust and body rates to an INDI inner loop controller, both in simulated and real-world flight. E2E showcases a significant 1.39-second advantage in simulation and a 0.17-second edge in real-world testing, highlighting end-to-end reinforcement learning's potential. The performance drop observed from simulation to reality shows potential for further improvement, including refining strategies to address the reality gap or exploring offline reinforcement learning with real flight data.
Optimality Principles in Spacecraft Neural Guidance and Control
May 22, 2023Spacecraft and drones aimed at exploring our solar system are designed to operate in conditions where the smart use of onboard resources is vital to the success or failure of the mission. Sensorimotor actions are thus often derived from high-level, quantifiable, optimality principles assigned to each task, utilizing consolidated tools in optimal control theory. The planned actions are derived on the ground and transferred onboard where controllers have the task of tracking the uploaded guidance profile. Here we argue that end-to-end neural guidance and control architectures (here called G&CNets) allow transferring onboard the burden of acting upon these optimality principles. In this way, the sensor information is transformed in real time into optimal plans thus increasing the mission autonomy and robustness. We discuss the main results obtained in training such neural architectures in simulation for interplanetary transfers, landings and close proximity operations, highlighting the successful learning of optimality principles by the neural model. We then suggest drone racing as an ideal gym environment to test these architectures on real robotic platforms, thus increasing confidence in their utilization on future space exploration missions. Drone racing shares with spacecraft missions both limited onboard computational capabilities and similar control structures induced from the optimality principle sought, but it also entails different levels of uncertainties and unmodelled effects. Furthermore, the success of G&CNets on extremely resource-restricted drones illustrates their potential to bring real-time optimal control within reach of a wider variety of robotic systems, both in space and on Earth.
Guidance & Control Networks for Time-Optimal Quadcopter Flight
May 04, 2023



Reaching fast and autonomous flight requires computationally efficient and robust algorithms. To this end, we train Guidance & Control Networks to approximate optimal control policies ranging from energy-optimal to time-optimal flight. We show that the policies become more difficult to learn the closer we get to the time-optimal 'bang-bang' control profile. We also assess the importance of knowing the maximum angular rotor velocity of the quadcopter and show that over- or underestimating this limit leads to less robust flight. We propose an algorithm to identify the current maximum angular rotor velocity onboard and a network that adapts its policy based on the identified limit. Finally, we extend previous work on Guidance & Control Networks by learning to take consecutive waypoints into account. We fly a 4x3m track in similar lap times as the differential-flatness-based minimum snap benchmark controller while benefiting from the flexibility that Guidance & Control Networks offer.
An Adaptive Control Strategy for Neural Network based Optimal Quadcopter Controllers
Apr 26, 2023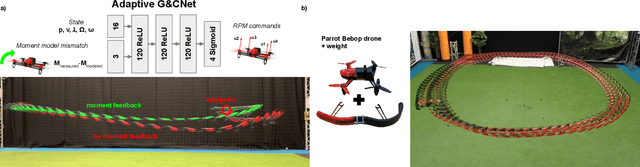


Developing optimal controllers for aggressive high-speed quadcopter flight is a major challenge in the field of robotics. Recent work has shown that neural networks trained with supervised learning can achieve real-time optimal control in some specific scenarios. In these methods, the networks (termed G&CNets) are trained to learn the optimal state feedback from a dataset of optimal trajectories. An important problem with these methods is the reality gap encountered in the sim-to-real transfer. In this work, we trained G&CNets for energy-optimal end-to-end control on the Bebop drone and identified the unmodeled pitch moment as the main contributor to the reality gap. To mitigate this, we propose an adaptive control strategy that works by learning from optimal trajectories of a system affected by constant external pitch, roll and yaw moments. In real test flights, this model mismatch is estimated onboard and fed to the network to obtain the optimal rpm command. We demonstrate the effectiveness of our method by performing energy-optimal hover-to-hover flights with and without moment feedback. Finally, we compare the adaptive controller to a state-of-the-art differential-flatness-based controller in a consecutive waypoint flight and demonstrate the advantages of our method in terms of energy optimality and robustness.