 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA functional mirror ascent view of policy gradient methods with function approximation
Aug 12, 2021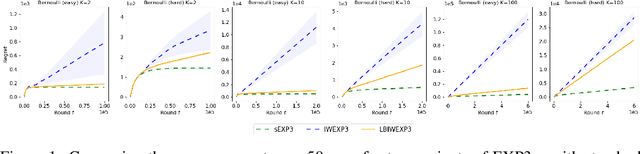
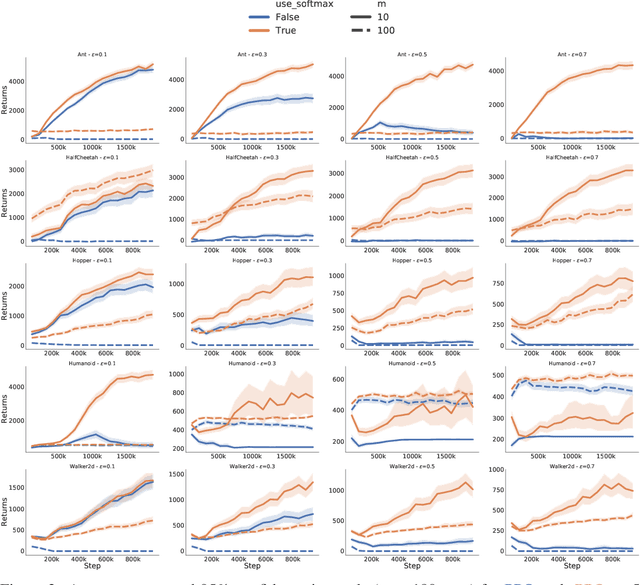

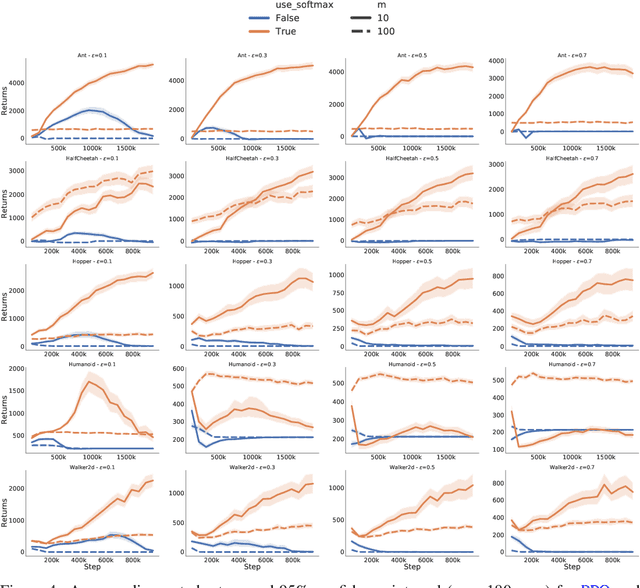
We use functional mirror ascent to propose a general framework (referred to as FMA-PG) for designing policy gradient methods. The functional perspective distinguishes between a policy's functional representation (what are its sufficient statistics) and its parameterization (how are these statistics represented) and naturally results in computationally efficient off-policy updates. For simple policy parameterizations, the FMA-PG framework ensures that the optimal policy is a fixed point of the updates. It also allows us to handle complex policy parameterizations (e.g., neural networks) while guaranteeing policy improvement. Our framework unifies several PG methods and opens the way for designing sample-efficient variants of existing methods. Moreover, it recovers important implementation heuristics (e.g., using forward vs reverse KL divergence) in a principled way. With a softmax functional representation, FMA-PG results in a variant of TRPO with additional desirable properties. It also suggests an improved variant of PPO, whose robustness and efficiency we empirically demonstrate on MuJoCo. Via experiments on simple reinforcement learning problems, we evaluate algorithms instantiated by FMA-PG.