 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Reinforcement Learning for Time-Optimal Quadcopter Flight
Paper and Code
Nov 28, 2023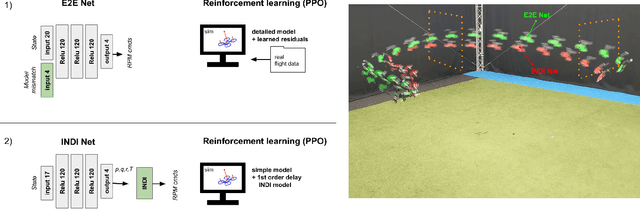
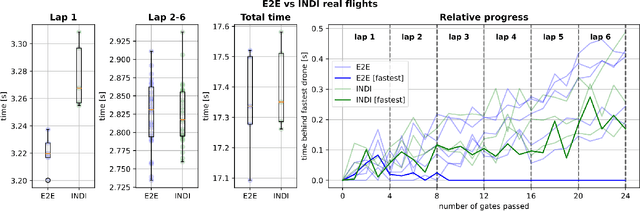
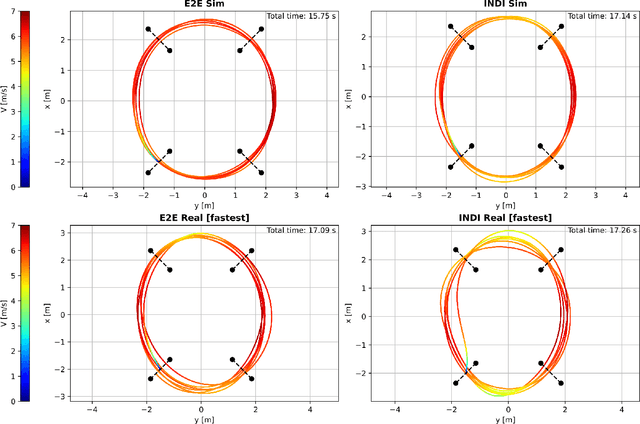
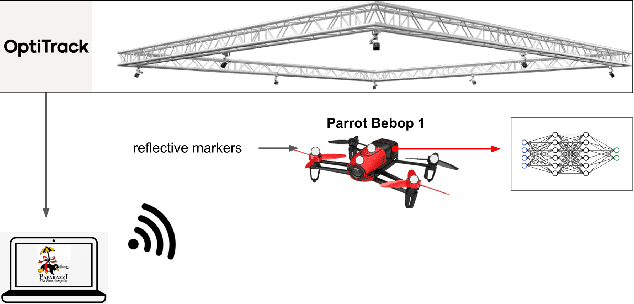
Aggressive time-optimal control of quadcopters poses a significant challenge in the field of robotics. The state-of-the-art approach leverages reinforcement learning (RL) to train optimal neural policies. However, a critical hurdle is the sim-to-real gap, often addressed by employing a robust inner loop controller -an abstraction that, in theory, constrains the optimality of the trained controller, necessitating margins to counter potential disturbances. In contrast, our novel approach introduces high-speed quadcopter control using end-to-end RL (E2E) that gives direct motor commands. To bridge the reality gap, we incorporate a learned residual model and an adaptive method that can compensate for modeling errors in thrust and moments. We compare our E2E approach against a state-of-the-art network that commands thrust and body rates to an INDI inner loop controller, both in simulated and real-world flight. E2E showcases a significant 1.39-second advantage in simulation and a 0.17-second edge in real-world testing, highlighting end-to-end reinforcement learning's potential. The performance drop observed from simulation to reality shows potential for further improvement, including refining strategies to address the reality gap or exploring offline reinforcement learning with real flight data.